- 데이터를 현금화하는 데는 크게 2가지 방법이 있다. 하나는 기업의 내부에서 데이터를 활용해 효율적으로 운용함으로써 비용을 최적화 하거나 매출이나 이익을 최대화하는 '간접적 현금화 방식'이다. 또 하 나는 데이터에서 찾은 인사이트 insight를 상품·서비스에 탑재해 가치 를 추가로 높이거나 데이터 자체를 상품화해 거래하는 '직접적 현금화 방식'이다. 데이터를 현금화하기 위해서는 기업의 데이터를 상품화 하는 과정과 데이터 기반의 사업 모델을 수립하는 전략이 필요하다. 데이터 상품화는 다음과 같이 4단계로 이뤄진다.
1단계: 전혀 가공되지 않은 원천 데이터
2단계: 정제돼 단순히 연결 · 통합된 데이터
3단계: 데이터 융합으로 만들어진 데이터
4단계: 분석 알고리즘을 활용한 지수 또는 추정 데이터
- 페이스북 - 케임브리지 애널리티카 정보 유출 사건
이 사건은 2018년 초에 케임브리지 애널리티카가 수백만 명의 페 이스북 가입자 프로필을 사전 동의 없이 수집하고 정치적 선전목적으로 사용했다는 사실이 밝혀지면서 일어난 정치적 논쟁이다.
2015년과 2016년에 미국 공화당 소속 상원 의원인 테드 크루즈Ted Cruz의 선거 캠페인에서 케임브리지 애널리티카에 불법 데이터 사용 료를 지불했다는 사실이 보도됐다. 이에 크루즈 선거 본부 측에서는 해당 데이터들이 적법하게 수집된 것이라 생각했다고 주장했다.
더욱이 케임브리지 애널리티카가 수집한 해당 데이터들은 2016년 미국 대통령 선거와 영국의 브렉시트 국민투표뿐 아니라 인도, 이탈리아, 브라질 등 여러 나라에서 투표자들에게 영향을 미치는 데 사용됐다는 것도 밝혀졌다.
이후 페이스북에서는 정보 유출로 피해를 입었다고 생각하는 사용 자들에게 메시지를 보내, 수집된 정보는 아마도 그들의 공개된 프로필'과 '좋아요'로 반응한 페이기들, 생일과 현주소지 정도일 것이라고 안심시켰다. 하지만 그 이후에 페이스북의 일부 사용자들의 뉴스피드, 타임라인, 메시지까지 수집됐다는 사실이 추가로 밝혀졌다. 케임브리지 애널리티카가 페이스북을 이용해 수집한 데이터들은 해당 데이터 주인들의 성격 특성도 psychographic Profiles까지 뽑아 낼 만큼 자세했으며, 심지어 위치까지 파악할 수 있었다. 이렇게 유출된 데 이터들은 여러 나라에서 정치 캠페인 목적으로 활용됐다. 예를 들어 어떤 종류의 정치 광고가 특정 장소에 있는 누구에게 효과적인지를 선별하는 데도 쓰였다.
결국 페이스북의 CEO 마크 저커버그는 2013년 미 의회 청문회에 출석해 케임브리지대학의 연구원 알렉산드르 코간이 페이스북 사용자뿐 아니라 그들의 페이스북 친구들의 정보까지 빼낼 수 있는 퀴즈 앱을 만들었고, 30만 명의 페이스북 사용자가 그 앱을 설치했다고 시 인했다. 그리고 2019년 7월 미국의 연방거래위원회는 투표를 시행 해 페이스북에 50억 달러의 벌금을 부과했다.
- 데이터와 정보는 시간이 지나면 가치가 떨어지는 속성을 지니고 있기 때문에 이들의 가치를 재생시키기 위한 데이터 가공·관리 기술과 가공한 데이터에서 인사이트를 찾기 위한 데이터 분석 기술이 필요하다. 또한 데이터 분석으로 찾은 인사이트를 현장에 적용 하기 위해 현장을 설득하는 과정도 필요하다. 이런 과정을 거쳐 해당 인사이트를 현업 프로세스에 적용하면 기업의 기존 수익 모델을 바 꾸는 등과 같은 파급 효과를 얻을 수 있다.
물론 기업의 모든 문제를 데이터만으로 해결할 수는 없다. 하지만 현재의 불확실성을 줄이고 미래를 준비하는 최선의 방법은 사실을 기반으로 한 데이터와 정보를 기준으로 기업의 의사결정을 하는 것이다.
- 웹 1.0은 월드 와이드 웹의 창시자인 팀 버너스 리rim Berners Lee가 인터넷에 첫 번째 웹 페이지를 쓴 1990년에 시작됐다. 이 초창기 웹은 주로 읽기만 할 수 있는 홈페이지 위주의 HTML 형식이었다. 주로 기업에서 홍보나 배너 형식의 광고에 활용했으며, 얼마나 많은 방문 객이 웹 페이지를 봤느냐가 관심의 대상이었다.
웹 2.0 시대는 2004년에 정보 기술 전문 출판사인 오라일리미디어 의 CEO인 팀 오라일리rim O'Reily가 ‘웹 2.0 컴퍼런스’라는 회의를 주 최하면서 시작됐다. 웹 2.0에서는 주로 사용자 위주의 내용, 쌍방향 접촉, 협력을 강조한다. 쓰기와 읽기가 가능한 커뮤니티 중심의 소셜네트워크 사이트, 블로그, 비디오 사이트, 웹앱, 위키피디아 등이 이에 해당한다. 기업에서는 웹 2.0을 이용해 다양한 장소에서의 실시간 보고서 및 모니터링 공유가 가능해졌다. 웹 2.0의 중요성은 웹을 기업의 마케팅 이나 고객 관리에 적극 활용하기 시작했다는 데 있다. 상품과 관련된 고객 커뮤니티 활동을 도와줌으로써 충성 고객을 관리하고, 자사 상 품의 의견 불만을 수렴하는 소셜 고객 관리가 가능해진 것이다. 웹 3.0은 웹 국제표준화단체인 월드 와이드 웹 컨소시엄W3C에서 만든 웹 표준을 따르는 시맨틱 웹semantic Web의 시대다. 이 시대에는 데이터의 '연결'뿐 아니라 '의미'도 중요해졌다. 이는 웹에서의 공통된 데이터 형태나 프로토콜 교환으로 데이터 공유를 가능하게 함으로써 커뮤니티, 기업, 앱 간에 데이터를 재사용하기 쉽게 만드는 것이다. 따라서 웹 표준을 지켜 데이터를 제작하는 게 중요하다. 2013년 기준 4,000만 개의 웹 페이지가 이 시맨틱 웹 표준을 따르고 있다.
웹 1.0이 내부 기업 중심이고, 웹 2.0이 커뮤니티 중심이라면, 웹 3.0은 외부 산업 간의 연결 중심으로 4차 산업혁명을 가능하게 하는 단계에 해당한다.
- 대표적인 고객 관리 시스템의 종류는 다음과 같다.
1) oCRM: 고객 서비스, 영업, 마케팅을 통합 · 자동화하는 영 차원의 고객 관리 시스템
2) aCRM: 수집 · 통합된 데이터 분석 · 예측 · 활용을 강조한 고객 관리 시스템
3) gCRM: 지리 정보를 활용한 고객 관리 시스템
4) eCRM: 인터넷과 모바일을 연결한 고객 관리 시스템
5) sCRM: 소셜 네트워크를 활용한 고객 관리 시스템
-특히 aCRM은 기존 세그먼트 중심의 고객 관리 시스템에서 심화된 데이터 마이닝과 예측 분석 기술을 발전시킴으로써 타깃 마케팅에 커다란 공헌을 했다. 거의 1990년대 말부터 시작된 CRM은 웹 2.0 시대를 지나면서 2005년쯤에는 소셜 CRM으로 발전했다. 소셜 CRM은 다음 그림과 같이 전통 CRM에 고객들의 온라인 커뮤니티 및 소셜 네트워크 관련 데이터를 포함시켜 기업의 수익 창출에 기여하는 고객 서비스 · 영업·마케팅에 활용하는 모든 활동을 의미한다. 구글 트렌드에서 소셜CRM'을 검색해 보면 2008년부터 상승세를 나타내고 있다는 것을 알수 있다.
전통 CRM은 기업의 고객 관리 사업부에서 기존 고객 위주의 정해진 채널로(전화 상담 또는 방문) 거래 및 접촉 활동과 이력에 따른 정보를 고객에게 일방향으로 전달하는 의사 소통방식이었다.
반면, 소셜 CRM은 철저히 고객 중심의 프로세스로 운영된다. 즉, 기업과 관련된 모든 사람이 다양한 채널(이메일, 모바일, 웹 등)을 이용해 고객이 선택한 시간에 정보를 양방향으로 소통·공유하는 방식으로 운영된다. 또한 고객들이 상호 파트너로서 정보를 공유하는 협력체를 만들기도 하며, 기업에서는 이런 활동과 관계를 지원한다. 기업은 이 런 과정에서 기업 정보 시스템에 쌓이는 정보를 재가공해 고객 및 협력 기업들과 공유하며 발전해 나간다.
최근에는 다양한 채널을 뛰어넘는 옴니 채널 마케팅이 주목받고 있다. 옴니 채널의 '옴니'는 '모든 것'을 의미하는 라틴어 '옴니omi'를 의미한다. 옴니 채널 마케팅은 전통적인 고객 소통 채널(전화, 방문 등) 과 디지털 채널(인터넷, 모바일 등)을 통합해 최적의 마케팅 효과를 만들 어 내는 전략이다. 이러한 마케팅을 이용하면 기업은 온·오프라인 스 토어, 모바일, 전화, 인터넷 등과 같은 모든 채널을 하나로 연결해 고객이 필요로 하는 정확한 정보를 전달할 수 있다.
결국 정보 시스템에 따른 데이터의 전사적 통합이 기업이 데이터 기반의 운영 체계로 변신하는 터닝포인트가 된다는 사실을 알 수 있다.
- (1) 효율성 모델
지속적 저비용 기반의 수행 성과를 제공하는 모델로, 일상의 상시 업무를 주로 수행한다. 잘 정의되고 쉽게 이해되는 규칙이나 프로세 스가 장점이다. 대표적인 예로는 자동 신용 결정, 드론의 물건 배달 등을 들 수 있다.
(2) 효과성 모델
유연한 통합과 협력을 지원하는 모델로, 다양한 영역을 상호 연결 하는 업무를 주로 수행한다. 의사소통과 상호 협조에 의존하는 경향 이 있다. 대표적인 예로는 소비자나 전사 고객 서비스 가상 에이전트, 협력적 업무 프로세스 관리 등을 들 수 있다.
(3) 전문성 모델
특정 전문 기술이나 영역 지식을 활용하는 모델로, 전문가의 상황 판단이 필요한 업무를 주로 수행한다. 전문적인 기술과 경험에 의존 한다는 장점이 있다. 대표적인 예로는 의료 진단 시스템, 법률 또는 금융 리서치 등을 들 수 있다.
(4) 혁신성 모델
창의력과 새로운 아이디어를 실현하는 모델로, 원천 기술을 다루거 나 혁신적인 업무를 주로 수행한다. 전문성, 실험, 탐구 그리고 창의성에 의존하는 경향이 있다. 대표적인 예로는 바이오 메디컬 연구, 패션 디자인, 음악 창작 등을 들 수 있다.
- 데이터 기반 비즈니스 모델 - 빌 슈마르조 모델
대표적인 비즈니스 모델인 '빌 슈마르조 모델'은 미국의 스토리지업체 델 EMC의 CTO(최고 기술 책임자)인 빌 슈마르조Bill Schmarzo가 구 상했다. 기업 내부의 데이터 활용 혁신 과정을 고려해 만든 데이터 기 반 비즈니스 모델이다. 이 모델을 살펴보면 성공적인 데이터 기반의 사업 모델은 프로젝트 방식으로 단번에 만들어지는 것이 아니라 점진적으로 이뤄진다는 사실을 알 수 있다.
- (1) 모니터링 단계
모니터링 Monitoring 단계에서는 비즈니스 인텔리전스BI를 활용해 현 재 진행되는 비즈니스의 성과를 측정한다. 기본적인 분석으로 비즈니 스 목표에 따른 성과를 달성 또는 미달로 표시하고, 해당 결과와 함께 그에 따른 조치 · 가이드를 담아 각 부서의 담당자에게 자동으로 경고 메시지를 보낸다. 이 단계에서는 이전 기간의 캠페인 또는 다른 산업 을 벤치마킹해 브랜드 인지도나 고객 만족도, 상품 품질, 수익 등과 관련된 지수를 산정한다. 또한 비즈니스 의사결정 중에서 데이터 분석이 가능한 영역을 선정하고, 분석 환경sandbox을 구성하며, 분석 지수에 대한 프로파일을 만든다. 이와 함께 기업의 데이터 사용자들을 대상으로 데이터 활용에 대한 내용을 교육한다.
(2) 인사이트 단계
인사이트.insights 단계에서는 통계, 예측 분석, 데이터 마이닝을 활용 해 실현 가능한 비즈니스 인사이트를 찾아 내고, 이를 진행 중인 비즈니스에 접목한다. 예를 들어 마케팅 부문이라면 특정 캠페인이 더 효과적이라 추천하고, 구매 횟수가 평소보다 줄어든 우수고객에게는 할인 쿠폰을 보내라고 추천한다. 또 제조 부문이라면 표준 범위를 벗 어난 생산 라인의 기계를 예측해 알려 준다.
이 단계에서는 데이터의 활용이 부서별로 이뤄진다. 비즈니스 인사이트 단계가 성숙기에 접어들면 분석을 최적화하기 위해 데이터 레이크 Data Lake와 같은 빅데이터 플랫폼을 구축해 데이터 중심의 의사 결정과 운영에 대한 효과성을 측정한다.
(3) 최적화 단계
최적화optimization 단계에서는 프로세스를 자동화하기 위해 고급 분석을 조직 내부에 내재화Embeded하는 애플리케이션을 사용한다. 이 단계에서는 데이터를 전사적으로 활용할 수 있게 된다. 따라서 각 지방의 날씨나 구매 이력 등을 기반으로 재고 및 자원 배분과 인력을 최적화하 는 등 전사적인 효율화가 완성된다. 예를 들어 소셜 미디어 데이터에서 얻은 인사이트를 이용해 적정 재고를 관리하고 최적의 상품 가격 을 책정하기도 한다.
내부의 데이터 활용이 성과를 내고 경험이 쌓이면 새로운 상품이 나 서비스를 창출할 기회도 만들 수 있다. 예를 들면 소매 유통 분야 에서 상품을 분석하고 분류하는 작업에 인공지능을 이용한 자동 분류 엔진을 사용할 수 있다. 이런 자동 분류 엔진은 제품화할 수도 있다. 즉, 내부 문제를 해결하기 위한 분석 인사이트를 개발해 기업 내 프로세스에 적용하고 최적화한다.
(4) 데이터 현금화 단계
데이터 현금화 Data Monetization 단계에서는 기업 내부를 뛰어넘어 다 른 기관이나 기업을 대상으로 한 외부 비즈니스에 주목한다. 이 단계에 진입한 기업은 분석 인사이트를 포함한 데이터를 패키지화해 다른 기관이나 기업에 판매한다. 이 예를 들어 맵마이런닷컴MapMyRun.com은 모바일 앱을 이용해 사람의 이동 장소와 활동 이력을 관리해 주는데, 이러한 데이터에서 찾아 낸 고객 취향과 관련한 데이터를 패키지화해 스포츠 의류 제조 기업이나 스포츠 용품 소매상, 보험회사, 의료 관련 기관에 판매한다. 이와 같이 데이터 현금화 단계에서는 데이터와 분석 인사이트를 활용 해 새로운 시장 · 상품 고객을 창출한다.
(5) 모델 혁신 단계
모델 혁신Metamorphosis 단계에서는 데이터를 바탕으로 새로운 시장 을 창출하기 위한 혁신적 비즈니스 모델을 구축한다. 대표적인 사례는 다음과 같다.
* 가정용 기기 제조사가 예측 분석을 활용해 교체 시기를 추천하거나 비용과 환경 등을 고려해 적절한 브랜드를 추천하는 서비스 비즈니스 모델을 창출
* 항공사에서 고객의 여행 패턴, 선호도를 바탕으로 고객이 여행하고 싶어하는 지역의 쇼핑 정보, 스포츠 이벤트, 렌터카, 호텔 등을 찾아 추천하는 비즈니스 모델을 창출
- 데이터를 자산으로 인식하기 위해서는 '데이터 거버넌스적인Data Governance 접근이 필요하다. 데이터 거버넌스는 데이터 활용을 중심으로 한 인력, 프로세스, 정책에 관련된 일련의 시스템적 접근을 말한다. 즉, 기업 스스로 어떤 데이터를 보유하고 있으며, 필요한 데이터가 어디에 있고, 데이터를 이용해 무엇을 하고 있으며, 접근성과 데이터 품질은 어떤지, 추가로 어떤 데이터를 새로 더 수집해야 하는지 등에 관한 전사 차원에서의 운영 가이드나 정책을 세우는 것을 말한다. 데 이터 거버넌스는 데이터 관리 기능 중 중요한 영역이다.
- 데이터 기획은 데이터의 속성과 프로세스를 전체적으로 정의하고 찾아내는, 데이터 활용을 위한 첫 번째 작업이다. 이러한 작업을 통해 만들어진 정확한 데이터 구조와 프로세스는 지속적이고 단계적으로 진행된다. 또한, 잘 정의된 데이터 기획은 데이터에 쉽게 접근할 수 있게 해주고, 데이터를 잘 관리하게 해주며, 미래에 데이터 보강을 수 월하게 해준다.
데이터 기획은 비즈니스 규칙을 적용한 저장 시스템 및 데이터 통합에도 관여한다. 초기 데이터 생성을 위한 주체는 주로 사물, 사람, 현상들을 시간상 또는 공간상의 패턴이나 흐름을 관찰한다. 관찰된 데이터 현상이나 경험은 주로 크게 시간, 공간, 대상의 변수들 조합으 로 이뤄진다. 이는 데이터를 기획할 때 주체가 육하원칙에 따라 생성 가능하다는 의미다. 예를 들면 고객이 오늘 온라인으로 운동화를 샀다면 고객의 이름, 구매한 시간, 구매한 위치, 구매 상품 그리고 구매 여부가 변수들의 조합이다.
- 데이터 시대에서 기업을 성공적으로 이끌기 위한 최우선 과제는 모든 수단을 동원해 내·외부데이터를 연결 · 통합·융 합할 수 있는 환경을 만드는 데 있다. 빅데이터 역시 그냥 그 자체로 존재하기도 하지만, 대부분은 분산된 데이터를 연결 · 통합함으로써 만들어진다.
- 기업의 데이터 사일로silos 효과로 인해 데이터가 분산되어 있다는 것은 데이터가 존재하기는 하지만 정보로서의 연관성이 없거나, 필요 시점에 활용할 준비가 되어 있지 않은 상태임을 의미한다.
예를 들어 사람의 모양이나 특성을 알아야 한다고 가정해 보자. 그 런데 팔이나 손에 관한 데이터는 A 저장소에 있고, 다리와 발에 관한 데이터는 B 저장소에 있는 등 신체 각 부위에 관한 정보가 각기 다른 곳에 있다면 어떻게 될까? 이런 경우 각 신체 부위별 정보는 알 수 있 겠지만, 신체 전체의 모양이나 특성에 대한 정보는 알 수가 없다. 이 처럼 데이터가 분산되어 있거나, 정제되어 있지 않아 데이터 활용을 어렵게 하는 '데이터의 병목 현상Bottleneck'이 생긴다.
- 데이터 세트와 데이터 세트 간의 연결은 연결의 최소 단위일 뿐이고, 기업의 운영이 복잡해질수록 정보 시스템의 데이터베이 스 간의 연결이나 서로 다른 기종의 데이터베이스 간의 연결도 필요 하다. 나아가 기업 내·외부의 서로 다른 플랫폼이나 채널 간의 데이터 연결도 필요해진다.
- 연결된 데이터는 분산된 데이터보다 낫기는 하지만, 필요한 정보를 뽑아내기 위해서는 여전히 더 많은 작업이 필요 하다. 바로 '데이터 통합'이 그러한 작업 중 하나이다. 여러 개의 데이 터 세트들을 식별자로 연결한 후 중복 식별자들을 걸러내서 단독 식 볼가들만으로 데이터 세트를 구성하고, 필요한 내용에 대해 중복 정 보를 게거하거나 잘못된 포인트 값을 수정하거나 빠진 포인트 값을 캐워 넣는 등의 정게 작업을 하는 것이다. 예를 들어 여러 날짜로 된 동일한 경보가 있으면 최근 날짜의 가장 정확한 내용으로 변환하거나 잘못 기입된 포인트 값을 수정하는 작업이다.
- 리서치 기업인 누스타Neustar에서 조사한 바에 따르면, 원천 데이터 는 2~3년 정도 지나면 20~30%의 가치만 남고 가치 대부분이 소멸 한다고 한다. 예를 들어 어떤 기업이 나에 관한 데이터를 가지고 있다. 고 생각해 보자. 처음에는 그 기업이 내가 사는 곳, 직장 등 나에 관한 정확한 데이터를 가지고 있지만, 2년 뒤 내가 이사를 하고 직장을 옮 긴 사실을 그 기업에 알려주지 않으면 그 기업에는 처음에 수집한 정 확하지 않은 데이터만 남게 된다. 이는 결국 데이터를 다시 사용Data Reusable 하려면 '정제Data Refinery'가 필요하다는 의미이다. 데이터 정제 는 주소 업데이터와 같이 시간의 흐름에 따라 데이터를 업데이트도 하 지만 데이터의 오류를 수정하는 것, 데이터의 단위를 일관성 있게 맞 추는 것 등 다양한 데이터 품질에 관련된 일련의 업무들을 포함한다.
- 데이터 관리 플랫폼은 전사적으로 통합된 데이터에 외부에서 구매 한 데이터를 추가하는 방법으로 데이터를 수집하고, 이를 가공 · 신호 생성 · 분석 · 접근 조치하는 과정을 거쳐 기업에서 중요한 의사를 결 정하는 데 필요한 정보를 제공한다. 최근 들어 이 과정이 더욱 중요해 지면서 DMP가 데이터를 기반으로 비즈니스를 영위하는 기업의 필수 조건이 됐다. DMP는 크게 개별 기업의 내·외부 데이터를 가공하는 프라이빗 데이터 관리 플랫폼Private DMP'과 산업 간 또는 기업 간 데이터의 연결과 광고나 마케팅의 활용을 돕는 '퍼블릭 데이터 관리 플랫폼Public DMP 으로 구분한다.
- 데이터 분석으로 데이터 모델을 개발한 후에는 이를 비즈니스 서비스(미디어나 채널)에 적용하기 위해 '의사결정 엔진Decision Engine'이 필 요하다. 의사결정 엔진은 알고리즘 기반의 분석 모델이나 룰들을 보 관하는 저장소와 이벤트가 생겼을 때 조건을 검색하는 엔진으로 구 성되는데, e커머스에서 흔히 사용하는 추천 엔진이 이에 해당한다. 의사결정 엔진들은 추천이나 룰 기반의 엔진, 신경망 네트워크, 빅 데이터와 강력해진 컴퓨팅 파워를 바탕으로 여러 기능을 조합해 AI를 플랫폼화하고 있다. AI 플랫폼은 인지 서비스cognitive Services, 봇Bot 도구를 사용한 대화형 AI 등 사전에 구축된 API에서 머신러닝 Machine Learning을 사용한 사용자 맞춤형 모델의 구축에 이르기까지 포괄적인 AI 서비스 세트를 제공한다.
예를 들어 고객의 구매 여정, 즉 상품 인지, 판단 그리고 구매에 이 르기까지 각 단계별로 고객의 성향을 분석하거나 예측 모델 등과 같 은 인공지능을 활용하는 AI 서비스를 세트로 제공한다.
- AI 플랫폼은 알고리즘 개발자 및 데이터 과학자가 AI 도구를 활용해 AI 솔루션을 쉽게 만드는 데 도움을 준다. 이를 이용하면 데이터 연결, 분석 모델 구축 및 학습, 모델 배포와 성과를 추적할 수 있다. 대표적인 상업용 AI 플랫폼으로는 구글의 클라우드 머신러닝 엔진 Cloud Machine Learning Engine, 아마존의 세이지메이커 sageMaker, 마이크로 소프트의 애저 머신러닝 스튜디오 Azure Machine Learning, 세일즈포스의 아인슈타인Einstein, IBM의 왓슨 스튜디오 Watson Studio 등이 있다.
- 매켄지의 조사에 따르면, 2019년과 2020년 미국 기업의 50~60% 가 데이터 활용에 실패했다고 한다. 데이터 활용에 실패한 이유에는 데이터 기술 인력 부족, 경영진의 지원 부족, 데이터 사일로 현상 등이 있겠지만, 거의 대부분 데이터 거버넌스와 관련된 이슈들 때문이다.
데이터를 다양한 업무에 활용하려면 누군가는 데이터를 정리해 야 하고, 데이터를 가공하는 프로세스를 만들어야 하며, 새로운 데이 터 룰을 정의해 동기화하고 데이터의 생명 주기를 관리해야 한다. 이 와 같이 데이터 자산을 관리하는 일련의 업무를 '데이터 거버넌스path Governance'라고 한다. 데이터 거버넌스에는 데이터를 관리하는 데 필요한 프로세스, 역할, 책임, 정책도 포함된다.
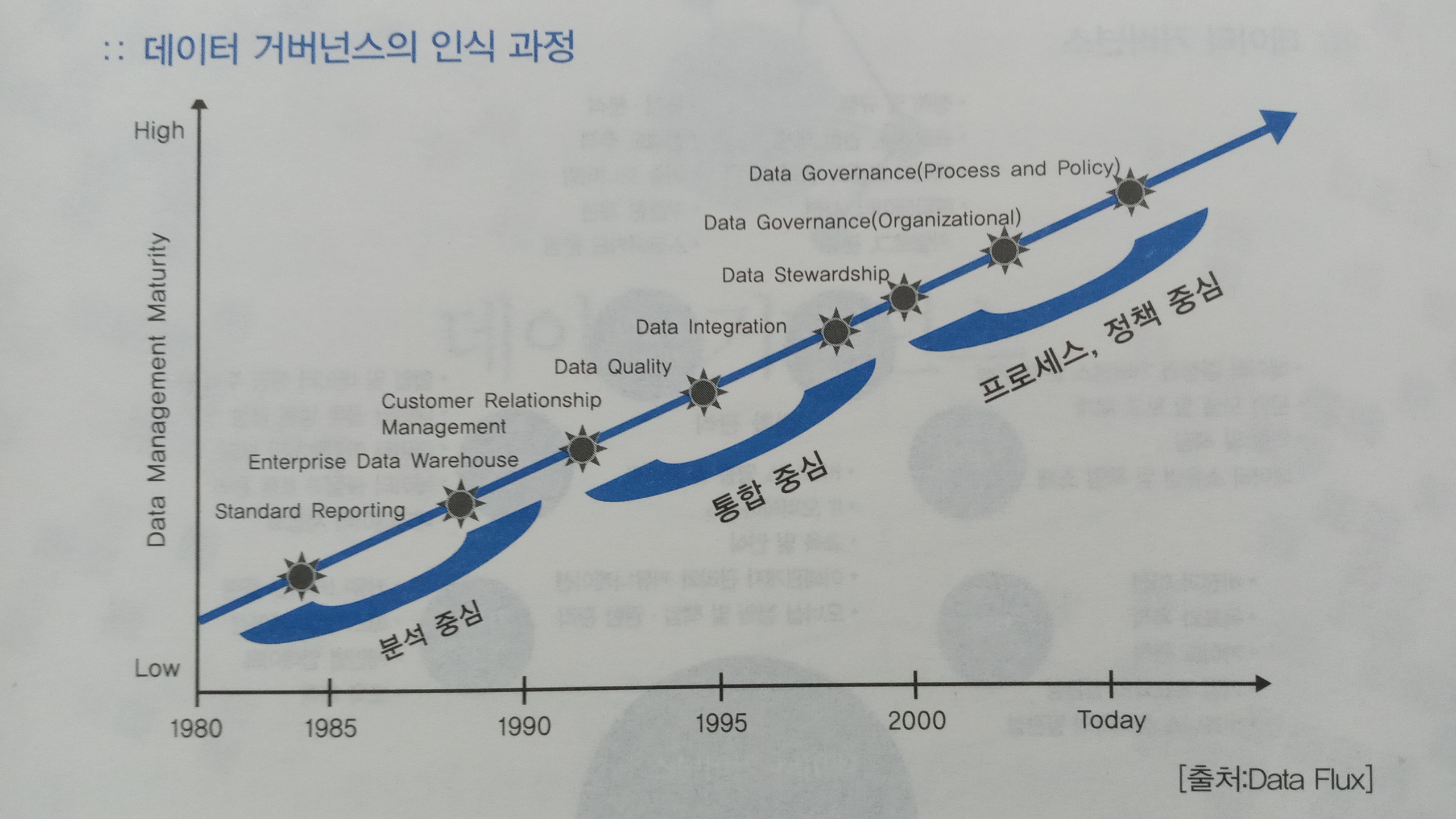
- 데이터 거버넌스에 관련된 인식은 어느 한순간이 아니라 시대를 거치면서 발전했다. 미국의 경우, 데이터 거버넌스에 관한 논의가 처음 이뤄졌던 1980~1990년대에는 주로 단순 데이터 분석이 관심의 대상이었다면, CRM이 기업의 주요 관심사였던 1990년대 말부터 는 데이터의 품질을 포함한 데이터 통합이 주요 관심의 대상이 됐다. 2000년대 후반으로 넘어오면서부터는 데이터 관리, 프로세스, 정책 을 포함한 데이터 거버넌스에 중점을 두면서 현재와 같은 형태로 진화했다. 그리고 2010년대 이후 데이터 거버넌스 체계가 확립되면서 빅데이터 활용의 성공 가능성이 높아졌다.
- 메타데이터는 데이터의 잠정적인 가치를 높이는 것이므로 반드시 관리해야 한다. 메타데이터는 데이터를 설명하는 데이터, 즉 데이터에 관련된 정보를 포함하고 있는 데이터다. 메타데이터는 데이터에 관련된 등급, 구조, 내용 정보를 제공함으로써 데이터를 쉽 게 관리하고 검색할 수 있다. 메타데이터 저장소 Metadata Repository는 기업의 메타데이터를 저장하 는 장소로, 데이터를 자동으로 수집하기 위한 기능과 요청 · 승인·확 인 등의 데이터 관리 업무 프로세스를 효율적으로 수행하기 위한 워크 플로 기능을 제공한다.
특히 데이터의 보안 및 위험 관리를 위한 데이터 등급 체계도 메타데이터 시스템에서 관리된다. 데이터 등급 체계는 기업마다 달리 적 용하지만, 데이터 거버넌스 차원에서 이를 관리하는 정책이나 프로세 스가 필요하다. 특히 데이터를 공개해야 하는 공공 기관에서는 정보 공개의 안전성과 투명성을 확보하기 위해 반드시 데이터 등급 체계를 전사적으로 관리해야 한다.
- "데이터의 품질 측면'을 관리하려면 비즈니스 규칙, 품질 모니터링, 품질 대시보드, 이슈 관리, 데이터 연계 등과 같은 데이터 관리 시스 템을 확인해야 한다. 데이터의 품질은 데이터의 품질 수준은 다음과 같이 다양한 요소에 따라 결정된다.
* 완전성: 필요한 데이터를 얼마만큼 보유하고 있는가?
* 적시성: 적정한 시간에 데이터가 존재하는가?
* 유효성: 비즈니스에 가치가 있는가?
* 일관성: 시스템 간의 데이터가 일치하는가?
* 정확성: 데이터가 실제 현상을 정확히 반영하는가?
* 연관성: 데이터 객체(Entity) 간 내용의 관련성이 있는가?
* 최신성: 최근 데이터로 갱신됐는가?
- 데이터 거버넌스 구현의 3단계
데이터 거버넌스는 단기간에 완성되기 어려우므로 기업이나 기관에서는 다음과 같이 단계적으로 접근해야 한다.
1단계, 운영적 접근 단계에서는 여러 부서의 협력 없이 주로 IT 부서에서 데이터 정책·보안·보호를 담당한다. 이 단계에서는 데이터가 기업의 전략적 자산으로 취급되지 않으며, 조직 내에 데이터를 전적으로 담당하는 실무자나 관리자가 없다.
2단계, 전술적 접근 단계에서는 현재 직면하고 있는 이슈에 중점을 두고, 데이터 거버넌스를 수행한다. 주로 데이터 거버넌스에 관련된 책임, 역할, 정책에 신경쓰며, 데이터에 관련된 메타데이터, 비즈니스 용어를 표준화한다. 이 단계에서도 여전히 최고 의사결정자의 지원이나 관여는 없다.
3단계, 전략적 접근 단계에서는 데이터를 기업의 자산으로 인식하고, 기업 내 데이터의 성장에 도전이 되는 환경에 적극적으로 대처하면서 데이터 거버넌스를 장기적 · 미래지향적으로 바라본다. 기업은 이 단계에서 데이터 거버넌스 위원회와 데이터 최고 책임자Data Chief Oficer, 데이터 위험 관리 최고 책임자Data Risk Officer를 두고, 데이터에 서 최대의 가치를 뽑아 내기 위한 전사적 노력을 아끼지 않는다. 이 단계에서는 데이터 가치를 주기적으로 확인해 회계적으로도 적용한 다. 또한 주로 프런트엔드Front-End 위주로 고객의 관점에 관심을 둔 다. 그리고 전사적으로 비정형 데이터에 관련된 개념이나 기술에 관해 논의하거나 새로운 단어를 표준화하는 데도 적극적이다.
- 서비스 아키텍처는 시대별로 발전하면서 진화해 왔다.
(1) 모놀리식 아키텍처
과거 모놀리식 아키텍처 Monoliths Architecture는 문제가 생겼을 때 원인을 추적해 수정하기가 어려웠을 뿐 아니라 유지 관리도 힘들었다. 즉 공통된 라이브러리를 사용해 서로 연결돼 있으므로 데이터를 주가하거나 갱신할 때 시스템 전체를 부팅해야만 했고, 구조상 확장성이 제한적이었다. 물론 모놀리식 아키텍처가 나쁘다고 말할 수는 없다. 애플리케이션이 간단하고 다른 애플리케이션 모듈과의 연결성이 부족할 때, 예를 들어 기업의 웹 서비스나 간단한 운영 모니터링 서비 스는 여전히 모놀리식 아키텍처를 사용한다.
(2) 서비스지향 아키텍처
서비스지향 아키텍처service-Oriented Architecture, SOA는 소프트웨어를 재사용할 수 있도록 서비스 단위나 구성 단위로 분리해 구축하는 방식 의 아키텍처를 말한다. 데이터의 구조상 캐노니컬 데이터 모델canonical Data Model을 따른다는 점에서 모놀리식 아키텍처와는 다르다.
캐노니컬 데이터 모델의 장점은 단일 구조의 데이터 모델이라는 것이지만, 구조상 하나의 변화만 생겨도 시스템 전체의 개발이나 운영에 문제를 일으킬 수도 있다는 단점이 있다. 그리고 신기술이나 추 가 구조 확장을 적용하기 어렵다. 이 모델은 기업의 전체 데이터로 구 성돼 있지 않고, 통합 데이터 단계에 필요한 여러 도메인의 데이터를 공유한다. 클라우드 시스템을 아직 도입하지 않은 대부분의 기업이 이 서비스지향 아키텍처를 사용한다.
(3) 마이크로 서비스 아키텍처
빠르고 지속적인 변화에 대응해야 한다면 마이크로 서비스 아키텍 처를 고려해 볼 만하다. 마이크로 서비스 아키텍처는 시스템 간에 메 시지를 주고받을 수 있도록 최소한으로만 연결되고, 나머지는 독립적인 프로세스로 구성된 분산 아키텍처다. 따라서 새로운 환경에서 테 스트하기 쉽고, 확장하거나 운영하기도 쉽다는 장점이 있다.
마이크로 서비스 아키텍처는 서로 독립된 여러 도메인으로 나뉘어 있기 때문에 시스템의 일부에 문제가 생겨도 전체 애플리케이션으로 확산되지 않는다는 장점이 있지만, 기술적으로 복잡하다는 단점이 있다.
마이크로 서비스 아키텍처를 사용하는 대표적인 기업으로는 넷플릭스'를 들 수 있다. 넷플릭스는 데이터 서비스를 약 500개 이상의 마이크로 서비스 아키텍처를 활용해 지원하고 있다. 이로써 매일 100~1,000개의 새로운 서비스가 적용되거나, 바뀌거나, 없어진다고 하는데, 그런데도 거의 모든 서비스를 사용할 수 있다고 한다.
또 다른 기업 사례로는 '이베이eBay'를 들 수 있다. 이베이는 초기에 펄Perl 기반의 모놀리식 아키텍처를 활용하다가 이를 하나의 C++ 라이브러리로 바꿨고, 지금은 마이크로 서비스 아키텍처를 사용하고 있다. 트위터 역시 이와 비슷한 변화 과정을 거쳐왔다.
- IoT 플랫폼에서 데이터 서비스의 가장 큰 이슈는 수집되는 데이터 속도에 맞게 처리하는 일이다. 센서에서 수집되는 데이터의 속도에 따라 크게 3가지 주기로 구분된다.
* 일일 또는 시간 단위의 배치(Batch Process)
* 분 또는 초 단위의 마이크로 배치(Micro Batch)
* 마이크로 초 단위(Milisecond)의 실시간 이벤트 프로세스(Event Process)
- 마이크로 초 단위의 실시간 이벤트는 전기 공급 서비스나 공장의 생산 라인 셧다운Shutdown과 같은 산업 재해를 막기 위해 필요한데, 이 경우에는 클라우드 시스템만으로는 너무 늦고 수천, 수백 개의 디 바이스에서 모은 수십 테라바이트TB의 데이터를 전송하기도 어렵다. 이때 포그rog 또는 엣지 컴퓨팅 Edge Computing 기술을 사용한다. 이들은 데이터의 저장 및 전송 지점을 데이터를 생성하는 디바이스에서 처리할 수 있게 도와준다. 즉, 생산 공장의 라인, 전봇대의 꼭대기, 기찻길, 자동차 등에서 바로 데이터를 저장 및 전송하는 것을 말한다. 이로써 데이터 전송이 지연Latency 되는 것을 줄일 수 있다. 엣지 컴 퓨팅이 물리적 디바이스에서 데이터를 수집·분석 · 프로세스하는 통제 시스템이라면, 포그 컴퓨팅은 데이터가 발생하는 지점의 로컬 네트워크 Local Area Network, LAN 안에서 데이터를 처리하는 시스템을 말한다. 이렇게 데이터를 감지하는 디바이스에서 데이터를 빠르게 처리해 IoT 플랫폼에 센서 데이터를 전송하는 것이다.
- 글로벌 기업들은 수십 년 동안 그 시대에 맞는 기업의 핵심 역량을 강화하고 위기를 극복하기 위해 데이터를 생성 · 수집·분석해 비즈니스에 적극적으로 활용해 왔다. 초기 제품의 품질과 다양성 시대에는 주로 데이터 생성에 관심을 갖게 됐고, 유통·가격 시대에는 데이터 분석 · 통합에 관심을 갖게 됐으며, 광고·마케팅 시대에 접어들어서는 많은 정형 데이터를 분석 · 확장해 활용하게 됐다. 이로 인해 웹 2.0 시대 이전까지는 주로 경제학 · 통계학·수학 전공 자들처럼 숫자나 통계에 익숙한 인력을 고용해 실무자들에게 각 비 즈니스 영역에 맞는 분석 방법을 가르쳤다. 예를 들면 마케팅 분석가 에게는 마케팅 믹스 모델이나 가격 결정 모델을 가르치고, 금융·재정분석가에게는 신용 위험 관리 분석이나 사기 감지 모델을 가르치는 식이었다. 이러한 인력들은 주로 데이터 분석가, 비즈니스 분석가, 비 즈니스 인텔리전스BI 또는 리포트 분석가라 부르기도 했다. 그리고 이러한 분석가들이 지속적으로 경험을 쌓으며, 기업의 일정 영역이 아닌 고객, IT, 신사업, 신상품 등과 같은 다양한 영역으로 확장해 나갔다. 웹 2.0 시대 이후에는 비즈니스 환경이 더욱 복잡해지고 업계Domain지식의 중요성이 강조됨에 따라 기업에서 단순 분석가보다는 업계에 관한 깊은 지식과 경험을 보유한 고급 분석가, 즉 데이터 과학자를 선호하게 됐다. 이에 따라 기업들은 데이터를 활용하기 위해 단순 분야 별 데이터 분석가뿐 아니라 심리학, 물리학, 경영학, 엔지니어 영역의 전문가들까지 영입하기 시작했다. 2010년대로 넘어오면서 실시간 웹 3.0으로 데이터 과학이라는 영역이 더 유명해지면서 전통 비즈니스 분석 분야보다 훨씬 성장 발전했다. 이로 인해 데이터 과학 영역이 소셜 네트워크에서 발생하는 비정형 데이터의 분석까지 확장됐고, 최근에는 각 영역별 기업 내부 데이터를 다른 산업 영역으로 연결해 활용하는 단계로 발전하게 됐다.
이러한 과정을 분석 정보 시스템 측면에서 살펴보면, 초기에는 ERP를 통해 데이터를 생성 · 수집하는 데 집중하다가 이후에는 데이터 마이닝으로 발전했다. 그리고 비즈니스 인텔리전시와 관련된 소프트웨어 개발 시대에 접어들어 분야별 분석가들의 역량이 점차 성장하고, 영업·마케팅 · 인사 등의 운영 부서와 IT 부서 간 협력 과정에서 현업의 경험을 기반으로 인문적 요소, IT 기술, 공학적 지식을 결합해 성과를 거두는 단계로 성장했다.
- 데이터 활용을 실패하게 만드는 요소들이 있는데, 그중에서 특히 중요한 항목은 다음과 같다.
1 데이터에 관련된 사용자의 이해(Data Literacy)와 접근의 어려움: 데이터의 사일로, 보안, 개인 정보 관련
2 데이터로부터 충분하지 않은 패턴이나 신호의 생성 또는 생성 전문 기술 부족
3 비즈니스 목표에 충분히 부합하지 않는 분석 인사이트: 시장 트렌드, 고객 서비스, 상품의 경쟁력 부족
4 개발된 분석 모델이 운영상(Production) 전체 데이터에 관련된 확장성 부족
5 현업 사용자에 관련된 교육 부족이나 불편함에 따른 미사용
6 사업을 진행하기 위한 적절한 예산이나 인력 부족
- 택사노미Taxonomy는 데이터를 활용하기 위한 인사이트를 찾는 데 유용한 툴이다. 택사노미는 교육, 비즈니스, 과학 등과 같은 다양한 분야에서 사용하는 일종의 데이터 분류 시스템으로, 최근에는 대량의 디지털 비정형 데이터를 관리하는 데 널리 사용되고 있다.
택사노미는 데이터들의 내용상 유사성이나 관계를 고려해 그룹을 분류하고 체계를 만든다. 기업은 비즈니스의 목적과 사업 전략에 따 라 다양한 택사노미를 구성하고, 지속적으로 관리 · 업데이트해야 한다. 최근에는 광고나 마케팅의 DMP 데이터 서비스 영역에서도 택사노미를 많이 사용하고 있다.
다만 택사노미는 톱다운Top-down 및 중앙 집권 방식으로 구성돼 있어서 생성의 정확성은 보장하지만, 시 시때때로 변화하는 다양한 지식과 경험을 반영하지 못하는 단점이 있다. 이런 이유로 최근에는 포크소노 미Folksonmy, 즉 기존 택사노미에 사용자 누구나 자유롭게 분류 키워드를 선택하고, 구성원이 함께 정보 를 체계화해 나가는 시스템을 결합한 하이브리드 택사노미 모델을 제시했다.
대표적인 하이브리드 택사노미인 포크소노미는 분류 체계를 중앙 에서 관리하기는 하지만, 사용자가 정보를 지속적으로 제공함으로써 현장의 정보와 경험을 반영할 수 있다는 것과 사용자가 익숙한 용어 를 사용할 수 있다는 장점이 있다.














'IT' 카테고리의 다른 글
| 알고리즘이 지배한다는 착각 (0) | 2022.04.28 |
|---|---|
| 나는 메타버스에 살기로 했다 (0) | 2022.04.20 |
| 웰컴 투 인공지능 (0) | 2022.02.20 |
| 가볍게 떠먹는 데이터 분석 프로젝트 (0) | 2022.02.16 |
| 21세기 권력 (0) | 2022.01.08 |




