감으로만 일하던 김팀장은 어떻게 데이터 좀 아는 팀장이 되었나
- 추론도 두 가지로 나눌 수 있어요. 직관에 의한 추론과 데이터 분석에 근거한 추론으로요. 직관에 의한 추론을 상식이나 감이라고 얘기할 수 있습니다. 예를 들어 유동인구가 많은 지역은 임대료가 높을 겁니다. 명 동이나 강남역의 임대료를 지방 소도시의 임대료와 비교하면 금방 알 수 있죠. 또한 유동인구가 많으면 그 지역 매장의 매출도 높을 겁니다. 하지만 모두 그런 것은 아닙니다. 최고급 호텔 쇼핑 아케이드는 오가는 사람이 별로 없어도 웬만한 상권보다 임대료가 높습니다. 유동인구는 적지만 지나가는 사람의 소비액이 크기 때문에 임대료가 높아요. 상식 이나 감이 맞을 확률이 높긴 하지만 틀린 경우도 있는 거예요. 여기서 더 나아가보죠. 유동인구가 10% 늘면 임대료는 얼마나 오를 까요? 매출액은 몇 % 증가할까요? 상식이나 감으로는 이 질문에 정 확하게 답할 수 없어요. 직관에 의한 추론만으로는 비즈니스를 합리적으로 추진할 수가 없습니다.
- R-Square(알스퀘어)라고 쓰여 있는 결정계수 R를 봐야 합니다. p-value는 모형을 신뢰해도 되는지 확인할 때 필요했죠. R는 이 모형이 전체 현상을 얼마나 설명하는지를 얘기해 줍니다. 이 표에서 R가 0.6472라는 것은 이 모형이 전체 현상을 64.72% 설명한다는 뜻이에요. 예를 들어 우리가 매출에 영향을 미치는 요인을 5개 선정해서 모형을 만들었다고 생각해보죠. 이 모형이 5개 요인을 통해 매출에 영향을 미치는 전체 요인 중 64.72%를 설명한다는 뜻입니다.
- 수정 결정계수라고 번역하는 어드저스티드 알스퀘어 Adj R2입니다. Adj는 Adjusted의 약자이고요. 그렇다면 무엇에 대한 수정인지 알면 되겠죠. 우선 이런 예를 생각해봅시다. 매장의 매출에 영향을 주는 요 인으로는 유동인구, 직원 수, 서비스 만족도, 화장실 개수, 세면대 수 등 매우 많습니다. 수백 가지가 될 수도 있어요. 만약 이렇게 매출에
영향을 주는 요인 수백 가지를 사용해서 매출을 분석하면 결과가 더 정확하겠죠. 하지만 모형은 엄청나게 복잡할 겁니다. 만약 요인을 서너 가지로 한정하면 매출을 정확하게 분석하지는 못하겠지만 모형은 간단하겠죠. 수정 결정계수는 지나치게 많은 요인을 사용해서 모형을 만들 경우 설명력이 높아지는 현상을 보완하기 위해 만들어낸 지표입니다. 그래 서 Adj R2는 요인이 2개 이상일 때부터 R2보다 조금씩 작아집니다. 그런데 실무에서는 두 값에 큰 차이가 없기 때문에 어떤 값을 봐도 큰 상관은 없습니다. 요인이 많을수록 두 값의 차이가 커지지만, 실무에 서는 10개가 넘는 요인을 고려하는 경우가 드물어요.
- Pr>It|가 개별 요인의 p-value 입니다. 보는 방법은 모형의 p-value와 같아요. 개별 요인의 p-value 가 0.05 보다 작으면 그 요인이 결과에 유의한 영향을 미친다고 해석합 니다. 예를 들어 매출에 영향을 미친다고 판단해서 수집한 요인이 10개 가 있다고 가정해보죠. 그중에서 어떤 요인은 매출에 실제로 영향을 미치고, 어떤 요인은 매출에 영향을 주지 못할 겁니다. 표에서 보면 매장 크기 Store Size 와 직원 친절도 Staff의 p-value는 0.05 보다 작기 때문 에 이 두 요인은 매출에 유의한 영향을 준다고 말할 수 있습니다. 그러나 주차장 면수Parking Lot를 보면 p-value가 0.6399이죠. 주차장 면수의 p-value는 0.05 보다 크기 때문에 매출에 영향을 준다고 볼 수 없어요.
- Parameter Estimate는 계수Coefficient라고 부르면 됩니다. 다른 요인이 통제된 상황에서 A가 한 단위 증가할 때 B가 몇 단위 증가하는지를 보여주는 값이에요. 예를 들어 매장 크기가 한 단위 증가할 때 매출이 얼마나 증가하는지를 보여주는 것이 계수죠. 만약 매장 크기 단위가 m2이고 매출 단위가 억 원이라고 가정해보죠. 이때 계수가 2라면, 매장 크기가 1m2 증가할 때 매출이 2억 원 증가 한다는 겁니다. 매장 크기가 10m2 늘어나면 매출은 20억 원이 증가하겠죠.
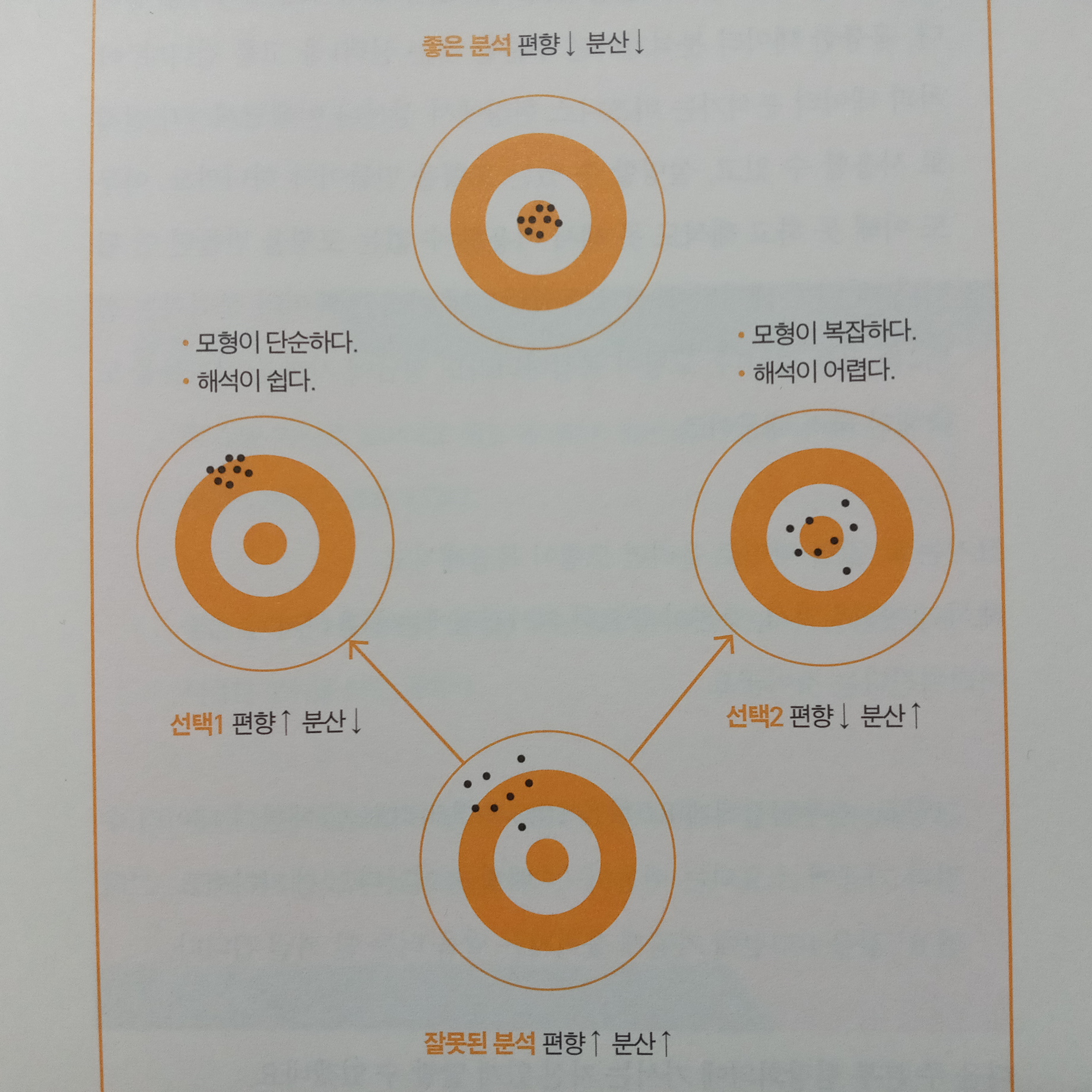
* R 값을 억지로 높이려고 해도 데이터가 없거나, 가성비가 나쁘거나, 해석하기 어려운 경우가 많다.
* 좋은 분석은 100점짜리 분석을 하는 것이 아니라 비즈니스 상황에 맞게 적절한 분석을 하는 것이다.
* 데이터 분석을 잘못 이해하는 사람에게 정확하고 적절하게 설명하는 것도 데이터 분석에서 중요한 일이다.
- 선형 회귀를 할 때 중요한 가정이 하나 있습니다. 독립변수가 2개 이상일 경우 독립변수 사이에 선형 상관관계가 존재하지 않아야 한다는 겁니다. 두 독립변수 사이에 선형 상관관계가 존재하지 않는다는 것은 두 독 립변수가 서로 정비례하거나 반비례하는 관계가 아니라는 뜻입니다. 데이터가 존재하는 패턴이 일정하지 않아서 직선을 그을 수 없는 경 우죠. 이때 상관계수를 산출하면 0에 가깝게 나옵니다. 반대로 두 독 립변수 사이에 선형 상관관계가 있다면 두 변수가 정비례하거나 반비례한다는 뜻이겠죠. 이때 상관계수는 1 또는 -1에 가까운 숫자가 나옵니다.
- 독립변수 간에 선형 상관관계가 존재하는 경우 다중공선성Multicollinearity이 있다고 얘기합니다. 다중(多重)은 독립변수가 2개 이상 일 때 쓰는 말이라고 했죠. 공선(共線)은 선이 하나라는 뜻입니다. 즉 독립변수가 같은 선을 지난다고 생각하면 됩니다. 다중공선성이 있으면 독립변수 간에 선형 상관관계가 있어서 회귀계 수의 분산이 커집니다. 분석 결과가 불안정하게 되어 분석의 효과성 이 감소하는 문제가 발생하죠. 이 문제를 파악하려면 산점도를 그려 야 합니다. 원래 데이터 분석을 하기 전에 변수 간 관계를 산점도를 통해 눈으로 파악해야 해요.
- 더욱 구체적인 판단을 위해 회귀 분석 과정에서 분산팽창요인 Variance Iniation Factor; VIF 을 추가합니다. 일반적으로 분산팽창요인이 10보다 크 면 다중공선성 문제가 있다고 봅니다. 다음 표를 보면 맨 오른쪽에 Variance Infation 값이 보이죠. VIF가 다 10이 넘네요. 그렇다고 한 번에 변수를 빼는 것은 아닙니다. 일단 중요하지 않은 독 립변수를 하나씩 빼면서 다시 계산하고, 다중공선성 문제를 확인해야 합니다. 중요하지 않은 변수가 무엇인지는 현업 부서와 데이터 분석 가가 논의해서 결정해야 합니다. 물론 소프트웨어에서 자동으로 변수를 뺄 수도 있지만요.
- 결괏값이 범주형으로 나오는 경우에 사용하는 분류 방법론도 여러 가지가 있습니다. 로지스틱 회귀 Logistic Regression, 판별 분석 Discriminant Analysis, 서포트 벡터 머신 Support Vector Machine , 의사결정나무 Decision Tree , k-최근접이웃k-NearestNeighbors 등이 있어요.
- 로지스틱 회귀에 회귀란 단어가 들어간 이유는 이 방법론이 결팟값을 회귀식으로 보여주기 때문이에요. 실제로 보시면 결과식이 선형 회귀식과 비슷하게 나옵니다. 선형 회귀에서 결맛값이 0보다 작거나 1보다 크면 아까 서초지점장이 얘기했던 문제가 생기잖아요. 그래서 0 미만과 1 이상의 값들을 0과 1 사이에 구겨 넣을 필요가 있습니다. 그걸 가능하게 하는 수단이 로지스틱 함수예요 이 로지스틱 함수를 사용해서 결갓값을 0과 1 사이로 만들어내는 분석 방법이 로지스틱 회귀입니다. 로지스틱 함수는 위 그림처럼 S자 곡선으로 생겼어요. X값이 아무리 커지거나 작아져도 Y값이 0과 1 사이에 존재하도록 만들어주는 함수 입니다.
* 특정 상품과 비슷한 상품을 찾을 때는 유클리드 거리 측정법과 피어슨상관관계 측정법을 같이 사용하는 것이 좋다.
* 유클리드 거리에서는 결갓값이 작을수록, 피어슨 상관거리에서는 결괏값이 1에 가까울수록 거리가 가깝다.
* 유클리드 거리 측정법을 사용할 때는 데이터 표준화를 해야 한다.
- 데이터 분석에서 이렇게 관측치를 묶는 것을 그룹화 라고 합니다. 그룹화를 하는 방법론은 여러 가지가 있어요. 그중에 - 평균 군집 분석 kmeans Clustering이라는 방법론이 있습니다. 매장 천 곳과 관련된 특징을 선정하여 데이터로 넣어주면 한 번에 관측치를 개로 그룹화해주는 거죠.
* 데이터 분석 방법에는 지도 학습과 비지도 학습이 있다. 지도 학습에서는 회귀와 분류의 방법론을 사용하
* 변수가 많으면 변수 선택, 수축, 차원 축소의 방법을 사용하여 개수를 줄여야 한다.
* 차원 축소의 방법 중에는 주성분 분석이 많이 쓰인다.
* 주성분 분석은 회귀나 분류의 문제를 풀기 위해 선행 과정으로 많이 사용된다.고, 비지도 학습에서는 그룹화와 차원축소의 방법론을 사용한다.
* 관측치를 몇 가지 유형으로 묶고자 할 때는 그룹화를 사용한다. 그룹화의 대표적인 방법론에는 k- 평균 군집 분석과 덴드로그램이 있다.
* k-평균 군집 분석을 사용할 때는 K의 값을 얼마로 할지가 중요하다. 만약 값이 정해져 있지 않다면 CCC 통계량이나 스크리 도표와 같은 보조 지표를 사용하여 k를 정해야 한다.
- 추천 시스템이 추천하는 것은 크게 세 가지입니다.
첫 번째는 대체재예요. 대체재는 이 상품을 봤던 사람이 많이 봤거나산 다른 상품이에요. 이건 안 살 사람을 사게 만드는 기술입니다. 일종의 경쟁 상품 추천이라고도 볼 수 있어서 같은 카테고리 내에서 추천을 해주죠. 카메라 상품이라면 유사한 카메라 상품을 추천하겠죠.
두 번째는 보완재입니다. 보완재는 이 상품을 산 사람이 추가로 산 제 품이에요. 이건 제품을 더 사게 만드는 기술입니다. 좀 더 큰 카테고 리에서 추천해주는데요, 카메라 상품이라면 카메라 액세서리나 렌즈 같은 상품을 추천합니다.
세 번째는 베스트셀러입니다.
- 아이템 기반 협업 필터링과 사용자 기반 협업 필터링의 차이는 하나 입니다. 회원 간 유사도를 보는 대신 상품 간 유사도를 보는 거죠. 아 이템 기반 협업 필터링에서는 피어슨 상관계수 외에 코사인 유사도 같은 방법을 쓰기도 합니다.
- 앞에서 말했듯이 사용자가 많아지면 사용자 기반 협업 필터링을 쓰고 싶어도 못 써요. 계산하는 데 시간이 너무 많이 걸리고, 그 시간을 줄 이려면 IT 비용이 많이 드니까요. 그래서 사용자가 많은 쇼핑몰은 추 천 결과를 계산하는 시간과 비용을 줄이기 위해 아이템 기반 협업 필 터링을 쓸 수밖에 없습니다. 협업 필터링을 고려하는 쇼핑몰이라면 대부분 고객 수보다 상품 수가 훨씬 적을 테니까요.
사용자는 많은데 구매를 몇 달이나 1~2년에 한 번 하는... 예를 들어 통신사 휴대폰 사이트 같은 데는 모델 기반 협업 필터링을 하는 게 더 나아요. 모델 기반의 협업 필터링은 우리가 앞에서 배운 차원 축소나 그룹화를 사용하죠.
- 콘텐츠 기반 추천 시스템은 과거에 주로 사용했어요. 키워드 방식이 라고 볼 수 있는데요. 영화로 치면 장르, 주연 배우, 제작 연도, 감독 등의 키워드로 콘텐츠를 추출해서 이걸 기반으로 추천하는 겁니다. 과거 넷플릭스나 아마존같이 추천 시스템으로 성공한 기업은 대부분 협업 필터링을 기본으로 하고, 콘텐츠 기반 추천 시스템을 가미해서 알고리즘을 만들었다고 보면 됩니다. 물론 최근에는 새로운 알고리즘도 적용하지만요.
- 요즘엔 비 올 때나 한밤중에 듣기 좋은 음악을 추천해주기도 하는데요, 이런 건 어떻게 하는 거예요?
앞에서 얘기한 전통적인 추천 시스템 이외에 상황인지형 추천 시스템 Context-aware Recommender System; CARS 이나 신뢰인지형 추천 시스템 Trust-aware Recommender System; TARS 같은 것도 있어요.
상황인지형 추천 시스템은 기존 협업 필터링에 상황을 덧붙이는 겁니 다. 예를 들어 사용자가 음악을 들을 때 비가 오는지 눈이 오는지 맑 은 날인지 데이터베이스에 기록해놓는 거죠. 물론 날씨 데이터는 다 른 곳에서 가져와서 합쳐야겠죠. 신뢰인지형 추천 시스템은 신뢰할 수 있는 친구가 산 제품을 분석해서 추천하는 겁니다. 예를 들어 페이스북 친구나 인스타그램 팔로어 가 샀거나 본 상품을 추천하는 거죠. 이게 현실에서는 효과가 아주 좋 습니다. 페이스북은 실제로 이런 소셜 네트워크의 신뢰도를 이용해서 상품을 추천하죠. 이런 데이터는 그 소셜미디어를 서비스하는 회사만 가지고 있어요. 그래서 사용자가 많은 소셜미디어 기업의 가치가 높 아질 수밖에 없죠.