- 최초의 마이크로프로세서 4000시리즈 이후 인텔의 히트작이 된 8086 프로세서에 맞서 모토로라는 68000 프로세서를, 자이로그는 Z8000을 출시. 후발주자들은 성능면에서 인텔 8086보다 앞섰고 사용자 편의성 측면까지 고려해 인텔의 약점을 파고들었다. 이런 상황 속에서 인텔은 경쟁전략에 대해 고민했고 일명 크러쉬 전략을 시행. 크러쉬 작전은 고객들에게 마이크로프로세서의 기술적 우수성만을 홍보하는 것이 아니라 고객들이 가진 문제에 대해 포괄적인 솔루션을 제공하겠다는 캠페인이었다. 성능사양을 제시했던 카탈로그도 고객들에게 어떤 도움이 되는지를 제시하는 것으로 바꿈.
- 트랜스포머 기반 알고리즘을 구동하는 것은 매우 고된 단순반복 작업이다. 의미를 알 수 없는 수십만권의 책이 있는데 그 책을 꼼꼼이 읽으며 단어와 단어가 어떤 식으로 연결이 되는지를 보고 가장 많이 연결된 단어로 문장을 구성한다고 생각해보자. 인간이 수행한다는 것은 불가능이다. 상상이야 할 수 있지만 엄청난 성능의 수퍼 컴퓨터가 없으면 실제로 실험해 볼 수조차 없다. 전문가 방식의 인공지능 알고리즘은 정확하지 않지만 주제에 크게 벗어나지 않는 대답을 내놓는다. 트랜스포머 기반 알고리즘은 적당히 학습하면 얼토당토 않은 답을 내놓는다. 모델이 엄청 커지기 전까지는 터무니 없이 낮은 정확성을 보인다. 그러다 일정 규모 이상의 파라미터를 갖게 되면 다른 알고리즘과는 비교할 수 없는 정확성을 보인다.
- 트랜스포머 모델의 특징은 범용성. 이미지 인식, 언어 인식 등 개별적 목적을 가진 다양한 인공지능 알고리즘이 있다. 파라미터값이 작은 모델부터 수조개의 파라미터를 갖는 초거대언어모델까지 사이즈별로도 종류가 다양하다. 사용하는 목적에 따라 라벨이 붙은 데이터를 사용하는 모델도 있고 라벨이 없는 데이터를 사용하는 모델도 있다. 지도학습, 비지도학습 등 학습방식도 다양.
트랜스포터는 무작위 데이터를 입력해 정답을 찾아내는 방식이기 때문에 데이터의 성격을 따지지 않음. 초거대언어 모델을 만들어 목적에 따라 적당히 파인튜닝하면 이미지, 언어, 추천 등 어떤 서비스라도 제공가능. 어떤 데이터가 입력되던디 처리방식은 그저 행렬곱이다. 더하기 곱하기만 반복한다. 더하기 곱하기로 모든 답을 찾아내고 모든 솔류션을 제시한다. 이는 모든 인공지능 서비스의 기반이 된다고 해서 파운데이션 모델이라고도 한다.
- 앞으로의 반도체 성능을 나타내는 기준으로 트랜지스터 집적도나 전력당 성능이 주요 후보로 거론되고 있음. 트랜지스터 집적도를 강조하는 주요 기업은 인텔이다. 인텔은 TSMC, 삼성전자에 비해 공정노드는 뒤처지지만 같은 공정노드에서 트랜지스터 집적도는 높았다. 인텔의 마크 보어는 "일부 기업들이 집적도를 높이지 못하면서 20나노에서 14나노, 10나노 등으로 노드 이름을 바꾸고 있다"며 절대적인 트랜지스터 집적도로 측정을 해야한다고 주장.
트랜지스터 집적도가 높아야 한다는 인텔의 주장도 일리가 있다. 하지만 선폭개선을 지속적으로 진행한 TSMC나 삼성전자는 결국 인텔보다 더 뛰어난 성능을 보여줬다. 같은 노드에서 성능은 인텔이 뛰어날지 몰라도 TSMC, 삼성전자는 인텔보다 앞선 노드를 성공시켰다. 게다가 인텔의 공정은 면적은 줄일 수 있을지 몰라도 트랜지스터끼리 연결하는 배선이 더 복잡해지기도 한다. 배선이 들어가야 할 자리를 줄여서 트랜지스터 면적을 줄인것인지도 노드를 비교할 때 살펴보아야 할 점이다.
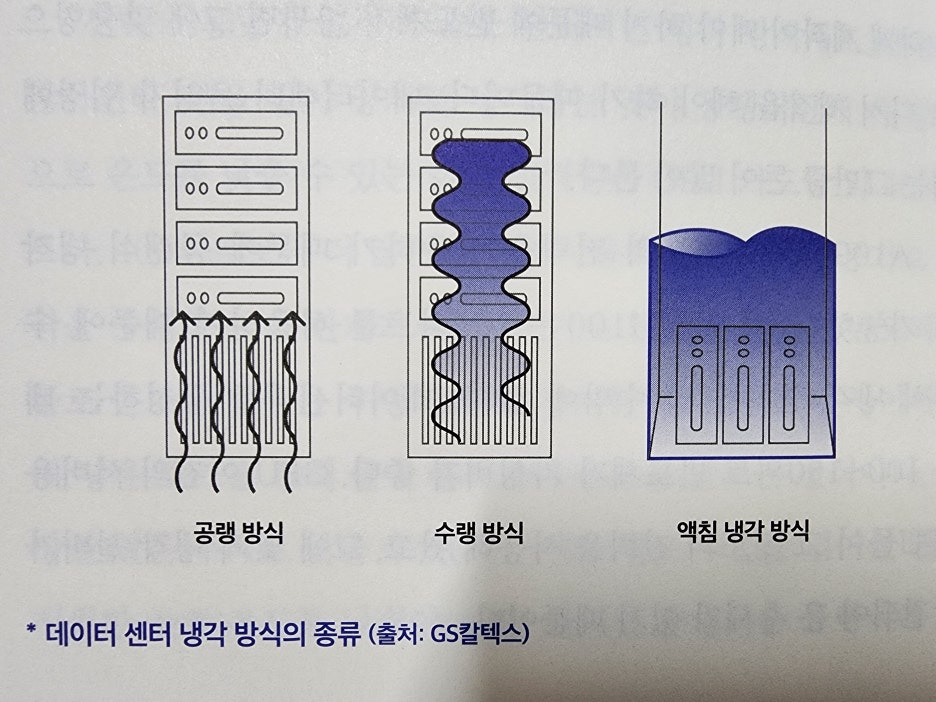
- 냉각장치에 필요한 공간 확보여부에 따라 반도체가 사용할 수 있는 전력 사용량이 정해짐. 냉각장치를 달 수 없는 디바이스에는 고성능 반도체를 쓸 수 없다. TV에는 5와튼 전력을 소비하는 반도체를, 노트북은 10와트, 모바일폰은 2와트 수준을 사용하는 반도체가 한계. 더 좋은 성능의 반도체가 있어도 전력사용량이 많으면 사용할 수 없는 것이다.
- 공랭식으로 온도를 낮출 수 있는 한계 전력량은 GPU카드당 약 400와트. 400와트보다 더 많은 전력을 사용하는 반도체는 수냉식 냉각장치를 사용함.
A100은 400와트의 전력을 사용하기 때문에 공랭식 냉각이 가능. 하지만 H100은 700와트를 사용하므로 수냉식 냉각장치를 달 수 밖에 없음. 데이터센터를 구성하는 데는 100-150와트 반도체가 가성비가 좋음. GPU이전의 서버용 CPU들이 그 정도 전력을 사용해왔고, 그에 맞게 냉각설비가 발전되어 온 추세가 있기 때문.
그렇다고 100와트를 사용하는 AI반도체를 많이 사용하는 것이 정답은 아님. 반도체는 내부에서 데이터 처리를 할 때는 전력을 많이 사용하지 않는데, 다른 칩과 데이터를 주고받을 통신을 하면 전력을 많이 사용하기 때문. 성능이 낮은 반도체를 여러개 달면 오히려 전성비가 떨어진다.
- 쿠다를 개발할 때 고성능 인터페이스와 컨트롤러를 개발할 때 딥러닝 시대를 예상하고 개발한 것은 아니다. 딥러닝의 연산방식이 그래픽 연산방식과 유사하다는 의도치 않은 운이 작용. 이에 더해 엔비디아는 그들이 잘하는 부분을 AI시대에 어떻게 활용할 수 있는지에 대해 빠르게 캐치하고 그 방향으로 빠르게 강화시켜 나갔다. 반도체업의 특성상 미래를 내다보며 사용자가 필요할 것을 예측하고 하드웨어에 녹여내는 것이 임무다. 이를 위해 어떤 반도체는 실제사용자와 밀접한 관계를 유지하며 요구사항을 기준으로 차세대 설계를 구상한다. 특정 고객사가 없는 경우는 다목적으로 사용할 수 있는 범용적인 반도체를 설계하거나 고객사의 수준을 웃도는 연구를 통해 미래를 예측할 수밖에 없다.


'경영' 카테고리의 다른 글
| 나는 작은 회사 사장입니다 (4) | 2024.10.06 |
|---|---|
| 경영 이나모리 가즈오 원점을 말하다 (1) | 2024.10.01 |
| 엔비디아 웨이 (1) | 2024.09.06 |
| 왜 우리는 더이상 껌을 씹지 않을까 (1) | 2024.08.28 |
| 지구를 지키는 괴짜 브랜드 (0) | 2024.08.27 |




