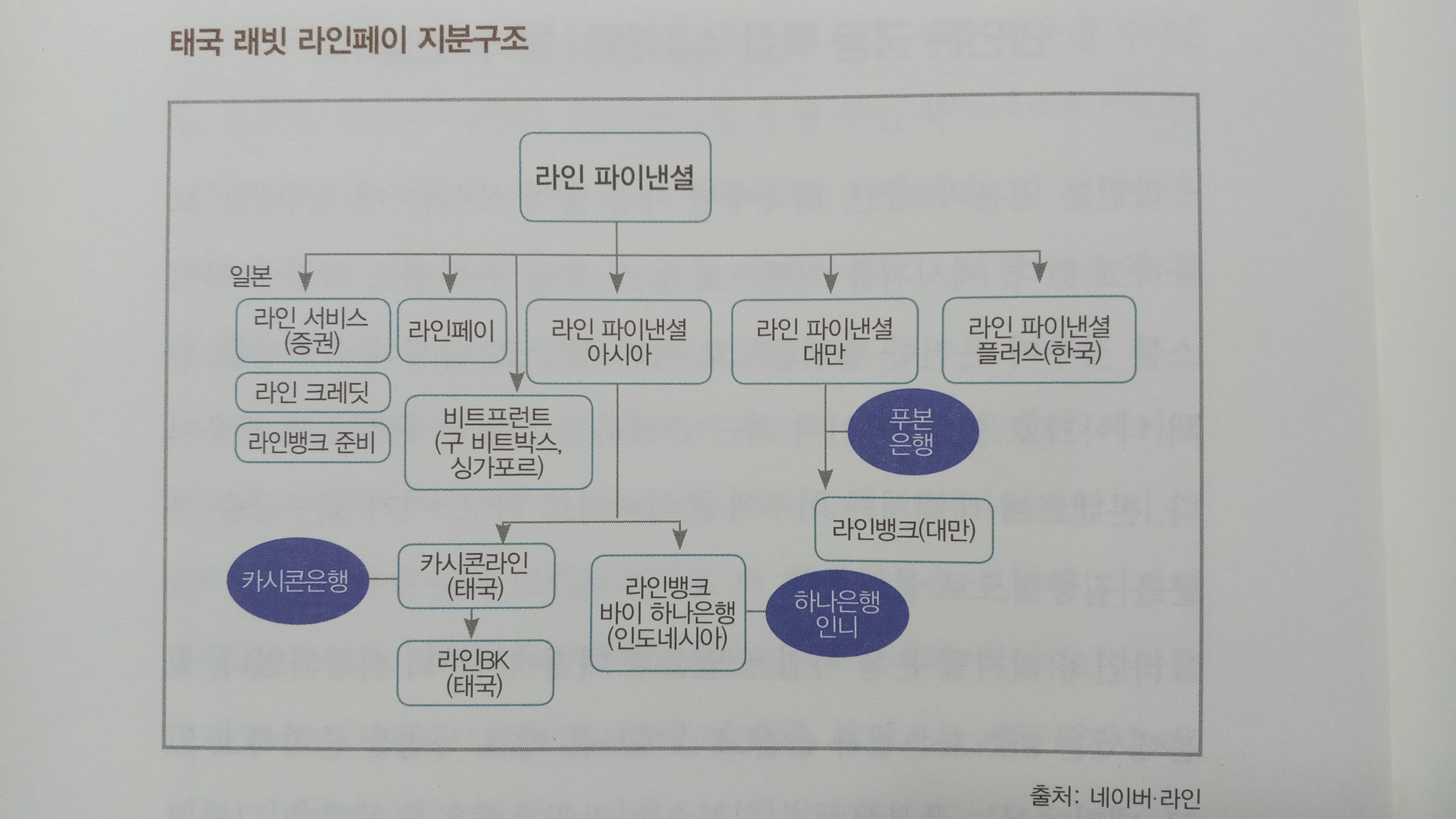
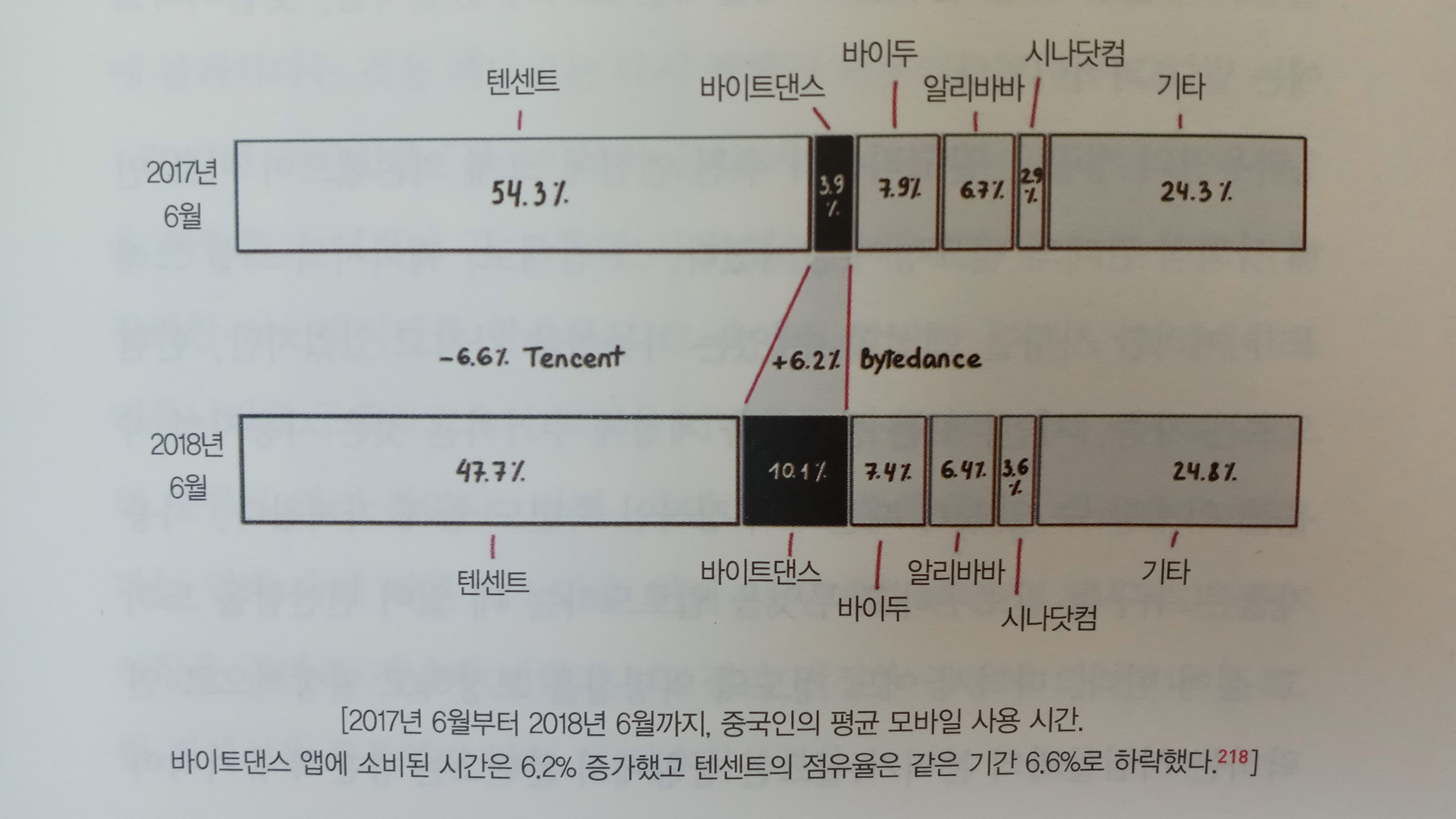
- 그랩은 말레이시아에서 출발했지만 곧바로 태국을 비롯한 주변 국가로 진출했다. 보통의 기업, 스타트업들이 국내시장에서 기반 을 확실히 다진 후에, 혹은 포화 상태에 이르렀을 때 해외 진출을 계획하는 것과 사뭇 달랐다. 안소니 탄과 후이링 탄은 일찍부터 해 외 진출을 염두에 두었다고 밝혔다. 말레이시아가 3200만 명의 인구를 가진 규모가 작은 시장이기도 하거니와 앞서 이야기했듯 교 통과 이동에 있어 동남아 전역이 비슷한 문제점을 안고 있었기 때 문이다. 그랩은 2012년 말레이시아에서 출발해 첫 해외 진출을 한 필리 핀에서 서비스를 내놓기까지 1년, 그리고 다른 아세안 4개국으로 사업을 확장하기까지 2년밖에 걸리지 않았다. 과감한 실행력으로 무섭도록 빠르게 결정을 내린 것이다. 인터넷 유저가 적고 연결성 이 상대적으로 낮은 미얀마와 캄보디아에서의 서비스 출시가 2017 년으로 늦어졌을 뿐이다. 해외시장 진출은 차량공유나 플랫폼 스타트업의 과제인 스케일 업에서 중요한 전략적 선택이다. 그랩이 제일 처음 진입한 필리핀과 베트남은 1억 명의 인구를 가지고 있으며 젊은층이 많다. 2억7000만 명 이상 살고 있는 인도네시아는 동남아 최대 시장이다. 태국은 이보다 인구 규모가 작지만 소득이나 현지인 및 외국인 수요 에 있어 뒤처지지 않는다. 서비스가 필요한 잠재 수요가 이미 넘쳐 나는 시장이다. 누구나 성장 잠재력을 파악하고 있지만, 누구나 성공하는 것은 아니다. 한국의 카카오도 해외 진출을 감행했지만 메신저 서비스로 는 성공하지 못했다. 해외시장으로의 확대, 지역 통합 전략은 그랩 성장의 원천이라 할 수 있다. - 고젝은 사업 확장을 위해 자체 개발을 하기도 했지만, 인수합병과 파트너십을 적극 활용했다. 2015년 앱 론칭 이래 엄청나게 빠른 속도로 스케일업이 이루어졌고, 서비스와 기능이 다양해진 만큼 소 프트웨어와 데이터 처리 등 기술의 양적·질적 성장이 요구되었다. 그러나 고젝은 자체 인력만으로 R&D와 기술적 지원을 감당하기가 어려웠다. 고젝에 투자한 세콰이어는 인수합병으로 해법을 찾으라고 권하 며 인도 방갈로르의 소프트웨어 엔지니어링 회사 C42와 델리의 코 드이그니션 Codeignition을 직접 소개해주었다. 2016년 고젝은 이 두 회 사를 인수하고 방갈로르에 개발센터를 세웠다. 이후에도 인도 테크 스타트업인 레프트시프트Leftshift, 피안타Pianta, 에어씨티오 AirCTO를 추가로 인수했으며, 모바일 앱과 헬스케어, AI 분야의 기술 축적을 추진하고 있다. 핀테크 시장에서 주도권을 잡기 위해 선택한 전략 역시 인수합 병이었다. 라이선스 취득과 함께 기존 사업자의 네트워크를 통해 빠르게 시장을 확대할 수 있기 때문이었다. 2016년에 엠브이커머스MVCommerce를 인수해 고젝의 모바일 지갑 라이선스 문제를 깔끔하게 해결했고, 이듬해에 핀테크 기업 카르투쿠Kartuku, 미드트랜스 Midtrans, 마판Mapan을 인수했다. 그랩페이가 인도네시아 핀테크 스타 트업 쿠도를 인수해 시장을 치고 들어오자 기업 3곳을 인수하며 맞 불을 놓은 것이다. 이후 그랩페이는 디지털 결제에서 소규모 대출 과 할부 금융에도 손을 뻗쳤고, 모카를 인수하며 POS 사업에도 뛰 어들었다. 뿐만 아니라 자고은행ago Bank의 지분도 사들였는데, 이를 발판으로 디지털 뱅킹과 대출시장에 본격적으로 진출할 예정이다. 고페이의 가치는 이미 유니콘 반열에 올라선 것으로 보고 있다. - 인수합병의 과감한 행보는 막대한 투자가 뒷받침되었기에 가능했다. 아세안 최대 시장인 인도네시아에서 입지를 굳게 다진 만큼 해외 투자자들의 펀딩이 밀려들었다. 글로벌 사모펀드인 KKR 과 워버그 핀커스, 중국의 텐센트와 JD.com, 구글이 고젝에 투자 했다. 구글의 경우 동남아 스타트업에 대한 최초 투자로 기록되었 다. 2020년에 진행된 시리즈 F(스타트업 기업이 진행하는 첫 번째 투자 유 치를 시리즈Series A라고 한다. 따라서 시리즈 F는 6번째로 진행한 투자를 의미 한다)에서는 페이스북과 페이팔이 고젝에 총 375억 달러를 투자했 다. 아세안 시장에서 고젝과의 파트너십을 통한 시장 확대를 목표 로 한 것으로 추정된다. - 파트너십은 고젝이 마찰을 최소화하면서 시장을 확대하기 위해 적극 활용한 전략이다. 라이드헤일링 시장은 어느 국가에서나 택시회사, 택시 기사와 마찰을 일으킨다. 인도네시아에는 블루버드Blue bird라는 최대 택시 사업자가 버티고 있었다. 그러나 블루버드는 소비자의 흐름이 라이드헤일링을 거부하지 못할 것임을 깨달았고, 2016년 고젝과의 협력을 발표했다. 그랩앱을 통해 택시를 예약할 수 있는 것과 마찬가지로 고젝의 고카GoCar를 통해 오토바이, 일반차량, 택시를 예약할 수 있다. - 라자다와 토코페디아보다 시장에 한발 늦게 들어온 쇼피는 어떻 게 아세안 최고 이커머스로 성장할 수 있었을까? 이커머스나 플랫 폼 비즈니스에서 '승자가 모든 것을 가져간다Winner Takes All'는 말이 경전처럼 쓰이고 있는 가운데 쇼피의 성공은 그야말로 경영학 사 례 연구로 손색이 없을 정도다. 쇼피는 거대 이커머스 업체들이 파 고들지 못한 지점을 파악하며 자신의 약점을 강점으로 전환하는 전략을 구사했다. 첫 번째 전략은 모바일 기반 최적화다. 미국과 한국이 인터 넷-PC시대를 거쳐 모바일로 이동했다면, 중국과 아세안은 PC는 건 너뛰고 바로 모바일로 점프했다. 모바일 립프로깅leap forgging(단번의 도약)이 일어난 시장에서 이용자들은 PC 기반 화면보다 모바일 앱 기반 서비스를 이용하는 게 편리할 수밖에 없다. 이커머스 플랫폼도 마찬가지다. 쇼피는 로딩 속도, 화면 크기, 한 번에 보여주는 상품의 개수, 결제 등을 소비자의 눈높이에 맞췄다. 현재 쇼피 전체 주문 건의 95%가 모바일 앱에서 이루어지고 있다. 두 번째 전략은 프로모션과 셀러 지원이다. 고객이 들어와도 살 물건이 없으면 장사가 될 수 없다. 또한 물건을 잔뜩 쌓아두고 있다. 고 해서 고객이 몰려드는 것도 아니다. 쇼피는 후발주자였기에 고 객들을 끌어모으기 위해 무료 배송과 쿠폰 발행 등 프로모션에 돈 을 쏟아부었다. 마켓플레이스 판매자들에게도 수수료를 낮춰주거 나 무료로 해주었고, 등록 절차를 간소화하는 등 그야말로 공을 들 였다. 온라인 판매가 익숙하지 않은 판매자들에게는 디지털 마케팅 기법을 적용할 수 있도록 친절히 안내해주었다. 세 번째 전략은 철저하고 깊숙한 현지화, 즉 시장이 하이퍼 로컬리제이션이다. SEA가 진출한 동남아 6개국과 대만은 모두 다른 언어와 종교를 갖고 있고, 소득 수준 차이가 크다. 즉 시장이 문화적으로도, 경제적으로도 균일하지 않다. 따라서 선호하는 색상이나 브랜드, 베스트셀러 상품이 다를 수밖에 없다. 일반적인 이커머스는 언어만 다르고 같은 포맷과 상품을 보여 주지만, 쇼피는 말레이시아, 인도네시아, 베트남, 태국 등 해외시장에 진출하면서 각각 새로운 앱을 내놓았다. 즉 1개국 1앱으로 모 두 7개의 앱을 론칭했다. 대만에서 보는 쇼피앱과 인도네시아에서 보는 쇼피앱은 언어만 다른 것이 아니라 구성 자체가 다르다. 네 번째 전략은 엔터테인먼트 마케팅을 통한 고객 참여와 록인 lock-in이다. 동남아인들의 평균 모바일 이용 시간은 1일 4시간 전후 로, 상당히 긴 편이다. 쇼피는 그들을 자신들의 앱에 묶어두는 방법 을 고민했다. 가레나 유저들이 무엇을 좋아하는지, 어떤 서비스에 환호하는지 이미 경험한 쇼피는 이를 이커머스에도 적용시켰다. 그래서 탄생한 서비스가 쇼피챗과 쇼피피드, 쇼피라이브 등이다. 쇼피챗은 라이브 채팅을 통해 소비자와 판매자가 직접 대화를 나눌 수 있도록 했고, 쇼피피드는 쇼피앱 안의 소셜미디어 역할을 한다. 쇼피라이브는 스타와 셀럽을 쇼호스트로 내세워 제품을 소개하기도 하고, 콘서트나 팬미팅을 열기도 한다. 하루에 몇 시간씩 쇼피에서 시간을 보내도 지루하지 않게 만들었다. 프로모션과 이벤트를 홍보하는 채널을 자체적으로 구축한 셈이다. 다섯 번째 전략은 디지털 통합 생태계다. 가레나는 에어페이라 는 자체 결제 시스템을 갖추고 있었고, 여기에 쇼피페이가 추가되면서 씨머니라는 금융 서비스 섹터가 만들어졌다. 스마트폰만 있으 면 쇼핑도, 게임도, 결제도 손쉽게 할 수 있다. 셀러 역시 배송과 결제 걱정 없이 쇼피 세상에 발을 들여놓기만 하면 된다. 'BNPL Buy Now Pay Later" 이라는 후불 할부 결제 시스템도 도입되었다. 쇼피와 가레 나 이용자들이 씨머니로 결제할 수 있는 한도가 더 늘어났고, 회원 들에게 맞는 금융 서비스를 제공하면서 SEA 생태계 내 시너지 효 과가 극대화되었다. 성과는 수치로 확인된다. 씨머니의 모바일 지 갑을 이용한 결제 규모는 2017년 2분기 3억 4800만 달러에서 2021년 1분기 34억 달러로 무려 10배나 증가했다. - 라인은 한국에서는 성공을 거두지 못했지만, 일본과 태국, 대만에서는 단시간에 1등 메신저 자리를 차지했다. 특히 태국에서는 모바일 포털 역할을 수행할 정도로 생활 속에 깊숙이 파고들었으며, 기업들이 가장 선호하는 마케팅 파트너로 성장했다. 라인이 태국에서 성공한 이유, 라인만의 경쟁력을 묻는 질문에 신중호 라인 최고 글로벌책임자CGO는 이렇게 답했다. “라인 해외 진출 성공 전략은 '현지화'를 넘어선 '문화화culturalization’다. 그 나라 음식을 먹고 그 나라 말을 하는 사람들의 이야기를 들 어야 한다. 내부에서는 해외 진출에 대해 '로컬리제이션Localization'이 란 말 대신 '문화화'라는 말을 만들어 쓴다." 라인은 자신들의 홈페이지에도 문화화를 공식적으로 언급했다. '보편적인 접근 방식에 기반한 세계적으로 표준화된 서비스에 안 주하기보다는 이용자를 매우 심층적으로 참여시키고, 각 지역에서 진화하기 위해 각 국가의 문화와 규범을 존중하는 것이 필수적이라 고 생각한다. 우리는 이것을 문화화라고 부른다. 라인은 현지 법인이 직접 서비스 기획부터 운영까지 총괄하는 체계를 수립하고 현지인들의 정서와 니즈에 맞는 서비스를 생산, 제공하면서 라인의 문화화를 수행하고 있다. 본사의 영향에서 벗어 나 현지 독립성을 철저히 인정하고 현지인들의 정서까지 고려한다는 점에서 로컬라이제이션을 뛰어넘는 문화화는 라인이 새롭게 정의한 개념이다. 그랩의 하이퍼 로컬라이제이션과 일맥상통하는 접 근법이라고 볼 수 있다. '쿠키런'과 '모두의 마블'은 태국 정서에 알맞다는 현지 직원들의 의견을 받아들여 론칭했는데, 결과는 대박이었다. 라인 스티커도 현지에서 10차례 이상 시안을 검토하고 태국인들만의 특유의 제스 처와 정서를 담은 모습으로 뜨거운 반응을 이끌어냈다. 라인맨 역 시 현지 직원들의 아이디어로 탄생했다. 라인의 문화화가 그 힘을 제대로 증명해냈다. - 동남아 슈퍼앱들은 플랫폼을 통해 다양한 서비스를 제공하고 있 어 겹치는 영역에서 부딪히는 것을 피할 수 없다. 슈퍼앱 5가 공통적으로 갖고 있는 영역은 디지털 결제 부문이다. 모든 온디맨드 서비스는 최종적으로 소비자가 돈을 지불해야만 실제 매출이 일어나고 사업이 유지된다. 고객을 얼마나 편리하게 그 단계까지 끌어와 최종 결제 버튼을 클릭하게 만드는가가 중요하다. 동남아 소비자들의 페인 포인트는 바로 결제 수단이다. 따라서 슈퍼앱들은 결제 수단에 매달릴 수밖에 없다. 한국에서는 대부분의 성인이 신용카드를 보유하고 있어 네이버페이나 카카오페이에 신용카드를 연결시켜 놓는 방식이 일반적이지만, 그랩페이나 고페 이는 돈을 모바일 지갑에 충전해서 사용하는 사람이 많다. 자신들 의 '페이pay'가 은행 계좌나 다름없는 것이다. 슈퍼앱들의 입장에서 페이는 단순히 여러 서비스 중 하나가 아니라 다른 모든 서비스의 매출을 이끌어내는 수단이자 자금을 모아놓는 훌륭한 저장고라 할 수 있다. - 레드오션으로 변한 디지털 결제시장에서 슈퍼앱들은 어디로 향하고 있을까? 카카오페이가 카카오뱅크로 넘어간 것과 마찬가지로 디지털 뱅크로 무대가 바뀌고 있다. 이제 기존 은행들은 슈퍼앱, 그리고 곳곳에서 태어나 성장하고 있는 핀테크 스타트업들과 경쟁 을 벌여야 한다. 한국의 카카오뱅크와 토스 같은 디지털 뱅크는 이 용자들이 공인인증서 설치부터 여러 단계를 거쳐야 하는 불편함을 해결하고, 여러 은행 계좌를 한 번에 관리할 수 있는 편리함을 제공 하면서 단시간에 금융시장의 판도를 바꾸었다. 동남아 디지털 뱅크는 여기에 더해 충분히 금융 서비스를 받고 있지 못하는 2~3억 명의 고객을 더 확보할 수 있다는 기회까지 있 다. 디지털 뱅킹 섹터는 이제 막 닻을 올린 블루오션이다. 누가 먼 저 라이선스를 받고 항해를 시작할지 지켜볼 필요가 있다. - 슈퍼앱들은 디지털 은행뿐 아니라 할부 금융, 보험 판매, 투자와 자산 관리 서비스 등에도 손을 뻗치고 있다. 파이낸셜 부문에서 가장 다양한 상품과 서비스로 포트폴리오를 구성하고 있는 슈퍼앱은 고투그룹의 고투 파이낸셜이다. 고투 파이낸셜은 개인 고객을 위한 후불 결제, 일명 BNPL 서비스부터 비즈니스에 필요한 POS 시 스템, 온라인 스토어 웹 사이트 구축 플랫폼, 페이먼트 게이트웨이 솔루션, 보험, 투자, 기부까지 다양한 서비스를 제공하고 있다. 고인 베스타시 Golnvestasi는 금을 사고팔 수 있는 금투자 플랫폼이다. - 그랩만 보더라도 그랩 파이낸셜에 그랩페이와 BNPL, 보험, 사용 금액에 따른 포인트 관리 그랩리워드가 있다. 주목할 만한 섹터는 그랩인베스트 Grabinvest다. 그랩 파이낸셜의 투자 섹터에는 오토인베 스트Autoinvest라는 프로그램이 있다. 그랩을 사용할 때마다 1달러 혹 은 2달러 등 일정 금액을 투자하도록 설계해놓으면, 그 돈이 투자 상품으로 들어가 운용되고 수익금이 다시 그랩페이 모바일 지갑으로 되돌아오는 구조다. 운영은 풀러튼 펀드 매니지먼트 Fullerton Fund Management 와 UOB자산운용이 맡고 있다. 투자에 관심이 많지만 한 꺼번에 목돈을 투자할 수 없는 젊은이들을 타깃으로 만든 상품이다. 2020년 로보어드바이저 스타트업 벤토Bento를 인수할 때부터 그랩이 추후 자산 관리 분야에 뛰어들 것이라 예견되었다. 디지털 은행과 보험 및 투자 상품 연계에 향후 개인 자산 어드바이저 서비 스까지 추가되면 그랩은 모바일에 익숙한 세대에 진정한 금융 기 업으로 인식될 가능성이 크다. 한국의 카카오뱅크와 토스처럼 말이다.
최근 각종 신문이나 증권사 보고서에서는 연일 NFT관련 내용을 소개하고 있다. 사전적으로는 '대체 불가능한 토큰(Non-Fungible Token)'이라는 뜻으로, 희소성을 갖는 디지털 자산을 대표하는 토큰을 말한다. NFT는 블록체인 기술을 활용하지만, 기존의 가상자산과 달리 디지털 자산에 별도의 고유한 인식 값을 부여하고 있어 상호교환이 불가능하다는 특징이 있으며, 자산 소유권을 명확히 함으로써 게임·예술품·부동산 등의 기존 자산을 디지털 토큰화하는 수단이 될 수 있다.
특히 2021년 초에 마이클 윈켈만(디지털 아티스트 비플)의 '에드리데이즈: 첫 5000일'이 세계적 경매회사 크리스티가 뉴욕경매에서 NFT암호화 기술을 적용하여 6930만 달러에 거래되며 화제를 불러모았다. 국내에서도 SM엔터테인먼트가 NFT관련 사업을 준비하고 있다고 컨퍼런스에서 공개했고, BTS소속사 하이브 역시 NFT사업을 준비하고 있다고 공개했다. 삼성그룹 역시 NFT 스타트업에 투자하고 있다.
NFT가 한 때의 유행이 될 것인지, 아니면 계속해서 진화하면서 가상세계와 디지털 세계에서 투자와 결제의 중요한 수단으로 발전할 것인지는 아직 미지수다. 이 책은 IT전문가 맷 포트나우와 마케팅 전문가 큐해리슨 테리가 지은 책으로 NFT의 개념과 역사, 그리고 NFT를 판매하고 구매하는 방법을 알기 쉽게 설명한 입문서이자 핸드북이다. 블록체인이나 암호화폐에 대해 잘 모르는 입문자들도 NFT를 이해하는 데 무리가 없도록 친절하고 구체적으로 NFT와 관련된 모든 현황을 정리해 주고 있다. NFT의 거래에는 암호화폐가 사용되고 있기 때문에 자칫 어렵게만 느껴질 수 있다. IT 전문가가 아니면 NFT는 발도 들여놓지 못할 영역이라고 지레 포기하기 쉽다. 하지만 모든 거래는 처음 소개될 때는 어려운 개념으로 다가오지만 결국은 일반 대중이 활용하기 쉽게 진화하기 마련이다. 모바일 결제를 생각해보면 쉽게 이해할 수 있다. 처음에는 어떻게 휴대폰으로 물건을 살 수 있을 것이라고 상상했겠는가. 하지만 지금은 누구나 휴대폰의 앱카드를 이용해서 물건을 살 수 있고, 음식을 주문하는가 하면, 모바일 결제를 이용하여 인터넷 쇼핑몰에서 쉽게 결제하는 세상이 되었다.
모든 것의 역사가 그렇지만, 특정한 것의 역사가 시작된 순간을 정의하기는 어려운 일이다. 하지만 역사상 의미있는 변화의 순간은 뚜렷하게 구분된다. NFT가 블록체인을 활용한다고 해서 최초로 블록체인이 만들어진 2008년을 NFT의 역사로 보기에는 적절하지 않다. 오히려 미술수집가를 새롭게 규정하며 미술품 수집의 저변을 넓힌 디지털아트와 같은 예술사조나, 팝아트, 사이버펑크 컬렉션 등이 NFT의 역사에서 중요한 역할을 했다.
현재 NFT가 거래되는 마켓플레이스는 수십개가 존재하며, 이곳에서 거래되는 품목도 디지털아트, 수집품, 음악, 도메인이름, 가상부동산, 디지털트레이딩카드, 인게임 아이템 등 무척 다양하다. 현재 거래되는 아이템 이외에도 희소성이 있고, 특전이 부여되는 디지털 상품은 무엇이든 NFT로 거래될 가능성이 있다. 이 책의 말미에서 전망하는 바와 같이 NFT의 장점은 NFT의 미래가 아직 정해지지 않았다는 점이다. NFT의 가장 중요한 쓰임새가 무엇이 될지는 아무도 알 수 없다. 결국 새로운 시도를 하고 리스크를 감수하는 모험가들이 새로운 NFT미래의 주도권을 잡아가게 될 것이다.
* 본 리뷰는 출판사 도서지원을 통해 자유롭게 작성된 글입니다.
- NFT를 이해하기에 앞서 비니 베이비스를 통해 사람들이 왜 수집을 하는지를 살펴본 까닭은 사람들이 비니 베이비스를 수집 했던 근본적인 이유와 사람들이 NFT를 수집하는 이유가 동일하기 때문이다. 바로 희소성 때문이다. 사람들이 무언가를 수집하는 이유에는 투자, 투기, 정서적 애착, 나만 뒤처지는 것 같은 강박감FOMO, Fear of Missing Out 등 다양한 요인이 있겠지만 결국 수 집의 핵심은 희소성이다. 무엇을 수집하는 그 이유는 결국 수집 하고자 하는 물건이 유한하기 때문이다. 그렇다면 NFT 시장은 언젠가는 무너질 수도 있을까? 솔직히 미래는 아무도 알 수 없다. 하지만 비니 베이비스 인형과 달 리 NFT는 미술계와 수집품 시장을 괴롭혀온 고질적인 문제를 해결하는 열쇠가 될 수 있다. - NFT에 발을 담그 고자 하는 수많은 브랜드, 인플루언서, 기업, 개인은 극히 소수 에 불과한 성공 사례만 보고 자신들이 제공할 수 있는 가치, 자 신들이 만들어낼 수 있는 경험, 자신들이 지금까지 쌓아 올린 브 랜드만으로 자신들도 성공적으로 NFT를 판매할 수 있을 것이 라 믿곤 한다. 그러나 안타깝게도 현실은 그렇지 않다. 오래 지 속되는 장기적인 성공을 위해서는 NFT가 다음과 같은 외적 요 소를 갖춰야 한다. * 창작자가 '왜' NET 시장에 뛰어들었는지에 대한 설득력 있는 이야기 * NET로 풀어낼 수 있는 '창작자의 명성' * NET의 '미래 가치가 계속 지속되거나 더 높아질 것'이라는 점을 보장 - NFT에는 스토리가 그 무엇보다 중요하다. 이제 NFT를 만들고자 결심했다면 그 이유가 무엇인지 깊게 고민해야 한다. 당신이 내놓을 답에 옳고 그름은 없다. 다만 깊이 생각해봐야 한다. NFT를 왜 만들려고 하는가? 동기는 무엇 이었나? 무언가 계기가 된 사건이 있었나? 그 이유를 NFT에 어 떻게 녹여낼 것이며, 대중에게는 또 어떻게 설명할 것인가? 이 이유를 잘 이용해서 존재감을 높여야 한다. 비플의 이야기는 설득력이 있었다. 비플의 브랜드 전체가 NFT 아티스트와 자연스럽게 맞아떨어졌다. 작품을 처음 NFT 로 판매하기 전까지 비플은 자신의 작품을 인쇄해 개당 100달러 이하의 금액에 판매하기도 했는데, 비플의 작품들이 처음부터 디지털 환경에서 창작된 점을 고려하면 인쇄본보다는 디지털 매 체를 통한 감상이 더 적합하다는 점도 설득력을 얻었다. 게다가 〈에브리데이즈 NFT)의 취지는 매일 꾸준하게 성장하는 창의성을 담는 것이었으므로, 비플의 작품을 소유한다는 것은 비플의 오랜 꾸준함의 일부를 소유한다는 의미를 지니기도 했다. 만약 수집가들이 당신의 NFT에 흥미를 갖게 하려면 과연 어떤 이야기를 보여주어야 할지 잘 생각해봐야 한다. - NFT와 명성 비플의 명성은 자연스럽게 쌓인 것이다. 비플은 14년 동안 인 터넷을 통해 작품을 공유해왔다. 그가 디지털 그림을 그리는 데 쓴 소프트웨어인 시네마4DCinema 4D나 옥테인렌더 OctaneRender를 배우는 것이 됐든, 매일매일 꾸준히 노력하며 성장하는 것이 됐든, 비플은 다른 사람들 역시 더 노력하게끔 자신감을 불어넣어 주었다. 한번 쌓인 명성은 오래 간다. NFT를 제작한다면 무엇이 그 NFT를 유명하게 해줄 것인지, 각자의 이야기와 어떻게 맞닿 아 있는가를 고민해야 한다. - NFT는 미래에도 그 가치가 보장될까 사람들이 비플의 NFT를 구입하는 것은 장래성에 대한 확신이 있기 때문이다. 우리는 비플이 앞으로도 에브리데이즈>를 계속 그릴 것임을 믿어 의심치 않으며, 수집가들도 비플이 오랫동안 작품 활동을 이어갈 것을 알기에 안심하고 비플의 작품을 구매한다. 이처럼 NFT의 장래성을 시장에 각인시키는 것은 매우 중요하다. - 이더리움 기반 NFT의 경우 NFT의 스마트 컨트랙트는 42자리 이더리움 주소를 갖는다. 아무나 블록 익스플로러(블록체인에서 일어나는 모든 거래 내역을 볼 수 있는 온라인 도구)에 가서 NFT의 주소를 검책 창에 넣으면, 그 NFT의 스마트 컨트랙트를 쉽게 찾을 수 있다. 또한 블록 익스플로러는 NFT가 처음 만들어진 주소도 보여줄 것이다. 만약 스마트 컨트랙트의 주소가 작가의 주소와 일치한다면 그 작품은 진품이다. 만약 일치하지 않는다면 그 NFT는 진품이 아니며 NFT에 설명된 작가가 그린 것이 아니다. 이게 전부다. 불확실성은 일절 없으며 전문가도, 말장난도 필요 없다. 오픈시 마켓플레이스에서도 누가 NFT를 만들었는지를 확인 할 수 있다. NFT 페이지를 내려보면 거래이력Trading History 란에 서 NFT를 만든 사람을 확인할 수 있다. NFT의 작가가 인증받 은 계정이거나 NFT의 거래 이력 상의 주소가 작가의 주소와 일 치한다면 그 NFT는 진품이다. - 사람들이 로건의 NFT를 산 이유는 로건이 유명한 유튜버이고 그의 인기가 앞으로도 점점 높아져서 NFT의 가격도 함께 높 아질 것으로 믿었기 때문일까? 아니면 이 박스 브레이커 NFT)의 가격이 더 유명한 수집품인 포켓몬 카드만으로도 충분히 설명될 수 있는 걸까? 로건의 NFT는 진정한 NFT가 아니라 단지 NFT의 형태로 발급되고 판매된 포켓몬 추첨 티켓에 불과하다는 의견도 있다. 로건의 NFT의 가격이 처음 판매 직후 폭락했음을 고려하면 이 의견은 더욱 설득력을 얻는다. 1ETH의 가격에 판매된 박스 브레이커 NFT)는 현재 마켓플레이스에서 원래 가격의 1/10, 심지어 가끔씩은 1/100의 가격에 판매되고 있다. 우리는 여기서 무엇을 배울 수 있을까? * 많은 창작자가 자신의 NET의 가치를 높이기 위해서 실물 상품을 이용하고있다. 대부분의 NFT 마켓플레이스는 잠금 해제 콘텐츠나 특전을 통해 NET 판매에 실물 상품을 포함하는 것을 허용하고 있다. 이러한 기능을 이용하면 이미 일정 가치가 있는 것을 NFT에 더함으로써 NFT의 가치를 높일 수 있다. * NFT의 가치는 변동이 크다. 본 챕터에서 다뤘듯이 NFT에 사용된 기술은 사기나 위조, 공급량 조작을 방지할 수 있다. 하지만 개별 NFT에 대한 수요는 언제든지 변할 수 있다. 그리고 로건의 NFT의 사례에서 볼 수 있듯이, 잠금 해제 콘텐츠나 특전을 통해 제공된 실물 상품이 다 사용되고 나면 NFT의 디지털 부분의 가격은 실물 상품의 가치만큼 떨어지게 된다. - 앤디 워홀이 제시한 예술의 본질에 대한 신선하고 새로운 방식은 NFT에도 많은 영향을 미쳤다. 앤디 워홀은 팝아트의 창시자가 아니었음에도 순식간에 팝아트의 대표주자가 되었다. 팝아 트는 예술 감상을 대중화하는 데 큰 영향을 미쳤다. 팝아트 작품의 주제가 대중문화의 일부 요소를 다뤘던 까닭에 일반인들도 작품의 소재를 바로 인식할 수 있었기 때문이다. 아무런 사전 지식 없이도 소비 경험만 있다면 충분했다. 브릴로 수세미 Brillo SoapPad를 사거나, 일간 신문의 만화를 읽거나, 영화를 보는 것만으로 사람들은 팝아트를 감상할 수 있었다. - 팝아트가 등장하지 않았다면 오늘날처럼 다양한 소득 수준의 수많은 미술 수집가가 존재하지 못했을 것이며, 무엇인가를 예술작품으로 인식하는 우리의 기준 또한 지금보다 훨씬 편협했을 것이다. 같은 맥락에서, 새롭게 등장한 NFT 커뮤니티나 NBA톱숏, 로컨 폴 박스 브레이커 Logan Paul Box Breaker, 크립토키티, 비플의 NFT처럼 오늘날에는 팝아트로 분류될 수 있는 디지털아트 수집품도 팝아트 없이는 존재할 수 없었을 것이다. - NET 초기 시절에 NFT를 민팅하기 위한 유일한 방법은 스마트 컨트랙트를 직접 프로그래밍하는 것이었다. 스마트 컨트랙트란 본질적으로 이더리움 네트워크상에서 작동하는 프로그래밍 코드다. 그리고 이더리움 네트워크는 전세계 수천 대의 컴퓨 터로 구성된 거대한 컴퓨터라고 할 수 있다. 스마트 컨트랙트는 자바스크립트(JavaScript, 웹브라우저 프로그래밍 언어 중 하나)에 기반한 이더리움의 네이티브 프로그래밍 언어인 솔리디티 Solidity로 작성된 컴퓨터 프로그램이다. 스마트 컨트랙트를 작성하고 나면 정상적으로 작동하는지 확 인한 후 이더리움 네트워크에 배포deploy 하게 된다. 여기서 ‘배포’과정으로서 이 경우에는 이더리움 블록체인상에 올리는 것을 의미한다. 한 번 블록체인에 배포된 스마트 컨트랙트는 수정할 방 법이 없으므로 테스트는 매우 중요하다. 모든 NFT는 각기 개별적인 스마트 전트랙트이므로, 블록체인에 스마트 컨트랙트를 배포할 때마다 가스피가 든다. 이제는 오픈시나 다른 NFT 마켓플레이스의 등장으로 더 이상 스마트 컨트랙트를 직접 작성하지 않아도 됨은 물론 프로그래밍 코드를 작성하는 방법(코딩)이나 테스트 및 배포를 하는 법도 알 필요가 없어졌다. NFT의 모든 구성 요소를 이미 만들었으므로, 실제 민팅 과정은 제법 간단하다. - 오늘날 NFT를 마케팅한다는 것은 팟캐스트 마케팅과 매우 유사하다. 팟캐스트 하나를 녹음해서 스포티파이나 애플뮤직에 올리기는 쉽지만 재미난 홍보 아이디어가 없다면 아무도 그 팟 캐스트를 발견하지 못할 것이다. 알고리즘은 없다. 스스로 팔로어를 만들어야 한다. 핵심 고객 은 누구이며, 당신만의 팟캐스트는 어떤 방향으로 운영할지를 결정해야 한다. 청취자에게 어떻게 다가가야 할까? 어떻게 하면 사람들이 당신의 팟캐스트를 듣게 할 수 있을까? 청취자들이 팟 캐스트를 다시 듣고 싶게 하려면 팟캐스트 콘텐츠를 통해 어떤 가치를 제공해야 할까? 당신의 팟캐스트는 핵심 청취자들이 그들의 친구들과 함께 듣고 싶어하는 팟캐스트인가? - 우리는 팟캐스트가 모방의 함정에 빠지는 것을 자주 본다. 한 팟캐스트가 성공을 거두면 다른 팟캐스트들은 성공한 팟캐스트를 똑같이 따라 하기 바쁘다. 사라 쾨닉 Sarah Koenig 이 진행하는 수사 저널리즘 시리얼Serial) 팟캐스트의 시즌1에서는 1999년 에 18살의 나이로 살해된 한국계 미국인 여고생의 살인사건을 다뤄 큰 화제를 모았다. 시리얼>을 필두로, 실제 범죄를 다룬 팟캐스트는 어느새 주류 장르로 자리 잡았고 시리얼〉과 대동소 이한 수많은 아류작은 흘러넘칠 정도로 많아졌다. NFT도 별반 다르지 않다. 특히 디자인 콘셉트를 완전히 베끼는 경우가 다반사다. 포켓몬 카드의 콘셉트을 그대로 모방한 NFT가 수두룩하며, 8비트 콘셉트(80년대 비디오 게임 그래픽 스타일)의 크립토펑크 프로젝트가 성공을 거둔 이후 마켓플레이스에는 8비트 스타일 NFT 프로젝트가 쏟아졌다. 물론 모방 역시 어느 정도 먹힐 수도 있다. 하지만 모조품이 원본을 넘어설 수 없듯 남을 베낀다는 것은 결국 수집가 커뮤니티의 성장에 스스로 한 계를 만드는 것이 된다. 나만의 수집가 커뮤니티를 구축하는 데에는 본보기도 없고 지름길도 없다. 누구에게나 어려운 일이다. 큐해리슨의 NFT에 는 주효했던 방식이 맷의 NFT에는 먹히지 않을 수도 있고 반대 의 경우도 얼마든지 있을 수 있다. 따라서 NFT 마케팅 전략은 수집가 커뮤니티를 구축하는 데 집중해야 한다. 수집가 커뮤니티란 3명이 될 수도, 3,000명이 될 수도 있다. 최종 목표는 당신 작품의 초기 수집가임을 자랑스럽게 여길 진짜 팬을 만드는 것이다. 노력을 통해 기존 팬이 새로 운 NFT 수집가가 될 수도 있으며, 이들로부터 새로운 고객에 대 한 힌트를 얻을 수도 있다. 수집가 커뮤니티를 구축하는 데 집중 함으로써 일회성 NFT 판매를 위한 단기 전략이 아닌, 장기적인 성장 전략을 완성하게 될 것이다. 한 번 먹혔던 작전이나 수법은 보통 두 번 통하지 않는다. 하지만 무엇을 해야하는지에 대한 본질은 변치 않는다. - NFT를 사는 이유는 여러 가지가 있는데, 그중 일부는 사람들이 실제 미술품을 사는 것과 관련이 있기도 하다. 그 이유로는 다음과 같은 것들이 있는데 이 이유들은 서로 뚜렷하게 구별되지는 않으며, 어떠한 NFT를 구 매할 때 여러 개의 이유가 동시에 작용하기도 한다. (의미, 쓰임새, 투자, 수집, 명성 등) - NFT에 대한 투자를 고민할 때 는 다음 질문을 떠올려보자. * 이 NFT를 만든 것은 누구인가? * 장래성이 있고, 고유하고 독창적인 비전이 담겨 있는가? * 이 NFT 프로젝트의 용도 또는 쓰임새는 무엇인가? * 많은 사람이 참여하고 싶어할 만한 프로젝트인가? * 담당자가 당신의 질문에 신속하게 응대하는가? * 프로젝트를 수집하는 다른 사람들은 누구인가? * 대규모 컬렉션을 보유한 수집가가 참여하고 있는가? * 기관 투자가 있었는가? - 오늘 첫 NFT를 사게 된다면 당신은 전 세계에서 NFT를 수 집한 최초의 수백만 명 안에 들게 될 것이다. 이것은 분명 적잖 은 의미가 있다. 트위터에 처음 모였던 수백만 명의 사람들은 다 른 사람들보다 먼저 팔로어를 모을 기회를 얻었다. 아직 인스타 그램이 사진 공유 애플리케이션에 불과하던 시절의 최초의 인 스타그램 사용자 수백만 명도 남들보다 앞설 기회를 얻었다. 킴 카다시안이 인스타그램으로 수십억 달러 규모의 화장품 사업을 일굴 줄 누가 알았겠는가? 초기 NFT 수집가가 된다는 것은 이후에 참여하는 수집가들은 가질 수 없는 기회를 얻게 됨을 의미한다. 멋진 NFT 컬렉션을 큐레이션할 수 있는 능력이 미래에는 하 나의 어엿한 사업이 될 수도 있다. 좋은 NFT를 선별하는 작업 에 시간과 노력을 들이고 싶지 않은 NFT 수집가들은 다른 누군 가의 컬렉션을 통째로 사기도 할 것이다. 2차 시장에서 NFT를 고르는 대신에 마음에 드는 다른 사람의 컬렉션을 찾아서 지갑을 통째로 사오는 손쉬운 방법을 택하는 것이다. 마치 사람들이 아이들의 포켓몬, 유희왕, 매직 더 개더링 덱을 통째로 사오는 것처럼 말이다. 특히 2021년, 2020년 혹은 그 이전의 거래 기록 을 갖는 지갑을 소유하는 자체도 가치를 갖게 될 것이란 점에서, 장담컨대 이러한 일들은 분명히 현실이 될 것이다. 모든 사람이 샌드박스에서 가장 많은 LAND를 보유한 웨일 샤크나 거액에 비플의 에브리데이즈>를 구매한 메타코 븐(Metrakoven과 같은 NFT 고래가 될 수는 없다. 하지만 다른 방식으로 유명한 수집가가 될 수는 있다. 그리고 이때 NFT 수집을 시작하기에 가장 좋은 방법은 무료 NFT다. - 호위 테스트를 기준으로 미국증권거래위원회는 ICO도 증권 거래에 해당한다고 판단했다. 1. 토지 매수인은 돈 또는 암호화폐(어떠한 가치를 가진 것)를 투자함 2. ICO는 하나의 기관 혹은 ICO의 대상이 되는 암호화폐를 만들고 운영하고 마케팅한 집단이 주관하며 따라서 공동사업이 존재한다고 볼 수 있음 3. 구매자는 ICO에 대한 투자로부터 수익을 기대함 4. 수익은 해당 기관 혹은 공동사업을 운영하는 집단의 노력을 통해 창출됨 - 이는 ICO가 미국증권거래위원회의 증권거래 규정을 따르거나 별도의 의무 사항이 있는 규제 레귤레이션 DRegulation D와 같 은 예외 조항을 이용해야 한다는 것을 의미한다. 미국증권거래 위원회는 일부 사기성 ICO에 철퇴를 가하는 한편, 비트코인과 이더리움을 제외한 대부분의 암호화폐는 증권에 해당한다고 발 표했다. 이 엄청난 발표는 ICO는 물론 전체 암호화폐 시장을 위축시켰고, ICO가 미국 투자자들이 참여할 수 없는 해외로 옮겨 가도록 만들었다. 2017년의 열풍을 지키지 못한 2018년의 암호 화폐 시장은 큰 불황을 맞이했고 불황은 이후 수년간 계속되었다. - 암호화폐 업계의 대다수는 NFT 는 증권이 아닌 것으로 결론 날 것으로 보고 있다. 하지만 미국 증권거래위원회는 NFT에 대해서 어떠한 지침도 제시하지 않은 상태이며, NFT가 증권으로 규정될 가능성에 대해서도 대비해야 한다. 따라서 호위 테스트를 사용해 해당하는지 살펴보자. 1. NFT의 구매자가 돈 또는 암호화폐(어떠한 가치를 가진 것)를 투자함 2. NFT와 관련된 공동사업은 거의 없음. 대신 대부분의 NFT는 디지털 미술품의 한정판이거나, 수집품이거나, 인게임 아이템과 같은 쓰임새를 갖고 있음 3. NFT는 이익을 기대하는 투자 목적으로 구매하기도 하고 구매자의 개인적인 목적이나 컬렉션을 완성하기 위한 용도로 구매하기도 함 4. NFT의 가치를 높이는데 제3자가 관여하는 경우는 거의없음 확실한 답은 없으나 NFT는 대체 가능한 일반 암호화폐보다 예술품이나 수집품에 가깝다. 만약 NFT의 공급이 급격히 증가하거나 에디션의 수가 많이 늘어난다면 이는 대체 가능한 토큰에 가까워지며 대체 불가능한 토큰과 대체 가능한 토큰 사이의 경계가 모호해진다. 판매자뿐만 아니라 거래소 또한 NFT가 증권으로 규정될지에 대해서 관심을 가져야 한다. 만약 거래소가 증권거래 기능을 제공한다면 미국증권거래위원회에 사업 내용을 신고하고 미국증권거래위원회의 규정을 준수해야 하기 때문이다. - NFT의 미래는 밝다. 현재는 과소평가된 디지털아트가 향후 미술계를 장악할 것이기 때문이라기보다는 비록 저자들은 그렇게 믿 고 있지만), NFT가 미래에 모든 사람에게 영향을 미칠 디지털 경 제로 이어지는 다리 역할을 수행할 것이기 때문이다. 오늘날 이미 일부 분야에서는 그러한 역할을 수행하고 있기도 하다. NFT를 단지 투기 목적의 예술 자산으로 바라보는 것은 수많은 NFT의 미래 효용을 간과한 편협한 시각에 불과하다. 우리는 머지않아 NBA 시즌 티켓부터 전 세계에 몇 대 없는 벤츠 한정판에 이르기까지 세상의 모든 것들이 NFT화되는 상황을 보게될 것이다. 이를 염두에 두고 NFT의 미래를 논할 때 반드시 다뤄야 할 세 가지 영역에 대해서 살펴보자. * 메타버스(The metaverse) * 비담보가능자산(Non-bankable assets) * 디지털 지갑(digital wallets) - NFT가 메타버스에 적합한 또 다른 이유는 많은 사람들이 이러한 디지털 자산을 축적하기 시작했기 때문이다. 그리고 사람들 은 자연스럽게 자신이 구입한 상품을 누군가에게 보여주고 싶은 욕구를 갖게 된다. 그중 하나로, 비플의 에브리데이즈: 5000일 Everydays: The First 5,000 Days NFT>를 6,900만 달러가 넘는 금액에 구입한 메타코벤(MetaKoven, 싱가폴 기반의 블록체인 투자자. 본명은 비그네시 순다레산(Vignesh Sundaresan)이다)은 NFT를 디센트럴랜드와 같은 메타버스에서 관람할 수 있는 디지털아트 갤러리로 바꾸려 하고있다. - 사람들은 여러 가지 이유로 물건을 수집한다. 하지만 모든 수집가들이 품는 공통적인 욕구는 바로 자신의 컬렉션을 다른 사람들에게 보여주고 싶어한다는 것이다. 디지털 자산은 디지털 환경에서 전시되어야 한다. 메타버스는 가상 갤러리, 온 라인 비디오게임, 가상 지하 아지트, 혹은 우리가 아직 상상조차 할 수 없는 가상공간의 형태로 우리의 NFT를 전시하는 공간이 될 것이다. - 비담보가능자산이란 무엇일까. 미술품, 골동품, 클래식 자동 차, 보석과 같은 희귀하고 비싼 수집품, 부동산, 저작권, 특허, 상표와 같은 지식재산권에 속하는 자산은 은행에서 받아주지 않 는다. 이와 같은 유형의 자산은 쉽게 거래할 수 있는 시장이 존 재하지 않아 비유동적이고, 큰 자본의 투자가 필요하며, 자산을 거래하거나 가치를 결정하기 위해 중개인을 필요로 하는 경우가 많으므로 은행에서 받아주지 않는다. 20년 후 미래를 예측해보면, NFT의 가장 일반적인 용도는 높은 확률로 디지털아트와는 아무런 관련이 없을 것이다. 그보 다는 NFT의 스마트 컨트랙트를 활용한 물리적인 재화나 지식 재산권의 토큰화가 NET의 가장 주된 용도로 자리 잡을 것이다. 토큰화를 통해 어떠한 자산을 부분적으로 소유할 수 있게 되면 이는 구매자가 늘어나고 전통적인 비담보가능자산에 유동성이 생기는 결과로 이어지게 된다. 유니스왑이 시가 총액이 작은 암호화폐 토큰의 유동성 을 만들어냈듯이 NFT는 비담보가능자산의 유동성을 만들어낼 수 있다. 유니스왑은 대표적인 탈중앙화decentralized 암호화폐 거래 소 중 한 곳이다. 코인베이스 프로Coinbase Pro 나 바이낸스Binanc-와 같은 중앙화된 거래소에서는 판매자가 특정한 암호화폐를 판매 하고자 하는 가격을 보통 비트코인이나 이더리움 단위로 수량을 제시한다. 이를 매도 호가 ask price라고 한다. 마찬가지로 구매자도 그 암호화폐를 어떠한 가격에 얼마나 구매하고 싶은지를 제시한 다. 이것을 매수 호가 hid prite라고 한다. 매수 호가와 매도 호가가 일치할 때 암호화폐가 거래된다. 유니스왑과 같은 탈중앙화 거래소에서는 매수자와 매도자 사 이가 아닌 매수자와 토큰 풀 사이에서 거래가 이루어진다. 예 를 들어 AMP 토큰을 구매하고자 할 경우, 중앙화된 거래소에서 는 내가 구매하려는 가격과 수량만큼의 AMP 토큰을 판매하고 자 하는 매도자를 만나지 못하면 거래가 성사되지 않는다. 그에 반해 유니스왑에서는 유니스왑의 이더리움 풀에 이더리움을 송 금하면 유니스왑의 AMP 토큰 풀에서 AMP를 받게 된다. 이때 AMP 토큰의 유동성은 유니스왑에 토큰을 스테이킹 saking 하는 사용자들을 통해 공급된다. 스테이킹은 예치와도 비슷한데, 유니스왑은 사용자들이 스테이킹한 토큰을 거래에 사용할 수 있으며 이렇게 모인 토큰 풀이 시장을 형성한다. 토큰을 스테이킹한 사용자들은 그 대가로 유니스왑이 거래마다 부과하는 거래 수수 료의 일정 퍼센트를 받는다. 토큰을 수개월에서 수년 동안 장기 보유하고자 하는 토큰 보유자들도 스테이킹을 통해 새로운 수익 흐름을 확보하게 되는 것이다. | 유니스왑은 이 모든 복잡한 과정을 심리스하게 처리해내며 시가 총액이 작은 토큰에서부터 시가 총액이 큰 토큰에 이르기 까지 유동성을 만들어내는 데 성공했다. 중앙화된 거래소는 보 통 거래량이 높은 암호화폐를 선호하므로 거래량이 낮은 암호화 폐는 상장되지 못하는 경우가 많은데 실제로 유니스왑에서 거래 되는 토큰 중 상당수는 중앙화된 거래소에서 거래되지 않는 토큰인 경우가 많다. - 액센추어는 비담보가능자산의 문제점을 다음과 같이 정리했다. 비담보가능자산의 내재 가치는 해당 자산의 기존 시장 밖에서는 이용하기 어려우므로 담보로서 많은 제약이 있었다. 문서화된 거래 내역의 부재, 낮은 신뢰도, 낮은 가격 투명성, 높은 거래비용, 낮은 유동성 등의 이유로 인해 금융회사들은 비담보가능 자산을 포트폴리오. 자산에 포함하는 데 소극적이다. - 어떤 비담보가능자산이라도 NFT로 만드는 건 간단하다. 대출용 담보로 쓰지도 못하고 쉽게 처분하기도 어려웠던 자산을 NFT화하여 유동성을 확보해 자산가들에게도 새로운 기회를 열어줄 것이다. 하지만 사람들이 과연 비담보가능자산의 NFT를 구입하려 할까? 액센츄어 산하의 오브리움 리서치 obrium research 의 연구 결과에는 다음과 같은 내용이 있다. '열정투자(Passion investment, 투자자 본인이 열정을 갖는 비전통적 자산에 대한 투자로서, 투자 대상을 소유하는 자체를 즐기며 시간이 지남에 따라 해당 자산의 가치가 오르면 수익을 얻을 수 있는 투자를 뜻한다)의 가치 상승률은 지난 15년간 전 세계 주식 시장의 상승률을 뛰어넘었으며, 같은 기간 MSCI World 지수(모건스탠리캐피털인터내셔널사가 발표하는 세계 주가지수)보다도 65% 빠르게 성장했다.
- 데이터는 새로운 석유 자원data is the new oil 이라는 식으로 비유하는 경우가 있는 데, 이런 생각을 도입해 보자. 새로운 유전이 필요하다면 석유를 찾는 일과 유전이 어떻게 생겼는지를 이해하는 일에 최대한 초점을 맞춰야 한다. 나중에 생각해도 될 시추 장소를 미리 감안해 가면서 세계 최고 수준의 석유 시추 장비를 구입하는 일 부터 하지는 않을 것이다. 이런 원리를 데이터에도 동일하게 적용할 수 있다. 시추 - 모든 인공지능 프로젝트에서 기억해야 할 가장 중요한 두 가지 아이디어는 다음과 같다. (1) 수익은 여러분이 어떤 행위를 해야만 나온다. 행위는 하지 않은 채 분석만 하면 비용만 들 뿐이다. 일부 분석이 완료될 때 수익을 얻는 게 아니라, 적절한 사업 행위를 수 행할 때 수익을 얻는다. 분석이 수익 창출의 원동력이 될 수는 있지만 회계라는 관점 에서 볼 때 분석은 비용 계정에 해당할 뿐이다. 분석이 비용이 되게 하는 일을 멈추고 좋은 사업 행위를 취하는 데 도움이 되게 할 때만 분석이 투자가 된다. (2) 성공하려면 개별 부분이 아닌 전체 시스템에 집중하자. 여러분의 고객은 시스템의 개 별 부분을 볼 수 없다. 예를 들어, 고객은 여러분이 사용하는 머신러닝 알고리즘에 대해 신경 쓰지 않는다. 고객은 결과에만 관심을 둘 뿐이며, 그 결과는 시스템이 전 체적으로 얼마나 잘 작동하는지에 달려 있다. - 사업상의 결정을 내리기 위해 데이터 분석법을 더 잘 이해해야 한다는 생각이 든다면, 그것은 여러분에게 분석법에 관한 지식이 부족해서 생기는 문제가 아니라 데이터 분석법을 잘 아는 전문가와 의사소통이 잘 안 되어서 생기는 문제인 것 이다. 인공지능 프로젝트를 관리하기 위해 알아야 할 지식은 인공지능 관련 개념을 사업에 연계 하는 방법이다. 즉, 다음 질문에 답할 수 있으면 그만인 것이다. ? 인공지능으로 무엇을 할 수 있으며 사업에 어떻게 이용할 수 있는가? ? 어떤 유형의 인공지능 프로젝트부터 시작해야 하나? ? 인공지능이 사업에 얼마나 도움이 되는지를 측정하려면 어떻게 해야 하는가? ? 인공지능 프로젝트를 어떻게 관리해야 하는가? ? 부족한 자원은 무엇이며 자원을 최대한 잘 배정하려면 어떻게 해야 하는가? - 여러분이 취할 수 있는 행위를 찾으려면 반드시 적절한 규모로 이뤄진 조직 을 선택해야 한다. 그런데 스무 가지가 넘는 선택지가 나온다면 여러분이 지나치게 세분화했기 때문일 것이다. 인공지능을 의사결정 지원 시스템의 일부로 사용하는 일에 대해 논의할 때에 부딪히게 될 위험성으로는 그 일에 너무 깊이 빠져드는 경우를 들 수 있다. 고위 경영진을 위한 의사결 정 지원 시스템의 일부로 인공지능을 적용하는 경우라면 여러분은 조직에서 일하는 각 개 별 작업자가 취할 수 있는 행위를 분석해서는 안 되고 고위 경영진이 수행하는 행위를 분 석해야 한다. 인턴이 입사한 첫날에 취할 수 있는 행위를 분석하지 말자. - 제품에 인공지능 기능이 들어 있다고 해서 제품을 특별하게 여겨 구매하는 사람은 거의 없다. 핵심 질문은 “제품이 고객에게 제공하는 가치는 무엇인가?” 이다. “우리는 인공지능을 사용한다” 라는 말이 마케팅 · 자금 조달 기법으로 여겨지던 때도 있었 지만, 그런 시절은 끝났다. 시간이 흐르면 인공지능은 오늘날 자동차에서 엔진이 작동하 듯이 자율형 제품에서 핵심 역할을 맡게 될 것이다. 인공지능 없이는 어디로도 갈 수 없게 되는 것이다. 그러나 대부분의 자동차 구매자는 특정 엔진에 관심을 두기보다는 자동차를 타고 한곳에서 다른 곳으로 갈 수 있게 하는 이동성에 더 관심을 둔다. - 완전 자율 시스템의 예로는 룸바 같은 진공 청소 로봇을 들 수 있다. 이 경우에는 진공 청소기로 방 전체를 청소해야 한다. 진공 청소기와 관련성이 있는 영역 행위는 “어디로 가야 하고 어떤 장소를 피해야 하는가?” 이다. 인공지능을 사용해 환경을 탐색하는 기능을 해당 장치에 장착할 수 있다. 이러한 인공 지능은 정교한 항법 시스템에서 상대적으로 간단한 연산 장치에 이르기까지 다양할 수 있다는 점에 유의하자. 로봇 청소기는 인공지능을 사용해 방에 놓인 가구들의 배치 상태 를 학습하고 해당 배치 상태가 바뀐 내용을 인식할 수 있다. 또한 배터리 용량이 클수록 방 구조를 더 정교하게 파악해 처리할 수 있으므로 시간 집약적인 시행착오 접근 방식을 사용하여 장애물을 파악한 다음에는 장애물을 쉽게 피할 수 있다. 용량이 더 큰 배터리라는 사례를 통해 우리는 인공지능 알고리즘을 선택하는 일보다. 전체 시스템을 구성하는 방법이 더 중요하다는 점을 알 수 있다. 몇 년 전까지만 해도 크 게 개선된 인공지능 탐색 기능에 많은 시간과 비용을 소비하기보다는 차라리 고용량 배터리를 추가해 작동 시간을 늘리는 편이 더 수월하고 가성비가 좋았다. 완전 자율형 제품이라고 하는 맥락에서 볼 때, 제품이 취할 수 있는 행위뿐만 아니라 일부 행위와 결과가 바람직하지도 않고 허용되지도 않는다는 점도 고려해야 한다. 여러분은 룸 바가 계단을 알아서 내려오는 기능이 있는 값비싼 로봇 청소기가 되기를 바라지는 않을 것이다. - 인공지능 프로젝트 난이도를 추정할 때는 다음 고려 사항들에 유의하자. ? 필요한 데이터를 수집하는 데 필요한 시간을 고려하자. ? 데이터 크기에 알맞은 인프라를 갖췄는가? 빅데이터 프레임워크가 필요한가? ? 대규모 데이터셋을 사용하는 경우에 데이터를 처리하고 인공지능 알고리즘을 훈련하는 데 필요한 시간을 고려하는 일을 잊지 말자. ? 팀이 이 사용 사례를 다루는 데 필요한 모든 기량을 갖추고 있는가? 기량 간에 격차가 있다면 무엇인가? (팀 리더는 팀의 지식 격차를 알고 있어야 한다.) ? 프로젝트가 기술적으로 가능하다는 점이 확실한가? 여러분은 제안된 인공지능 기반 방법들을 팀이 구축하게 할 생각이 들 만큼 충분히 이해하고 있는가? 또는 프로젝트 가 가능하다고 여길 만큼 여러분이 인공지능 분야를 잘 알고 있는가? - 인공지능 프로젝트를 실행할 때 피해야 할 함정 중에 흔한 게 몇 가지 있다. 중요한 함정 들 중에 일부를 예로 들면 다음과 같다. ? 감지 · 분석 · 반응 루프 중에 반응 부분을 담당하는 조직에 속한 행위자와 소통하지 않거나, 심지어 인공지능 프로젝트가 순조롭게 진행될 때까지 그들과 전혀 함께 일하지 않는 것 ? 다른 프로젝트나 조직의 사용 사례(및 지표)를 가져다 쓰는 일 ? 온갖 신문의 1면을 장식할 수 있을 만큼 유행하는 인공지능 프로젝트들을 진행하는 일 ? 지속적으로 우위에 설 수 있게 할 만한 도구를 사서 쓸 수 있다고 믿거나, 더 나아가서 온갖 도구를 다 사서 쓸 수 있다고 믿는 일 ? 분석한 내용을 아무렇게나 데이터 속으로 던져 넣으면서 성과가 나오기를 바라는 일 ? 분석 결과 대신에 ‘직감’을 바탕으로 진행해야 할 프로젝트를 선정하는 일 - 기술지표에는 머신러닝 알고리즘이 이러한 지표의 값을 쉽게 최적화할 수 있는 속성이 있 다. 이러한 속성은 본질적으로 수학적이고 고도로 기술적이며 일반적으로 사업과 관련이 없다. 예를 들어, 기술지표의 일반적인 속성 중 하나는 '미분 가능' 이라는 것이며 인공지 | 능 및 머신러닝 맥락에서 사용되는 많은 최적화 알고리즘은 지표를 미분할 수 있어야 한 다는 것이다. 안타깝게도 사업지표들이 반드시 미분 가능하지는 않다. 그렇기 때문에 많 은 머신러닝 및 인공지능 알고리즘에서는 곧바로 사업지표를 사용할 수 없다. - 머신러닝 파이프라인의 경직화 인공지능 프로젝트와 그 밖의 소프트웨어 프로젝트에 공통인 문제 외에도 자체 문제가 있다. 이러한 문제 중 하나는 머신러닝 파이프라인의 유지보수 비용이다. 인공지능 프로젝 트 비용에서 가장 큰 비율을 차지하는 일 중 하나는 머신러닝 파이프라인을 빠르게 변경 하기 어렵고 변경하는 데 큰 비용이 든다는 점이다. | 인공지능 소프트웨어를 유지보수하는 데는 큰 비용이 든다. 데이터와 사용된 알고리즘 들 사이에는 다른 어떤 종류의 소프트웨어 프로젝트보다 더 널리 퍼져 있는 고유한 엉킴이 있다 - 머신러닝 파이프라인을 구현하기 시작하는 순간 파이프라인의 경직화가 시 작된다는 특징이 있다. 경직화를 막을 수는 없다. 최선의 방법은 사업 문제를 해결 하는 머신러닝 파이프라인 공법을 연구하는 것이다. 잘못된 머신러닝 파이프라인 이 경직화되면 놀랄 만큼 큰 비용이 들기도 한다. 더 상위 수준에서 생각해 볼 때 경직화는 기술적 이유와 조직적 이유 모두에서 발생한다. 기술적인 측면에서 볼 때 머신러닝 파이프라인이란 그 안에 여러 단계가 들어 있을 수 있 는 복잡한 소프트웨어이다. 이러한 각 단계별로 데이터 공학 분야의 전문 기술이나 빅데이 터 분야로부터 클라우드 컴퓨팅 분야에 이르는 기술이 필요할 수 있다. 조직 측면에서 볼 때, 머신러닝 파이프라인은 조직이 구축하는 대부분의 다른 소프트웨어 유물보다 더 많은 팀 간 동의가 필요하며 외부 공급업자와 새로운 계약도 해야 한다. - 일부 작업에서는 인공지능 알고리즘이 인간보다 나은 효과를 낼 수는 있지 만 이 글을 쓰는 시점에서 이러한 상황은 드물고, 종종 뉴스거리가 되는 정도이며, 게다가 성취되기까지 했다면, 그런 것들은 보통 세계 최고 수준의 인공지능 연구자 들로 구성된 팀이 산출해 낸 것이다. 인공지능 알고리즘의 결과가 사람이 달성할 수 있는 결과보다 더 나쁜 편이 훨씬 더 일반적이다 - 실용적인 사람들에게는 해법이 필요한데, 이 경우에는 여러분이 이미 문제에 익숙하다. 는 점을 인식하는 게 답이다. 이것은 내가 여러분에게 “그래서, 사는 동안 얼마까지 벌 수 있는가?”라고 묻는 일과 똑같은 문제다. 글쎄, 여러분이 적절한 사람들을 만날 수 있었다. 면 오늘날 구글보다 더 번영하는 회사를 설립했을 수도 있지만, 장래 일을 여러분은 결코 알 수 없다. 여러분은 그러한 질문에 답할 수 있게 하는 여러분의 인생에 대한 '소득 민감도’ 곡선을 모른다. 살면서 벌 수 있는 만큼 충분히 돈을 벌었는지를 여러분은 결코 알지 못한다. 여러분이 아는 것이라고는 여러분이 편안하게 살기에 충분한 돈을 벌었는지 여 부뿐이다. 인생과 마찬가지로, 어떤 한 가지 프로젝트에서 할 수 있는 질문은 “곡선의 최댓값은 얼마 인가?”가 아니다. 여러분은 사냥감이 풍부한 사냥터에 있으며 투자한 인공지능 프로젝트가 수익성이 있는지 확인하고 싶다는 점을 기억하자. 또한 투자 결정을 해야 하 는 시점에 이용할 수 있는 최상의 정보를 기반으로 결정해야 한다. 민감도 분석으로 최대값을 찾지 못했을지라도 여전히 수익성이 있는 파이프라인을 구축할 수 있다면 이를 사업적 성공이라고 한다. - 프로젝트 관리 방식은 빠르게 실패하는 쪽으로 기울어야 한다. 너무 일찍 포기하는 바람 에 잠재적인 해결책을 놓칠 수 있는 가능성을 받아들이는 대신에 종국에 가서 작동하지 않을 일에 오랫동안 갇혀 있는 상황을 피할 수 있다는 생각으로 균형 잡힌 생각을 유지 해야 한다. 문제가 있는 프로젝트에서 너무 오래 머무르면 결국 보여 줄 게 없는 상황이 되어 버리 기 때문에 주로 인공지능에 관한 주도권을 놓치게 된다 - 불행히도 조직은 종종 연구 프로젝트의 결과를 '예/ 아니요’, ‘작동 / 작동하지 않음'과 같은 이항 범주로 분류하는 습성을 보인다. 타임박스 접근 방식을 제대로 사용하려면 연 구상의 질문을 초기에 분석할 때 있을 법한 결과가 세 가지라는 점을 이해해야 한다. (1) 예 : 이 접근 방식을 더 추구해 볼 가치가 있다. 우리는 이 접근 방식에 많은 자원을 투입해야 한다. (2) 아니요 : 우리는 많은 노력을 기울여 이 접근 방식이 잘못되었다는 점을 확신할 수 있으며 이 접근 방식이 들어맞지 않을 것으로 예상한다. 여기에 자원을 더 이상 투입하지 말자. (3) 글쎄요 : 초기 조사에 착수한 후로 시간이 흘렀지만 이 접근 방식이 효과가 있는지를 알아내지 못했다. 하지만 우리가 더 열심히 노력했을 때도 효과가 없을지에 대해서는 충분히 조사하지 않았다. 나중에 자금과 시간이 더 주어지면 이 문제를 다시 검토해야 한다. - 결과를 예/ 아니요 / 글쎄요라는 3개 상태 논리 형식으로 보고하고 추적해 보 는 게 중요하다. 그 이유는 '아니요'로 답한 질문을 다시 개시하지 않은 채 시간이 흘러 '글쎄요’로 답했던 질문을 다시 개시할 수 있기 때문이다. 이런 식으로 제대로 구별할 수 있어야 '어려운 프로젝트를 조기에 기꺼이 포기’할 수 있고, 이게 유일한 방법이다. 나중에 더 많은 자원을 사용해 개선하고자 하는 성공적인 해법이 있는 경우에 일부 가능 성을 다시 살펴볼 가치가 있다고 결정할 수 있다. - 인공지능 기반 물리적 시스템은 간단한 환경 속에서 간단한 행위를 할 때 가 장 잘 작동한다. 시스템이 수행하는 모든 행위가 간단해서 시스템이 지루해하는 것처럼 보일 정도면 완벽하다. 여러분이 타고 있는 차가 창의적이기를 원하는가? 인공지능을 사용하는 물리적 시스템은 물리적 시스템이 우선이고 인공지능 시스템이 그 다음이다. 시스템은 사용 분야에 적합한 안전 지침과 신뢰 지침에 맞게 이러한 물리적 시 스템을 설계해야 한다. (예를 들어 자율 주행 차는 자동차 공학의 규칙과 규정에 맞춰져야 한다.) 안전 시스템 설계와 관련해 안전 공학이나 시스템 엔지니어링을 전공한 도메인 전문가는 예측 가능한 미래에 대해 최종 결정을 내린다. - 사물 인터넷 장치에서 데이터를 수집하려면 큰 비용이 소요되므로, 여러분 은 사물 인터넷 장치 설계 범위 내에서 인공지능에 필요한 데이터를 획득할 수 있 게 계획해야 한다. 기존 사물 인터넷 장치를 설치한 후에 나중에 가서 인공지능을 거기에 추가할 생각을 한다면, 곧 후회하게 될 것이다. 사물 인터넷이라는 분야에 인공지능을 적용할 때는, 물리적 장치는 현장에 배포된 후 변 경하기 어렵거나 변경이 불가능할 수 있는 반면에 시스템의 인공지능 부분은 훨씬 쉽게 개 선할 수 있는 소프트웨어로 구성된다는 점을 이해해야 한다. 이러한 불일치를 계산에 넣 어 두려면, 시스템을 설계하는 동안에 여러분은 인공지능 시스템의 첫 번째 버전이 수행할 작업을 고려해야 할 뿐만 아니라 향후 인공지능 시스템에서 이상적으로 개발하고 싶은 기 능까지도 고려해야 한다. 시스템용 최신형 인공지능에 필요할 것으로 예상되는 모든 하드웨어 센서를 처음부터 사물 인터넷 장치에 부착해 둔 다음에 해당 장치를 현장에 배포하 겠다는 식으로 생각하자. 이렇게 하면 고객은 자신이 이미 구매해 둔 장치에 필요한 추가 기능을 소프트웨어 업데이트만으로도 사용할 수 있을 것이다. “일단 하드웨어를 팔고 나중에 소프트웨어까지 팔아 돈을 번다”는 정책의 예는 스마트 폰의 소프트웨어를 지속적으로 개선해 나가는 제조업체에서 자동차 산업에 이르기까지 다 양하다. 일부 테슬라 모델에는 자율 주행에 필요할 것으로 예상되는 모든 하드웨어가 이 미 포함되어 있지만 자동 운전 기능 자체는 시간이 지남에 따라 계속 개선되고 있다. - 인공지능은 올바른 판단을 할 수 없으며 오늘날 사용되는 가장 일반적인 인 공지능 기반 방법들(예 : 딥러닝)로는 인과관계를 결정할 수 없다. 인공지능 기반 방법들은 올바른 지표가 있어야 추진할 수 있는 정량적 방법이다. 모든 인공지능 알고리즘은 지정된 지표를 최대화하는 이유는 모른 채 그러한 지표를 최대화하는 방 법만 안다. 인공지능이 해당 지표를 최대화해야 하는 맥락과 목적은 인간에게서 비롯되어야 한다. - 인공지능이 만드는 오류는 본질적으로 보험계리적이어서 인공지능은 “전체 모집단에 비추어 볼 때 내가 내린 이 결정이 합리적인가?” 라는 식으로 생각한다고 볼 수 있다. 반면에 인간은 특정한 경우들에서 각 사례에 맞춰 “이 결정이 합리적인가?”라는 식으 로 생각한다. 대부분의 사람은 이러한 구분을 이해하지 못하며 인공지능 시스템의 보 험계리적인 오류를 악의에 기인한 것이라고 생각할 수 있다.
- 기계는 20년 내에 인간이 할 수 있는 모든 일을 할 수 있게 될 것이다. (AI의 선구자 허버트 사이먼 Herbert Simon, 1965년) - 최소한 현재 구현되고 있는 기계들은 그들에게 프로그램된 일 이외에는 다른 일을 하지 않는다. 이런 식의 상황이 계속되는 한, 상상 속 악의를 걱정할 필요는 없다. 스티븐 핑커는 다음과 같이 말했다. (로봇이 초지능을 갖게 되면 인간을 노예로 삼을 것이란) 시나리오는 제트기가 독수리의 비행 능력을 능가했기 때문에 언젠가는 하늘에서 급강하해 가축을 덮칠 것이라는 생각과 비슷하다. 이런 오류는 지능을 동기와 혼동하고, 믿음을 욕구와, 추론을 목표와, 생각하는 것을 원하는 것과 혼동하는 데에서 비롯된다. 우리가 초인간 지능의 로봇을 발명한들 그들이 주인을 노예로 만들고 세계를 정복하고 싶어 할 이유가 있을까? 지능은 목표를 이루기 위해 새로운 수단을 효율적으로 사용하는 능력이다. 하지만 목표는 지능과 관련이 없다. 똑똑해지는 것과 뭔가를 원하는 것은 다르다. - 기계 번역 프로그램은 '바이텍스트'bitext, 즉 원본과 번역본으로 이루어진 두 쌍의 문서를 통해 학습하면서 작동한다. 불행히도 웹상의 글 중 상당 부분(어떤 경우에는 전체 웹 문서의 50퍼센트에 이르기도 한다)이 사실상 기계 번역 프로그램으로 만들어졌다. 결과적으로 구글번역이 번역에서 실수를 저지르면 그 실수가 웹상의 문서로 남게 되고, 그 문서가 다시 데이터가 되어 실수를 강화하는 것이다. - 이와 비슷하게 많은 시스템이 인간 크라우드 워커crowdworker(인터넷에서 제공되는 데이터 입력, 구글의 URL 순위 지정, 기록 복사, 사진 태그 달기 등 비정규적이고 한시적인 업무를 수행하는 사람 - 옮긴이)에게 의존해 이미 지에 이름을 붙이는데, 때로 이런 크라우드 워커들도 AI로 작동되는 로 봇을 이용해서 일을 처리한다. AI 연구 공동체는 특정 작업을 인간이 했는지, 로봇이 했는지를 구별하는 기법을 개발했지만 이 과정 자체가 AI연구자와 짓궂은 크라우드 워커들 간의 대결 구도가 되어 어느 쪽도 영구적인 우위를 유지하지 못하는 상황이 되어버렸다. 그 결과 인간이 만들었다고 하는 고품질 데이터 중 많은 부분이 사실 기계가 만들어낸 것으로 밝혀지고 있다. - 《대량살상 수학무기》의 저자 캐시 오닐이 강조했듯이 프로그램이 인종이나 민족을 기준으로 사용하지 않도록 만들어진다고 해도 지역, 소셜미디어 연결, 교육, 직업, 언어, 심지어는 즐겨 입는 옷에 이르기까지 대신 사용해서 동일한 결과를 가져오게 하는 온갖 종류의 '프록시proxy, 즉 연관 기능들이 있다. 더구나 프로그램이 내린 알고리즘에 따라 산 출된 결정은 객관성'이라는 가면을 쓰고 있어 관료들이나 기업의 중역 들에게 깊은 인상을 주고 일반 대중을 위협한다. 프로그램의 작업은 신 비에 쌓여 있다. 훈련 데이터는 기밀이고 프로그램은 독점적이며 의사결정 과정은 프로그램 디자이너조차 설명할 수 없는 블랙박스다. 따라서 개인은 알고리즘이 내린 결정이 부당하다고 느껴도 이의를 제기하기가 거의 불가능하다. - 몇 년 전 근로자의 퇴사율을 낮추고 싶었던 제록스는 직원들이 얼마 나 회사를 다닐지 예측하는 빅데이터 프로그램을 배치했다. 이 프로그 램은 통근 시간이 대단히 큰 변수라는 것을 발견했다. 출근 시간이 긴 직원들이 직장을 빨리 그만두는 것은 당연한 일이다. 하지만 제록스의 경영진은 회사가 부유한 지역에 위치해 있기 때문에 통근 거리가 먼 사람을 고용하지 않는 것은 사실상 저소득층 혹은 중산층에 대한 차별과 마찬가지라는 점을 깨달았다. 이 회사는 이 기준을 고려 대상에서 제외했다. 인간의 면밀한 감시가 없다면 이런 종류의 편견은 계속해서 튀어나올 것이 분명하다. 현재의 AI가 가진 여덟 번째 문제는 AI가 잘못된 목표를 가지기 쉽다. 는 점이다. 딥마인드의 연구원 빅토리아 크라코프나 Victoria Krakovna는 이 런 일이 일어난 수십 가지 사례를 수집했다. 축구를 하는 로봇은 가능 한 한 공을 많이 차야 한다고 프로그램되자 공을 양 발 사이에 두고 빠르게 진동하는 전략을 개발했다. 프로그래머가 생각지도 못한 부분이 었다. 특정한 물건을 쥐는 법을 배워야 했던 로봇은 쥐는 법을 보여주는 이미지로 훈련을 받은 뒤 카메라와 물체 사이에 손을 넣기만 하면 된다 고 판단했다. 로봇에게는 그 상태가 물체를 쥐는 모습과 똑같아 보였 기 때문이다. 야심이라고는 없는 한 AI는 테트리스 게임을 하라는 과제가 주어지자 지는 위험을 감수하기보다는 무한정 게임을 멈추어 두는 편이 낫다는 판단을 내렸다.
- 아이디어, 실체, 추상, 초월에 관해서라면 나는 그들의 머리에 그런 개념을 도무지 집어넣을 수가 없었다. (조너선 스위프트 Jonathan Swift, 《걸리버 여행기》 중에서) - 소립자들이 단순하고 보편적인 법칙을 따르리라고 기대하는 것과 인간이 같은 것을 따르리라고 기대하는 것은 전혀 다른 문제다. (자비네 호젠펠더sabine Hossenfelder, 수학의 함정 중에서) - 딥러닝은 어떤 원리로 작동하는 것일까? 딥러닝은 두 가지 근 본적인 아이디어를 기반으로 한다. 첫 번째 핵심 아이디어인 '계층적 패턴 인식'hierarchical pattern recognition은 1950년대에 이루어진 일련의 뇌 연구 실험에서 비롯됐다. 신경생 리학자 데이비드 허블David Hubel과 토르스텐 비셀rorsten Wiesel은 이 실험 으로 1981년 노벨 생리의학상을 수상했다. 허블과 비셀은 시각 시스템 에 존재하는 여러 뉴런들이 시각적 자극에 뚜렷이 다른 방식으로 반응 한다는 점을 발견했다. 어떤 뉴런은 특정한 방향의 선과 같은 단순한 자 극에 대단히 활발하게 반응하는 반면, 어떤 뉴런은 보다 복잡한 자극에 격렬한 반응을 보였다. 그들이 제안한 이론은 복잡한 자극이 선에서 문자, 단어로 추상성이 증가하는 계층 구조를 통해 인식될지 모른다는 것이었다. - 1980년대에 AI 역사에서 획기적이라고 할 만한 사건이 벌어졌다. 일본의 신경망 분야 선구자인 후쿠시마 구니히코福島邦彦가 허블과 비셀의 이론을 계산학적으로 구현한 신인식기 Neocognitron를 만들어 컴퓨터 시각의 일부 측면에서도 이 이론이 유효하다는 점을 보여준 것이다(이후 제프 호킨스 Jeff Hawkins와 레이 커즈와일의 책들도 같은 아이디어를 옹호했다. 신인식기는 (직사각형처럼 보이는) 일련의 층으로 이루어져 있었다. 다 음 페이지에 나오는 그림 왼쪽 첫 번째에 있는 것이 자극이 표시되는 입력층으로, 그 본질은 디지털 이미지의 픽셀들이다. 이후 오른쪽으로 이어지는 층들은 이미지를 분석하면서 명암이나 모서리 등의 차이를 찾으며, 끝에는 입력된 정보가 속하는 범주를 찾는 출력층이 있다. 층들 사 이의 연결을 통해 모든 관련 처리 과정이 일어난다. 이 모든 아이디어, 즉 서로 연결된 입력층, 출력층, 내부층이 현재 딥러닝의 중추다. 이런 시스템을 '신경망'이라고 부른다. 각 층이 뉴런에 비견될 수 있는(인간에 비하면 대단히 단순화됐지만) 노드node라는 요소들로 이루어져 있 기 때문이다. 이들 노드 사이에는 연결 가중치connection weight 혹은 가중치weight라고 불리는 연결부가 있다. 노드 A에서 노드 B 사이의 가중치 가 클수록 A가 B에 미치는 영향은 커진다. 네트워크가 하는 일은 이런 가중치의 함수다. 딥러닝의 두 번째 핵심 아이디어는 바로 학습tearning이다. 예를 들어 입력의 특정한 배열이 특정한 출력에 가하는 가중치를 강화하면 네트워 크가 특정한 입력과 그에 상응하는 출력의 연관성을 학습하도록 훈련’시킬 수 있다. - 딥러닝 시스템은 전반적으로 내용을 이해하는 것이 아니라 그저 '연관성'에 의존하기 때문에 질문이 끝나기도 전에 임의적인 추측으로 버저를 누른다. 예를 들어 당신이 “얼마나 많은?”이라고 질문하면 “2”라는 답을 얻고 “어떤 스포츠?”라고 물으면 "테니스" 라는 답을 얻게 된다. 이런 시스템들을 몇 분만 다루어 보면 진짜 지성이 아닌 정교한 속임수로 상호작용이 이루어지고 있다는 느낌을 받을 것이다. 기계 번역에서는 같은 문제가 좀 더 기괴한 버전으로 나타난다. 구글번역에 dog dog dog dog dog dog dog dog dog dog dog dog dog dog dog dog dog dog'를 입력하고 나이지리아 요루바어(와 다른 몇 가지 언어)에서 영어로 번역을 요청하면 이런 번역 결과가 나온다. 지구 종말을 알리는 시계는 12시 3분 전을 가리키고 있다. 우리는 세상에서 극적인 발전과 개성을 경험하고 있다. 이는 우리가 점점 종말의 시간과 예수의 재림에 가까워지고 있다는 것을 시사한다. - 이러한 결과에서 보듯이 딥러닝은 그리 심층적이지가 않다. 딥러닝이라는 용어에서 '딥deep(심층)이라는 단어는 신경망에 있는 층의 숫자를 의미할 뿐임을 알아야 한다. 그 맥락에서의 답은 그 시스템이 입력된 데이터에 대해 개념적으로 특별히 의미 있는 어떤 '지식'을 배웠다는 뜻이 아니다. - 본트리올대학교의 조슈아 벤지오 교수는 최근 “심층 신경망은 높은 수준의 추상적인 개념이 아니라 데이터 세트 내의 표면 통계적 규칙성 Surface statistical regularities 을 학습하는 경향이 있다.”고 인정했다. 마간가 지로 2018년 말의 인터뷰에서 제프리 힌턴과 딥마인드 개발자인 데미 스 허사비스Demis Hassabis 도 범용 인공지능은 현실과 거리가 멀다고 이 야기했다. 이는 일종의 '롱테일' 문제로 귀결된다. 데이터 수집만을 놓고 봤을 때 배우기 쉬운 흔한 예들도 있지만 배우기가 아주 어려운 희귀한 항목 (롱테일)들도 대단히 많은 것이다. 딥러닝이 한 무리의 아이들이 프리스비를 가지고 논다고 말하게 만드는 일은 쉽다. 그런 라벨이 붙은 사례가 매우 많기 때문이다. 하지만 다음 페이지의 그림 13처럼 평범함에서 벗어난 것들에 대해서 이야기하게 만들기는 훨씬 더 어렵다. - 그렇다고 딥러닝 시스템이 지능적인 일들을 아예 할 수 없다는 말은아니다. 우리는 딥러닝 자체에 완전한 지성이라면 갖춰야 할 유연성'과 '적응성이 부족하다는 말을 하고 있는 것이다. 우주선 설계의 에이킨 법칙Akin's Laws of Spacecraft Design에서 31번째 법칙은 불후의 명언으로 부족함이 없다. “높은 나무에 성공적으로 올랐다고 해서 달에 이를 수 있는 것은 아니다.” - 인지과학자인 더글러스 호프스태터Douglas Hofstadter는 《디 애틀랜틱》에 실린 훌륭한 기사를 통해 구글 번역의 한계를 설명했다. 우리 인간은 부부, 집, 개인 소지품, 긍지, 경쟁, 질투, 사생활을 비롯해 결혼한 부부가 그녀의 것', 그의 것'이라고 수놓인 수건을 갖 고 있는 것과 같은 기이한 일에 이르기까지 다양한 무형적인 것들에 대한 지식을 갖고 있다. 구글 번역은 그런 상황에 익숙하지 않다. 오로지 글자로 이루어진 단어들의 문자열에만 친숙하다. 구글 번역은 조각 글을 초고속으로 처리하는 데 능수능란할 뿐 생각하거나, 상상하거나, 기억하거나, 이해하는 일은 전혀 못 한다. 심지어 단어들이 대상을 상징한다는 것조차 알지 못한다. - 대개의 경우 기계 번역 프로그램은 전체 단락의 의미는 이해하지 못한 채 한 번에 하나의 문장씩을 바꾸어 나가면서 유용한 것을 만들어낸다. 그러나 인간인 당신이 어떤 이야기나 에세이를 읽을 때는 이와 완전히 다른 일을 한다. 당신의 목표는 '통계적으로 그럴듯한 쌍의 조합을 만들어내는 것이 아니라 '작가가 당신과 공유하려는 세상을 재구성하는 것이다. - 어떤 글을 읽을 때 당신이 하는 일은 인지심리학에서 사용하는 표현을 빌리자면 그 글이 전하는 말의 의미에 대한 인지 모델cognitive model을 구축하는 것이다. 이 일은 대니얼 카너먼 Daniel Kahneman과 작고한 앤 트라이즈먼 Anne Treisman이 목적 파일object file이라고 불렀던 것(개별 객체 와 그 특징의 기록)을 편집하는 일만큼 간단할 수도 있고 복잡한 시나리 오를 완벽하게 이해하는 일만큼 복잡할 수도 있다. - ANI의 전형인 구글 번역에는 인지 모델을 구축하고 이용하는 과정 자체가 없다. 구글 번역은 추론을 하거나 추적할 필요가 전혀 없다. 꽤 나 잘하는 일이 있기는 하지만 구글 번역이 다루는 것은 진짜 독해가 의 미하는 바의 아주 작은 일부일 뿐이다. 구글 번역은 이야기의 인지 모델 을 구축하지 않는다. 할 수가 없기 때문이다. 딥러닝 시스템에게는 “톰 슨 씨가 지갑이 있는지 더듬어 보고 지갑이 있을 거라고 생각한 곳이 불 룩했다면 어떤 일이 생겼을까?”라는 질문을 할 수가 없다. 그것은 패러 다임의 일부가 아니기 때문이다. 통계는 실제적 이해의 대체물이 아니다. 문제의 핵심은 단지 여기저 기에서 무작위적으로 오류가 나타난다는 점이 아니다. 번역에 요구되 는 유형의 통계적 분석, 그리고 시스템이 읽은 것을 실제로 이해하기 위해 필요한 인지 모델의 구축 사이에 근본적인 부조화가 존재한다는 점이다. - 자연어 이해 분야는 지금껏 두 마리 토끼를 잡으려다 한 마리도 잡지 못한 셈이다. 한 마리 토끼인 딥러닝은 학습에는 뛰어나지만 합성성과 인지 모델 구축에서는 형편없고, 다른 한 마리 토끼인 클래식 AI는 합성 성과 인지 모델 구축을 통합하지만 학습에서는 좋게 말해도 그저 그런 정도다. 그리고 이 둘 모두가 우리가 이 장 내내 강조해온 중요한 부분, 즉 상식을 놓치고 있다. 세상이 어떻게 돌아가는지에 대해서, 사람과 장소와 대상에 대해서, 그들이 상호작용을 하는 방식에 대해서 많은 것을 알지 못하는 한, 복잡 한 글에 대한 믿을 만한 인지 모델을 구축할 수 없다. 상식이 없으면 아 무리 많은 글을 읽어도 이해할 수가 없다. 컴퓨터가 글을 읽지 못하는 진짜 이유는 그 시스템들에게는 세상이 어떻게 돌아가는지에 대한 기본적인 이해조차 없기 때문이다. 불행히도 상식을 쌓는 것은 생각보다 훨씬 더 어려운 일이다. 앞으로 보게 되겠지만 기계가 상식을 쌓아야 하는 필요성은 대개 보편적이고 전반적인 이유에서 비롯된다. 그리고 그 필요성은 언어 영역에 있어서 도 긴급한 문제지만 로봇공학 영역에 있어서는 더욱 시급하고 중요한 문제로 작용한다. - 지능을 가진 존재(로봇, 인간, 동물)로서 룸바보다 수준이 높기를 바란다면 몇 가지 갖추어야 할 것이 있다. 우선 지능이 있는 모든 존재는 다 섯 가지 기본적인 일을 계산할 수 있어야 한다. 자신이 어디에 있는지, 주변 세상에서 어떤 일이 일어나는지, 당장 무슨 일을 해야 하는지, 계 획을 어떻게 실행해야 하는지, 주어진 목표를 달성하기 위해서는 장기 적으로 어떤 일을 해야 할지 계산해야 하는 것이다. 단일한 과제에 집중하는 수준이 낮은 로봇은 이런 계산을 할 줄 모른다. 룸바의 초기 모델은 자신이 어디에 있는지 전혀 몰랐고, 자신이 돌아다니는 영역의 지도를 추적하지 못했고, 계획을 세우지 못했다. 이 첫 모델은 자신이 움직이고 있는지, 최근에 어디에 부딪쳤는지 이상은 거의 알지 못했다(최근의 룸바 모델들은 지도를 만들어 보다 효율적으로 움직이 고 무작위적인 탐색 과정에서 오염 부분을 놓치지 않으려 한다). 그다음으로 무슨 일을 해야 할 것인가의 문제는 제기된 적이 없다. 룸바의 유일한 목표는 청소다. 하지만 룸바의 이런 명쾌한 단순성에는 한계가 있다. 더 다양한 기능을 수행해야 하는 가정용 로봇이라면 일상생활에서 대단히 많은 선택과 마주하게 되며 따라서 의사결정이 좀 더 복잡해진다. 세상에 대한 훨씬 더 정교한 이해에 의존해 의사결정을 내려야 하는 것이다. 목표와 계획 은 언제든 변할 수 있다. 주인이 식기세척기에서 그릇을 꺼내라고 지시 했더라도 좋은 가정용 로봇이라면 무조건 그 일만 해서는 안 된다. 상황이 변하면 거기에 적응해야 한다. 유리 접시가 식기세척기 옆 바닥에 떨어져 있다면 로봇은 식기세척기 로 가는 또 다른 길을 찾거나(단기 계획의 변화) 기왕이면 우선 깨진 접시를 치우고 그러는 동안 그릇 꺼내는 일은 보류해야 한다고 인식해야 한다. 가스레인지 위의 음식에 불이 붙었다면 로봇은 불을 끌 때까지 식기 세척기에서 그릇 꺼내는 일을 미뤄야만 한다. 하지만 우리의 불쌍한 로 봇청소기 룸바는 5급 허리케인이 들이닥친 와중에도 청소를 계속할 것이다. 우리는 로지에게 그보다 더 나은 것을 기대한다. - 어떤 마법이 있기에 우리 인간은 지능을 갖게 되는 것일까? 이 경우에는 '비법이 없다는 것이 비법이다. 지능의 힘은 어떤 단일하고 완벽한 원리가 아닌 우리의 방대한 다양성에서 비롯된다. (마빈 민스키, 《마음의 사회》 중에서) - 신경과학 연구가 우리에게 가르쳐준 것이 있다. 두뇌는 엄청나게 복잡하다는 점이다. 지구상에서 가장 복잡한 시스템으로 묘사될 정도다. 평범한 인간의 두뇌에는 대략 860억 개의 뉴런이 있다. 뉴런의 유형은 수천까지는 아니더라도 수백 개를 가뿐히 넘어선다. 시냅스는 수조 개 이며 각 개별 시냅스 내에는 수백 가지 다른 단백질이 있다. 4 모든 차원마다 그 복잡성이 엄청나다. 뚜렷하게 식별할 수 있는 150개 이상의 두뇌 영역이 있고 그들 사이에는 방대하고 복잡한 연결망이 있다. 선 구적인 신경과학자 산티아고 라몬 이 카할은 1906년 노벨상 수상 연설에서 이렇게 표현했다. “불행히도 자연은 편의성과 통합성에 대한 우리의 지적 욕구에 대해서 알지 못하며 매우 자주 복잡성과 다양성 안에서 즐거움을 느끼는 것 같습니다. 정말로 지능적이고 유연한 시스템이라면 두뇌처럼 복잡성으로 가득 할 가능성이 높다. 그래서 지능을 단일한 원리, 혹은 단일한 마스터 알고리즘으로 수렴시키려는 이론은 헛다리를 짚기 마련이다. - 사람이 두뇌의 10퍼센트만을 사용한다는 이야기는 사실이 아니다. 하지만 두뇌 활동이 대사적으로 소위 '가성비가 떨어지 기에 우리가 한 번에 두뇌 전체를 사용하는 경우가 거의 없다는 것만은 사실이다. 우리가 하는 모든 일에는 두뇌 자원의 다른 하위 집합이 필요하며, 따라서 주어진 순간에 두뇌의 일부 영역은 활성화되는 반면 일부 영역은 빈둥거리고 있을 것이다. 후두 피질은 시각에 대해 활성화되는 경향이 있으며 소뇌는 신체 움직임에 활성화되는 식이다. 두뇌는 대단 히 구조화된 장치이며 정신적 역량의 대부분은 적절한 때에 적절한 신 경 도구들을 사용하는 데에서 나온다. 우리는 진정한 인공지능이라면 고도로 구조화되어 있을 것이라고 예상한다. 그들이 가진 힘의 대부분은 주어진 인지 과제에 대해서 그 구조를 적절한 시기에 적절한 방식으로 활용하는 능력에서 나올 것이다. - 아이러니하게도 이는 현재의 추세와는 정반대다. 현재 머신러닝은 가능한 한 작은 내부 구조를 가진 단일한 동질의 기제를 사용하는 종단종모델에 치우쳐 있다. 그 예가 엔비디아 Nvidia의 2016년 운전 모델이다. 이 모델은 인식, 예측, 의사결정과 같은 전형적인 모듈 구분을 저버리고, 인풋(픽셀)과 아웃풋 한 세트(조종과 가속에 대한 지시) 사이의 더욱 직접적인 연관관계를 학습하기 위해 상대적으로 획일적인 단일 신경망을 사용했다. 이런 종류의 일에 열광하는 사람들은 여러 모듈(인식, 예측 등)을 별개로 훈련시키는 대신 전체 시스템을 공동으로 훈련시키는 장점을 강조한다. 그런 시스템들은 개념적으로는 어느 정도 단순하다. 인식, 예측, 그리 고 그 나머지에 대해 별개의 알고리즘을 고안할 필요가 없다. 더구나 언뜻 보기에는 효과가 좋다. 인상적인 동영상들이 이를 증명하는 것처럼 보인다. 하나의 큰 네트워크와 적절한 훈련 세트를 두는 것이 훨씬 편한 데 왜 귀찮게 인식과 의사결정과 예측을 별개의 모듈로 취급하는 하이브리드 시스템을 사용해야 하는가? 문제는 그런 시스템에는 유연성이 거의 없다는 점이다. 엔비디아의 시스템은 인간 운전자의 개입을 크게 요구하지 않고 잘 작동한다. 몇 시 간 동안은 말이다. 그러나 수천 시간을 기준으로 볼 때는 잘 작동한다고 볼 수 없다. 조금 더 모듈식에 가까운 웨이모 시스템은 A지점에서 B지점까지의 운행에 효과적이고 차선 변경과 같은 일을 잘 처리하는 반면, 엔비디아 시스템이 할 수 있는 일은 차선을 그대로 유지하는 것뿐이다. 차선 지키기도 물론 중요한 일이지만 그것은 운전과 관련된 일의 아주 작은 부분에 불과하다. 복잡한 문제를 풀 때 다른 대안이 없는 경우라면 최고의 AI 연구자들은 종종 하이브리드 시스템을 사용한다. 우리는 이런 사례가 더 많아질 것으로 예상한다. 딥마인드는 픽셀과 게임 점수부터 조이스틱 움직임에 이르기까지 종단종 시스템 훈련을 통해 하이브리드 시스템 없이도 아타리 게임의 문제를 (어느 정도) 해결할 수 있었다. 하지만 바둑에는 이와 유사한 접근법이 먹히지 않았다. 바둑은 여러 면에서 1970년대부터 1980년대까지의 저해상도 아타리 게임들보다 훨씬 더 복잡했기 때문이다. 예를 들어 바둑에서는 게임에서 가능한 위치가 너무나 많고 하나의 수가 훨씬 더 복잡한 결과를 낸다. 순수 종단종 시스템이여 이제 안녕! 반갑다 하이브리드. 바둑에서 승리하기 위해서는 두 가지 다른 접근법을 종합해야 했다. 딥러닝과 몬테카를로 트리 탐색Monte Carlo Tree Search 이라고 알려진 기법으로, 게임이 펼쳐질 수 있는 방식으로 가지가 뻗어 나간 나무 사이에서 가능성을 샘플링하는 것이다. 몬테카를로 트리 탐색 자체도 두 가지 다른 아이디어가 합성된 것이다. 두 아이디어, 즉 게임 트리 탐색과 몬테카를로 탐색 모두 그 유래는 1950년대로 거슬러간다. 게임 트리 탐색은 선수의 가능한 움직임을 내다보는 교과서적인 AI 기법이며, 몬테카를로 탐색은 다수의 임의적 시뮬레이션을 진행하고 그 결과로 통계를 내는 일반적인 방법이다. 딥러닝이는 몬테카를로 트리 탐색이든 어떤 시스템도 그 자체만으로는 세계 챔피언을 배출할 수 없다. 여기에서의 교훈은 딱 하나다. AI가 인간의 정신과 마찬가지로 구조화되어야 한다는 점이다. 즉 문제의 서로 다른 측면에 서로 다른 종류의 도구로 대응하는 방식으로 작동해야 한다 - 데미스 허사비스가 최근 말했듯이 “진정한 지능은 딥러닝이 뛰어난역량을 보였던 분야인 개념적 분류를 훨씬 넘어서는 것이기 때문에 그것을 1980년대에 클래식 AI가 다루려고 노력했던 많은 것들, 즉 더 높은 수준의 사고와 상징적 추론에 다시 연결시켜야만 한다.” 광범위한 지능, 궁극의 범용지능에 이르기 위해서는 오래된 도구와 새로운 도구들을 비롯해 많은 다양한 도구들을 우리가 아직 발견하지 못한 방식으로 통합해야 할 것이다. - 형식 논리 시스템의 목표는 모든 것을 정확하게 만드는 것이지만 현실 세계에서는 우리가 대처해야 하는 많은 것들이 모호하다는 데 더 큰 문제가 있다. 1939년 소련의 핀란드 침공이 제2차 세계대전 발발에 영향을 끼쳤는지 판단하는 것은 논리적 표기의 면에서도 분류법에서만큼이나 어려운 문제다. 더 넓게 보면 우리가 이야기해온 형식 논리가 잘하는 일은 딱 하나다. 우리가 확신하는 지식에 유효한 규칙을 적용해서 마찬가지로 확실한 새로운 지식을 연역할 수 있게 해준다. 우리가 아이다가 아이폰을 소유하고 있다는 점을 완벽하게 확신하고, 애플이 모든 아이폰을 만든다는 점을 확신한다면, 다음으로 우리는 아이다가 애플이 만든 것을 갖고 있다고 확신할 수 있다. 하지만 도대체 '완벽한 확신이란 무엇인가? 버트런드 러셀이 말했듯이 “인간의 모든 지식은 불확실하고, 부정확하고, 불완전하다. 그런데도 인간은 용케 살아가지 않는가? 기계가 이 같은 일을 하게 되면, 즉 인간과 같은 유동성을 가지고 불확실하고, 부정확하고, 불완전한 지식을 표상하고 추론할 수 있게 되면 유연하면서도 강력한 범용지능의 시대가 다가올 것이다. - 역사적으로 AI는 수동 코딩과 머신러닝이라는 양극단 사이를 오갔다. 칼의 작동 방법에서 유추해 잔디 깎기 작동법을 학습하는 일은 라벨이 붙은 많은 사진을 집어넣어 개의 종을 분류하는 시스템을 개선하는 일과는 전혀 다르다. 지나치게 많은 연구가 전자를 배제하고 후자에만 몰두했다. 칼 그림에 라벨을 다는 것은 픽셀의 공통 패턴에 대한 학습의 문제일 뿐이다. 칼이 무슨 일을 하는지' 이해하기 위해서는 형태와 기능, 그들이 어떤 연관을 갖는지에 대한 훨씬 더 심층적인 지식이 필요하다. 칼의 용도와 위험성을 이해하는 것은 많은 사진을 축적하는 것이 아 닌 인과관계의 이해(그리고 학습)에 대한 문제다. 결혼식을 계획하는 디지털 비서라면 결혼식에는 전형적으로 칼과 케이크가 필요하다는 것만 알아서는 안 된다. 이 디지털 비서는 그 칼이 케이크를 자르기 위해서 거기에 있다는 이유를 알아야만 한다. 케이크가 결혼식용 특별 밀크셰 이크로 대체되면 이전 데이터에서 칼과 결혼식의 상관관계가 아무리 높다 해도 칼은 필요하지 않다. 신뢰할 수 있는 디지털 비서는 칼은 집에두고 빨대를 잔뜩 가져가야 한다는 것을 인식할 만큼 밀크셰이크에 대해 충분히 이해하고 있어야 한다. 거기에 이르기 위해서는 학습을 완전히 새로운 수준으로 끌어올려야 한다. - 결국 인간 정신의 연구에서 얻은 교훈은 모든 일에 타협이 필요하다는 것이다. 우리에게 필요한 것은 0에서부터 모든 것을 학습해야 하는 백지 상태의 시스템도, 생각할 수 있는 모든 우발적 상황을 미리 완전히 시뮬레이션한 시스템도 아니다. 그보다는 개념적이고 인과적 수준에서 새로운 것을 학습할 수 있게 해주는 강력한 본유의 토대를 갖춘 주의 깊 게 구조화된 하이브리드 모델이다. 즉, 단순히 분리된 사실들만이 아니라 이론을 학습할 수 있는 시스템을 추구해야 하는 것이다. - 상식, 궁극적으로는 '범용지능에 이르는 우리의 레시피는 이렇게 요약할 수 있다. 첫 번째 단계에서는 인간 지식 그러니까 시간, 공간, 인과 성, 물리적 사물과 그들의 상호작용에 대한 기본적 지식, 인간과 그들의 상호작용에 대한 기본적 지식의 핵심 체계를 나타낼 수 있는 시스템을 개발한다. 둘째, 추상성, 구상성, 개별 추적에 대한 중심 원리를 항상 염 두에 두면서 이런 것들을 온갖 종류의 지식으로 자유롭게 확장될 수 있 는 아키텍처에 집어넣는다. 셋째, 복잡하고 불확실하고 불완전한 지식 을 다룰 수 있고 하향식, 상향식으로 모두 자유롭게 작동할 수 있는 강 력한 추론 기법을 개발한다. 그리고 이들을 인식, 조종, 언어와 연결한다. 이들을 이용해서 세상에 대한 강화된 인지 모델을 구축한다. 그 후 마지막 단계에 이르러 인간에게 영감을 받는 종류의 학습 시스템을 만드는 것이다. 이 시스템은 AI가 가지고 있는 모든 지식과 인지역량을 이용하고, 학습한 지식을 이전 지식에 통합하고, 아이들처럼 모든 가능한 정보로부터 탐욕스럽게 학습하고, 세상과 상호작용하고, 사람과 상호작용하고, 책을 읽고, 비디오를 보고, 가르침을 받는다. 이 모든 것이 합쳐지면 거기에서 딥 언더스탠딩을 얻을 수 있다. 분명 무리한 요구다. 하지만 반드시 해야 할 일이다. - 신들은 언제나 그들을 만든 사람들과 똑같이 행동한다. (조라 닐 허스턴zora Neale Hurston, 《내 말에게 말하라》Tell My Horse 중에서) - 제2차 세계대전 중에 실존주의 철학가 장 폴 사르트르의 수업을 듣던 한 학생은 인생의 두 갈래 길에서 갈피를 잡지 못하고 있었다. 이 학생은 프랑스군에 입대해서 참전해야 한다고 생각했지만 어머니가 감정적 으로 그에게 대단히 의지하고 있었다(그의 아버지는 어머니를 버렸고 형은 사망한 상황이었다). 사르트르는 그 학생에게 이렇게 말했다. “어떤 보편적 윤리 규범도 네가 무엇을 해야만 할지 정해주지 않는다. 먼 미래 의 언젠가는 그런 것들을 걱정하는 기계를 만들 수 있을 것이다. 하지만 그보다 긴급한 문제들이 있다. - 지금 우리는 일종의 공백기에 있다. 네트워크화됐고 자율성을 가졌으나 힘의 결과에 대해서 추론할 진정한 지능은 거의 없는 좁은 지능의 상 태에 있는 것이다. 머지않아 AI는 더욱 정교해질 것이다. 자기 행동의 결과에 대해 추론할 수 있게 될 날은 빨리 올수록 좋다. 이 모든 것이 이 책의 큰 주제와 매우 직접적으로 연관된다. 우리는 지금의 AI연구가 대체로 잘못된 길을 가고 있다고 주장해왔다. 기존 연구와 노력의 대부분은 한정된 과제를 수행하고 우리가 딥 언더스탠딩이 라고 부르는 것이 아닌 빅데이터에 주로 의존하는, 비교적 지적이지 않 은 기계를 만드는 데 집중되고 있다. 우리는 그것이 큰 실수라고 생각한다. 그 방향이 일종의 '사춘기 AI로 이어질 가능성 크기 때문이다. 자신 의 장점이 무엇인지 모르고 자기 행동의 결과를 심사숙고할 수단을 갖 지 못한 기계로 말이다. 단기적인 해법은 우리가 만드는 AI에게 입마개를 씌우는 것이다. 심각한 결과가 따르는 일은 할 수 없게 하고 발견되는 개별적 오류를 수정하는 것이다. 하지만 지금까지 살펴보았듯이 이것은 장기적으로 실행할 수는 없는 방법이며 단기적으로도 포괄적인 해법이 아닌 반창고를 붙이는 수준일 뿐이다. 이런 난장판을 벗어나는 유일한 방법은 상식, 인지 모델, 강력한 추론도구들을 갖춘 기계를 만드는 일을 하루빨리 시작하는 것이다. 이 모든 것을 합치면 딥 언더스탠딩에 이를 수 있다. 딥 언더스탠딩은 자신의 행 동 결과를 예측하고 평가할 수 있는 기계를 만드는 전제 조건이다. 이 프로젝트는 이 분야가 통계나 빅데이터에 대한 심각한, 그러나 피상적 인 의존으로부터 탈피해야만 비로소 시작될 수 있다. 위험한 AI에 대한 치료제는 더 나은 AI이며 더 나은 AI로 가는 가장 올바른 길은 세상을 진정으로 이해하는 AI를 통해서만 가능하다.
- 머신러닝이 모든 문제의 해결책은 아니다. 먼저 꼭 짚어야 할 점은 산업 현장에서 겪는 모든 엔지니어링 관련 문제를 해결하기 위한 가장 적합한 방법이 머신러닝이 아닐 수 있다는 사실이다. 머신러닝은 특정 문제를 해결하기 위한 수단일 뿐이며, 머신러닝이 목적이 되어 끼워 맞추는 식으로 활용할 경우 오히려 안 좋은 결과를 초래할 수 있다. 만약 휴리스틱heuristic (간단한 규칙)을 써서 높은 성능으로 문제 를 해결할 수 있다면, 머신러닝을 쓰기 위해 들여야 하는 자 원을 아낄 수 있다. 가령 뉴스 관련 미디어 회사에서 스포츠 팀별 하이라이트 유튜브 영상을 분류하고 싶다고 하자. 스포츠 팀은 팀별로 특정한 이름이 있고, NBA와 같은 스포츠 리그는 팀이 30개밖에 안 된다. 따라서 각 팀 이름을 놓고 NBA 공식 플레이리스트의 영상 제목에서 간단한 고유명사 매칭 및 필터링을 거치면 꽤 높은 확률로 빠르게 팀별 게임 영상을 분류할 수 있을 것이다. 하지만 휴리스틱은 복잡해지거나 새로 유입된 데이터에 따라 규칙을 추가하거나 기존 규칙을 업데이트하기 어렵다. 는 문제가 있다. 가령 소셜미디어 회사에서 악성 댓글을 감지 하는 모델을 만들고 싶다고 하자. 특정 비속어 단어 키워드를 매칭하는 규칙을 쓴다면, 새로운 비속어가 등장할 때마다 단 어를 추가해야 하기 때문에 이를 유지하는 비용이 엄청나다. 이 경우에는 머신러닝이 비용을 줄이는 효과적인 방법일 수 있다. 딥러닝 모델에 문장 전체를 하나의 입력값으로 넣고, 출력값으로 그 문장의 혐오 종류와 수위 등을 분류하도록 학습시킬 수 있기 때문이다. 그럼 특정 키워드뿐만 아니라 악성 댓글의 문맥 패턴까지 학습하여 새로운 비속어가 등장하더라도 문맥이 혐오적이라면 이를 올바르게 감지하는 모델을 만들 수 있을 것이다. - 첫 모델을 빨리 출시하라 평가 지표를 골랐다면 첫 모델을 빨리 개발하여 테스트 환경에 배포해보는 것이 좋다. 머신러닝 모델은 가장 간단한 기준 모델baseline model’부터 시작해서 계속 개선해나가는 것이 중요하기 때문이다. 처음부터 성능이 뛰어난 모델을 디자인 하고 학습시키려 한다면 너무 많은 시간을 허비할 수 있으며, 전체적인 파이프라인도 소홀하게 구축될 수 있다. 사실 머신 러닝 프로젝트에서는 모델링도 중요하지만, 어떻게 학습된 모델을 테스트하고 배포하는지, 배포한 모델을 어떻게 모니 터링하는지, 추론에 오류가 있다면 어떻게 피드백을 받아 재학습시키는지 등도 그만큼 중요하다. 그래서 가장 간단한 모델, 심지어 규칙성 휴리스틱 모델을 먼저 만들어 서비스해보면 전체적인 그림을 그릴 수 있고, 어느 부분이 부족한지 정확히 알 수 있다. 그렇다면 학습된 모델을 어떻게 서비스화할 수 있을까? 여기에는 크게 세 가지 방법이 있다. 첫째는 REST API' 라는 형태다. 클라이언트(유저)가 서버(모델)에 웹상으로 입력값을 보내 요청하면 서버에서 출력값을 다시 클라이언트에 전달하는 방식이다. 둘째는 오프라인에서 모델을 활용하는 방식이 다. 예를 들어 검색엔진에서 음란물 사이트를 감지하는 모델 을 학습했다고 하자. 이미 데이터베이스에 사이트에 관한 방대한 정보가 쌓여 있기 때문에, 오프라인 상태에서 이 모델에 데이터베이스에 있는 웹페이지 데이터를 입력해 추론한 결과 값을 도출해낼 수 있다. 셋째는 유저의 휴대 기기(핸드폰, 태블 릿 PC 등)에 모델을 배포해 기기에서 직접 모델을 돌리는 방 법이다. 이는 여러 최신 카메라 애플리케이션이 장면 인식, 얼굴 인식, 비디오 화질 개선 등을 위해 사용하는 방법 중 하 나다. 이미지 및 비디오를 서버로 보내 처리하여 다시 모바일 기기로 받아내는 시간이 너무 오래 걸리기 때문에 모바일 기기에서 직접 모델을 돌리는 경우 레이턴시를 효과적으로 줄일 수 있다. - 이렇듯 게임 속 플레이어의 행태는 인간의 심리나 사회 메커니즘을 이해하는 데 좋은 단서가 될 수 있다. 효과적인 조직 관리에 대한 힌트를 게임 세계에서 잘나가는 길드의 특 징을 분석함으로써 찾을 수 있지 않을까? 현실 세계에서 최 저 임금을 높이거나 기초 소득을 제공했을 때 경제에 미치는 영향을 추정하기 위해 게임 세계에서 재화 획득량을 높였을 때 게임 경제가 어떻게 바뀌는지 분석하는 건 어떨까? 또는 게임 속에서 사람들이 아이템을 서로 거래할 때 어떻게 가격 이 수렴하는지 분석하면 현실 세계에서 시장 가격이 형성되 는 원리를 이해하는 데 도움이 될지도 모른다. 물론 게임은 현실과 다르다. 대신 현실에서는 확보하기 불 가능한 수준의 세밀한 데이터를 분석할 수 있다. 사실 게임과 현실의 차이가 더 클지 아니면 현실 세계에서 관측할 수 있는 정보의 한계가 더 클지는 아무도 모른다. 다만 여기서 중요한 것은 이 둘이 갖는 한계가 다르기 때문에 서로를 보완할 수도 있다는 점이다. 바로 이 점이 사회과학 분야에서 게임 데이터 에 관심을 가져야 할 큰 이유가 아닐까 싶다. 게임 분야에서는 플레이어의 행태를 세밀하게 기록한 데 이터를 이용해서 여러 가지 분석이 진행되고 있다. 다른 어떤 분야보다 풍부한 데이터를 토대로 폭넓은 분석이 가능하며, 심지어 현실에서 관측하기 힘든 사건들까지 세밀하게 분석할 수 있다. 그래서 게임에는 단지 게임 플레이어뿐만 아니라 데 이터 분석가의 마음까지 빠져들게 하는 매력이 있다. - 현상을 완벽하 게 설명하는 통계모형은 존재하지 않는다. 또한 이는 통계학 의 목적에도 부합하지 않는다. “모든 모형은 틀렸다. 하지만 어떤 것은 유용하다 All models are wrong, but some are useful.” 13 통계학 을 진지하게 공부한 독자라면 아마 한 번은 들어봤을 유명한 인용구다. 이 인용구의 핵심은 이렇다. 유용한 모형이란 복잡한 사회 현상을 이해하는 최대한 간결한 틀을 제공한다는 말이다. 불필요한 디테일은 무시하되 관심 현상을 특정 맥락에 서 의미있게 이해할 수 있다면 설령 '틀린' 모형일지라도 충분히 유용하다는 것이다. 우리는 충분한 객관적인 데이터와 엄밀한 모형 설계를 통해 머니볼 가설을 다차원적으로 검정했다. 즉 머니볼 효과는 실재했다고 결론 내릴 수 있다. - “Adapt or Die.” '적응하지 못하면 죽는다'는 뜻의 이 대사는 영화 〈머니볼>에서 빌리 빈이 데이터 기반 선수 선발에 반 발하는 스카우터들과 대립할 때 자신의 관점을 관철시키려 한 말이다. 언더독 신화라는 영화적 서사 이면에 머니볼 효과가 갖은 함의는 궁극적으로 현대 데이터 과학이 지향하는 바와 같다. 그것은 방대한 데이터 사이에서 연관성 혹은 유의미한 패턴을 발견하고 이를 의사 결정에 반영하는 것이다. 데이터 기반 의사 결정의 가장 큰 도전은 직관이나 경험을 배반하는 분석 결과를 대하는 의사 결정자의 태도라고 할 수 있다. 익히 알려졌듯 머니볼의 핵심 가설들은 이미 1970년대 야구광이자 야구 분석의 선구자라 불리는 빌 제임스 Bil James 에 의해 제시된 해묵은 아이디어였다. 하지만 이 흥미로운 분석 결과가 경기에 반영되기까지는 무려 30여 년이 걸렸다. 스포츠는 다른 분야에 비해 상대적으로 객관적 데이터를 수집하기가 쉽다. 하지만 스포츠만큼 경험과 직관이 지배하는 분야또한 드물다. 결국 이 치열한 경쟁에서 살아남기 위해서는 스포츠 경기력 데이터의 한계와 가능성을 이해하고, 의사 결정 과정에 이를 유연하게 적용하는 능력이 있는지가 관건일 것이다.
- 중요한 것은 지적인 기계가 어떤 감정을 가질 수 있느냐가 아니라 기계가 감정 없이도 지능을 가질 수 있느냐는 것이다. (마빈 민스키) - 초기 인공지능 학자로 노벨 경제학상을 받은 사이먼은 1965년에 “20년 후에는 기계가 사람이 할 수 있는 모든 일을 할 수 있게 된다”고 주장했다. 인공지능의 대부 민스키(Marin Mind, 도 유사한 이야기를 했다. 1970년 한 잡지와의 인터뷰에서 민스키는 3 년 내지 8년이면 보통 인간이 갖고 있는 일반 지능을 갖춘 기계가 나타날 것”이라고 주장했다. 돌이켜보면 이들의 주장이 얼마나 황 당한 것이었는지 알 수 있다. 당시 연구원은 이렇게 과도한 낙관론을 갖고 있었다. 인공지능 기술 성장에 대한 낙관론은 계속 이어지고 있다. 2005년에 미래학자 커즈웨일 Rapmond Kurzweil은 "2029년이면 튜링 테스트를 통과하는 컴퓨터가 나올 것”이라 예측했다. 2020년대 중반까지 인간지능 모델이 만들어지고, 이 모델의 능력이 생물학적 신체와 뇌의 한계를 초월하는 특이점이 2045년쯤에는 나타날 것이라고 주장했다. - 불확실성이 존재하는 세상을 에이전트가 어떻게 생각 하는가에 따라서 문제 해결의 방법이 다르게 된다. 에이전트의 생각은 그 나름의 세상 모델' 이다. 모델이란 현실 세계의 복잡한 현상을 추상화하거나 가정 사항을 도입하여 단순하게 표현한 것이다. 복잡해서 단순화하지 않으면 제한된 자원으로 문제를 해결할 수 없다. 그러나 과도하게 단순화하면 현실과 동떨어져서 효용성이 없다. 에 이전트가 활동하는 세상 모델'을 교과서에서는 통상 일곱 가지 관점으로 체계화한다. 첫째, 결정론적 · 확률적 관점이다. 외부 환경의 이전 상태 및 에이전트의 행동에 따라 발생한 다음 상태가 완벽하게 예측 가능한 경우, 이러한 세상의 성격을 결정론적이라고 한다. 가장 단순하게 세상을 보는 것이다. 상태를 확률적으로 일어날 수 있다고 보면 복잡도는 증가한다. 둘째, 정적 · 동적 관점이다. 에이전트가 정보를 얻은 후 행동을 취할 때까지 세상이 변하지 않고 고정되어 있다고 가정하면 이런 세상을 정적이라고 한다. 그 반대라면 동적이라고 한다. 세상을 동적으로 본다면 문제 풀이가 훨씬 어려워진다. 동적 세상에서는 일반적으로 신속히 반응해야 한다. 반응이 늦으면 버스 지나간 다음에 손드는 격이다. 셋째, 관측 가능성으로 구분하는 것이다. 에이전트가 완벽히 관찰할 수 있는 세상이 있는가 하면, 부분만 관찰할 수 있는 세상도 있다. 물론 관찰 자체가 힘든 세상도 있다. 완벽히 관찰할 수 있는 세상에서는 의사결정이 상대적으로 쉽다. 예로, 바둑 게임은 게 임에 참여하는 두 명의 에이전트가 세상을 모두 볼 수 있다. 바둑 돌이 놓인 바둑판을 모두 볼 수 있기 때문이다. 그러나 포커 게임은 그렇지 않다. 게임의 상황을 일부만 알 수 있다. 상대방의 카드는 볼 수 없기 때문이다. 넷째, 존재하는 에이전트의 수로 세상을 구분할 수 있다. 다수의 에이전트가 존재하는 세상은 훨씬 복잡하다. 에이전트들이 협조하거나, 경쟁하거나, 무관심할 수 있다. 게임 상황에서는 에이전 트들이 팀을 형성하여 경쟁하는 경우가 많다. 다섯째, 세상에 관한 사전 지식의 유무다. 세상을 지배하는 법 칙을 에이전트가 사전에 알고 있다면 '알려진 세상' 이라고 간주한 다. 반대의 경우, 에이전트는 환경을 지배하는 법칙을 모른다. 따라서 에이전트가 자원을 동원하여 세상의 법칙을 발견해가야 한다. 여섯째, 단편적 · 순차적 관점에서 세상을 구분한다. 단편적 관점에서는 세상의 변화를 단편적 사건의 집합으로 본다. 따라서 의사결정하는 데 있어서 현재 상태만 고려하면 된다. 반대로 순차적 관점에서는 변화가 과거 사건의 영향으로 바뀐다고 본다. 따라서 과거의 상태를 모두 기억해야만 현재 최적의 행동을 결정할 수 있다. 일곱째, 이산·연속의 관점이다. 이산Discrete 환경에서는 위치나 시간의 간격이 고정되어 있다. 예를 들면, 초 단위로 시간을 표현 한다고 할 때, 초 이하의 시간은 무시된다. 그러나 연속적 환경에서는 위치나 시간이 연속된 선상의 한 점이다. 따라서 원하는 정밀도 수준으로 측정하여 정량화해야 한다. 에이전트가 세상을 어떤 관점으로 보느냐에 따라서 문제의 난이도는 천차만별이다. 또한 도출된 해결책이 얼마나 현실적인가도 결정된다. 외부 환경 중 부분만 관찰 가능하고, 확률적, 순차적, 동 적, 연속적이면서 다수의 에이전트가 존재하는 상황이 여러 문제 해결 중 가장 어려운 환경이다. 가급적 현실성 있도록 세상을 봐야 겠지만, 문제 해결의 복잡도를 감소하기 위해 단순화를 피할 수 없는 경우가 많다. - 높은 산을 오르려면 낮은 산은 내려와야 언덕 오르기나 급경사탐색 알고리즘은 탐색 중에 산을 나려는 방향으로는 움직이지 못한다. 낮은 봉우리를 넘어서 높은 산으로 올라가려면 내려가는 길도 거쳐야 한다. 이것을 가능하게 하는 것이 모의 담금질Simulated Annealing 알고리즘이다. 금속의 담금질에서 영감을 받은 이 탐색 알고리즘은 가끔 의도적으로 나쁜 방향을 선택하기도 한다. 나쁜 방향이란 목적함수의 값을 올리는 것이 아니라 낮추는 방향이다. 나쁜 방향을 선택함으로써 낮은 봉우리를 벗어날 가능성이 생긴다. 나쁜 방향 선택의 빈도는 확률로 조정한다. 탐색 초기에는 확률을 높여서 나쁜 행동이 자주 선택돼 넓은 범위 를 탐색할 수 있게 하고, 탐색이 진행되면서 점진적으로 확률을 낮 춰 탐색 범위를 좁힌다. 잘 찾아온 최정상 근처에서 벗어나지 않도록 하게 함이다. - 기계 학습이란 훈련데이터집합을 잘 표현하는 모델을 만드는 작업이다. 즉, 모델의 틀을 설정하고 훈련데이터집합을 잘 표현하는 파라미터(매개변수)값을 구하는 작업이다. 기계 학습에서 특히 관심 있는 것은 입력과 출력 간 함수 관계의 모델이다. 전통적인 기계 학습 기법에서는 모델의 틀로써 수식을 주로 사용했다. 선형함수 또는 간단한 비선형함수가 많이 쓰였다. 수식 모델은 독립변수, 종속변수, 파라미터 등으로 구성된 방정식이 일반적이다. 확률적인 현상을 모델링할 때는 확률함수를 사용한다. 인공 신경망 기법에서는 노드와 연결선으로 구성된 망구조를 모델의 틀로 사용한다. 주어진 망구조에서 훈련데이터집합을 가장 잘 표현하는 파라미터값을 구하는 것이 모델링이다. 단순한 수식을 사용하는 것보다 훨씬 표현력이 좋다. 그래서 요즘 다양한 문제를 인공 신경망을 이용하여 해결한다. 과거에는 망구조를 개발자 의 경험과 직관에 의하여 미리 설정하는 것이 일반적이었다. 그러 나 요즘은 적합한 망구조를 찾는 과정도 자동화되었다. 다양한 망 구조와 파라미터 최적화를 시도한 후에 가장 바람직한 모델을 선택하는 것이다. 오토엠엘AutoML, Automated Machine Learning 이 이런 목적의 도구다. - 지도 학습을 위한 훈련데이터 집합의 구축에는 많은 비용과 노력이 소요된다. 비지도 학습은 이런 노력이 필요 없기 때문에 매력적이다. 그러나 비지도 학습에 비해 지도 학습은 패턴 분류 문제 풀이에서 더 우수한 성능을 보인다. 직접적으로 가르침을 주기 때 문이다. 라벨이 주어진 데이터와 주어지지 않은 데이터를 섞어서 훈련에 사용하면 우수한 성능과 비용 절감의 두 가지 효과를 모두 얻을 수 있을 것이라 기대된다. 이런 방법을 준지도 학습Semi-Superised Learming 또는 자기주도 학습Self Supervised Learning 이라고 한다. 소비자의 구매 이력을 이용하여 신상품을 추천하는 데에는 군집화 방법이 사용된다. 소비자 A와 소비자 B가 유사한 구매 패턴을 갖고 있다는 것은 비지도 학습으로 확인했다면 소비자 A가 구매한 물건을 소비자 B도 구매할 것이라는 믿음으로 추천한다. 이렇게 하면 무작위로 추천하는 것보다 소비자들이 추천을 받아들일 확률이 높다. 또 일상적이지 않은 이상 상태의 발생을 탐지하거나 고장 예측에도 군집화 방법이 활용된다. - 차원 감소 문제 데이터의 차원이란 표현에 사용된 특성의 개수다. 너무 많은 수의 특성으로 데이터를 표현하면 그 데이터가 갖는 깊은 의미를 나타내지 못하는 경우가 많다. 꼭 필요한 특성만으로 데이터를 표 현하면 데이터가 갖는 깊은 의미를 표현할 수 있고, 계산도 간편할 수 있다. 적은 수의 중요한 특성으로 데이터를 표현하기 위해 차원 축소)rmensionality Reduction 라는 작업을 한다. 높은 차수의 데이터를 축약 하여 낮은 차수의 데이터로 만드는 것으로 학습하기 좋은 형태로 데이터를 변형하는 전처리 방법이라고 볼 수 있다. 차원 감소를 위 해서는 주성분 분석, 오토엔코더Autoencode, 등이 자주 사용된다. - 주성분 분석Principal Component Analysis 은 통계적 방법에서 자주 쓰는 방법이다. 데이터 분산을 크게 만드는 적은 수의 특성을 선택하여 선형으로 변환한다. 높은 차원의 공간이 낮은 공간으로 축소되는 것이라 볼 수 있다. 변환 과정에서 정보를 잃어버리긴 하지만 중요한 특성은 유지되고 데이터 분별이 쉬워질 것을 기대한다. 오토엔코더는 데이터 차수 감소의 목적으로 자주 사용되는 인공 신경망 기법이다. 라벨이 없는 학습데이터에 대해 입력과 동일 한 출력을 내도록 지도 학습으로 훈련시킨다는 아이디어에서 출발 한다. 인코더와 디코더로 구성된다. 인코더는 입력을 은닉 노드로 변환하는 것이고 디코더는 은닉 노드에서 다시 원래 데이터로 재 현하는 것이다. 입력층 노드보다 은닉 노드를 적게 하면 은닉 노드 의 출력을 감소된 차원의 데이터 표현으로 볼 수 있다. 오토엔코더 는 비선형 변환이 가능하다. 오토엔코더의 역할은 강력한 특성을 추출하기 위한 의미적 변환으로 볼 수 있다. - 기계 학습을 한다는 것은 기계 학습 알고리즘을 사용하여 훈련데이터집합을 잘 표현하는 모델을 구하는 것이다. 학습과정의 핵심은 모델의 틀을 미리 설정한 후에 최적의 파라미터값을 구하는 것이다. 기계 학습의 작업과정은 그림과 같다. 훈련데이터 준비가 처음 해야 할 작업이다. 훈련데이터 수집은 많은 노력이 소요된다. 특히 지도 학습을 위한 데이터는 라벨을 모두 붙여야 하기 때 문에 많은 수작업이 필요하다. 해결하고자 하는 문제의 유형에 따라 적절한 기계 학습 알고리즘을 선택해야 한다. 알고리즘에 따라 학습 결과의 성능과 요구되는 계산량의 차이가 많다. 따라서 알고리즘의 본질과 장단점을 잘 이해하는 것이 중요하다. 간단한 패턴 분류를 위해서는 전통적인 의사결정나무 기법과 선형 경계선 분석 알고리즘 등으로 충분할 수도 있다. 군집화를 위해서는 K-평균 알고리즘이나 계층적 군집화 방법 등을 단순한 거리 개념과 같이 사용할 수 있다. 이 방법들은 대부분 통계적 추론 기법으로 오래전부터 잘 알려진 알고리즘들이다. 인공 신경망 기법은 최근 딥러닝 기법이 알려짐에 따라 다시 각광받고 있는 강력한 방법론이다. 인공 신경망 알고리즘은 지도 학습, 비지도 학습, 강화 학습 등에 모두 사용할 수 있다. 다양한 문제에 적용할 수 있는 매우 일반적인 방법론이다. 다양한 망구조에 따라 기능과 성능이 다르기 때문에 깊은 이해와 개발 경험에 의한 통찰력이 필요하다. 공개 소프트웨어로 만들어진 개발 도구들을 사용할 수 있는 이점도 크다. 이 방법론은 뒤에서 자세히 다를 것이다. 학습 알고리즘을 결정했으면 모델의 틀을 결정해야 한다. 모델의 틀은 학습 알고리즘을 정하고 나면 선택의 여지가 좁혀진다. 전통적인 방법에서는 패턴 분류의 경계선 형태는 어떤 것으로 할 것인가, 회귀분석에서는 선형으로 혹은 2차 다항식으로 할 것인가 등을 결정한다. 인공 신경망 기법을 사용하겠다고 결정했으면 망 구조를 결정해야 한다. 입출력층의 노드 개수는 문제의 성격이 결정해주겠지만 은닉층의 구조는 선택의 여지가 많다. 순환 경로를 둘 것인지, 계층적으로 구성할 것인지 등 망구조가 인공 신경망의 기능과 성능을 결정한다. 데이터의 양에 따라 연결선, 즉 망의 파 라미터 수를 제한하는 것이 바람직할 수도 있다. 그래야 새로운 입 력에 잘 작동한다. 이런 문제를 일반화 문제라고 하는데 다음 장에 서 다룰 것이다. 모델의 틀, 즉 구조가 결정되면 최적의 파라미터를 탐색하는 작업을 수행한다. 이 작업이 바로 최적의 모델을 선정하는 작업이 다. 이 과정은 컴퓨터가 수행한다. 많은 컴퓨팅 자원이 소요된다. 훈련의 속도와 성능을 결정하는 여러 가지 하이퍼 파라미터가 있는데 그 하이퍼파라미터의 성격을 잘 이해하고 결정해야 한다. 이것저것 시도해보고 결정하는 것이 일반적이다. 학습의 결과인 모델의 성능을 평가하는 것이 마지막 작업이다. 평가의 핵심은 새로운 데이터에 얼마나 잘 작동하는가를 보는 것이다. 그래서 훈련데이터와는 별도로 평가용 데이터집합을 준비한다. 평가에서 부족함이 발견되면 모델의 틀을 변경하거나 하이퍼파라미터값을 변경해 가면서 좋은 모델 찾기를 반복한다. - 고등 동물은 자주 보는 손, 얼굴 등을 인식하기 위해 그 물 체 집합에만 반응하는 상위 수준 특성을 사용한다고 알려졌다. 해 당 특성들은 많은 노출에 의하여 자율적으로 학습된다는 이론이 있다. 또 자주 보는 할머니 모습과 같이 복잡한 상위 개념이나 특 정 물체에만 활성화되는 신경세포가 우리 뇌에 존재한다는 이론이 있다. 이를 할머니 신경세포' 라고 한다. 2012년 구글은 영상에서 신경망이 복잡한 물체를 자율적으로 발견할 수 있는지를 실험했 다. 연결선이 10억 개인 고층 신경망에 2만 개의 물체가 나타나는 1,000만 개의 영상을 라벨 없이 보여주었는데 물체의 존재 여부가 자율적으로 훈련이 되었다. 정확도는 사람 얼굴은 81.7%, 고양이 는 74.8%였다. 또 사람 얼굴과 고양이는 각각 다른 노드를 활성화 시켰다. 이 실험은 할머니 신경세포의 가설을 증명한 것이라고 볼 수 있다. - 자연어는 애매하다. 상황에 따라 단어의 역할, 의미가 달라진다. 의미만 전달하는 것이 아니라 감정 등 부수적인 정보도 전달한다. 이를 위하여 동일한 객체나 현상이 여러 가지 방법으로 표현된다. 특히 대화에서는 같은 의도나 감정도 여러 가지 스타일로 표현된다. 문맥의 변화 속에서 의미와 감정을 파악하는 것이 가장 어려운 문제다. 명시적으로 제시되지 않은 상식과 세상 모델을 이용하기도 해야 한다. 이 문제를 해결하기 위해 문장에서 함께 나타나는 단어들과 그들의 역할을 평가하는 등 여러 가지 방 법을 시도하고 있다. 하지만 단어의 의미, 궁극적으로 문장의 의미를 이해하는 것은 어려운 문제다. 더구나 자연어의 범위는 매우 넓고, 새로운 어휘가 계속 생기고 의미도 변하는 등 끊임없이 진화하 기 때문에 더욱 어렵다. 그래서 자연어 처리에서는 확률적 판단을 자주 사용한다. 언 어 요소의 발생 빈도를 확률적으로 표현한 확률적 언어모델이 대표적이다. N개의 단어가 연속되었을 때 다음에 나타나는 단어의 빈도를 확률 분포로 표현할 수 있다. 또 특정한 순서로 단어가 앞뒤로 나타났을 때 가운데 단어의 빈도를 표현하는 모델을 심층 신 경망으로 만들기도 한다. 심지어 한 문장이 나온 다음에는 어떤 문 장이 나오는가를 예측하여 이야기를 작성하기도 한다. 최근 각광 받고 있는 GPT-3가 이런 능력이 있다. - 컴퓨터가 자연어를 잘 처리하게 하려면 첫 단계는 언어를 적절히 표현하여 입력하는 것이다. 언어는 단어의 연결로 볼 수 있기 때문에 단어의 표현이 가장 기본이다. 기호 처리적 기법에서는 단어를 심볼로 표현하고 기호적 연산으로 추론 등을 수행했다. 그러나 신경망 기법에서는 수치적 계산을 하기 때문에 단어를 수치로 표현해야 한다. 단어를 N차원의 벡터, 즉 N차원 공간의 점으로 표현하는 기법이 최근 많이 쓰인다. N차원의 벡터 표현에서 의미가 유사한 단어들이 공간상에서 가까운 장소에 모이도록 배치한다면 여러 이점이 있다. '과일' 이라는 단어는 '사과' 와 유사한 위치 에 나타나기 때문에 문장에서 '과일'과 '사과'는 문법적으로는 물론 의미적으로도 유사한 의미로 사용할 수 있다. 유사한 단어들을 모으기 위해 문장에서 함께 나타나는 단어들 의 빈도를 분석한다. 단어의 의미는 문장에서 그 단어와 함께 나오 는 단어의 영향을 받아 결정된다는 언어학 이론이 있기 때문이다. 과일이나 '사과'는 먹는다'는 단어와 함께 자주 나오기 때문에 의 미가 유사하다고 간주할 수 있다. 비지도 학습 방법으로 큰 말뭉치 를 훈련용 데이터로 사용하여 단어의 벡터 표현을 구하는 것이 일반적이다. 벡터 표현은 자연어 처리의 성능을 결정하기 때문에 좋 은 벡터 표현 방법의 탐색은 중요한 연구과제다. 이런 표현 기법 하에서는 단어의 의미를 공간상에서 연산을 통해 유추할 수 있다. 벡터 표현이 잘 되었다면 유사한 관계를 갖는 단어 쌍들은 공간상에서 유사한 위치 관계를 유지할 것이다. 그림 에서 보듯이, "KING과 MAN의 관계와 동일한 관계를 WOMAN 과 갖는 단어는?" 이라는 질문을 "KING - MAN + WOMAN = ?"라 는 벡터 계산으로 구할 수 있다. 즉, QUEEN과 WOMAN의 관계 는 KING과 MAN의 관계와 유사하다. - 딥러닝은 여러 인공지능 문제에서 뛰어난 성과를 보이고 있다. 그러나 방대한 학습데이터와 많은 계산이 필요하다는 것이 근본적 약점이다. 누구나 조금만 관심이 있다면, 수백 장의 훈련용 영상데이터와 PC정도의 계산 능력으로도 개와 고양이 사진 분류기'를 만들 수 있을 것이다. 또 간단한 명령어를 이해하는 챗봇도 만들 수 있을 것이다. 그러나 이를 넘어가면 다른 차원의 문제가 된다. 수백만 개의 훈련 데이터를 모아서 가공해야 하고 강력한 GPU 수십 개를 이용하여 며칠 또는 몇 주간 학습을 수행해야 한 다. 현실적으로 이러한 작업은 많은 데이터와 컴퓨팅 자원을 가진 대기업에서만 가능하다. 대기업이 아니면 경쟁력 있는 신경망 모 델을 만들 수 없다는 이야기다. 인공지능 소프트웨어, 특히 기계 학습 도구들이 공개되었지만 많은 데이터와 컴퓨팅 자원이 없다면 그림의 떡일 뿐이다. 전 세계적으로 딥러닝 적용 사례가 늘어나면서 점점 더 많은 컴퓨팅 자원이 데이터 학습에 투입된다. 이 때문에 전력 소비가 급격히 늘어나서 지구온난화를 가속시킨다는 우려 도 있을 정도다. - 이런 문제를 완화할 수 있는 방법이 이미 개발된 신경망 모 델을 개방하고 공유하는 것이다. 이미 개발된 신경망 모델의 구조 와 훈련된 연결 강도 등을 모두 공개한다면, 이것의 성능을 개선하거나 이를 부품으로 사용하여 더 크고 강력한 모델을 만들 수 있을 것이다. 이를 위한 기술이 전이 학습ransfer Learning 이다. 전이 학습 은 이미 습득한 지식을 새로운 문제 해결에 이용하는 기술로써 신경망 기술의 확산과 발전에 크게 공헌하고 있다. 심층 신경망이 점점 다양한 영역에 적용되면서 전이 학습은 딥러닝 모델을 개발하는 데 매우 인기 있는 기술로 떠올랐다. - 기계 학습은 기본적으로 통계적 학습 및 추론 방법이다. 그 성능은 데이터의 양과 질이 결정한다. 훈련 데이터가 많으면 많을수록 좋은 성능을 보인다. 기계 학습에서 필요로 하는 데이터의 양은 모델 파라미터의 수가 증가함에 따라 기하급수적으로 증가한다. 파라미터의 수에 비하여 데이터가 적으면 학습에 사용한 데이터에서는 잘 작동하지만, 새로 보는 데이터에는 잘 작동하지 않는다. 우리가 기계 학습을 통해서 인공지능 시스템을 만드는 이유는 새로운 문제에서 해결책을 얻고자 하는 것인데 이것은 치명적인 약점이다. 더구나 심층' 이란 단어에서 유추할 수 있듯이 심층 신경 망은 많은 수의 노드와 연결로 구성된다. 즉 파라미터의 수가 매우 크다. 따라서 심층 신경망을 훈련시키기 위해서는 방대한 데이터 를 확보해야 한다. 이는 딥러닝 기법의 확산에 큰 장애요인이다. 또 훈련데이터는 정확해야 한다. 특히 지도 학습에 사용되는 입력과 출력 쌍의 훈련 데이터는 철저히 점검하여 정확도를 높여 야 한다. 정확하지 않은 데이터로 훈련시킨다면 그 결과를 보장할 수 없다. 쓰레기 같은 데이터가 입력되면 쓰레기 같은 결과가 나오 는 것은 당연한 이치다. 데이터를 모으고, 빠진 정보를 채워 넣고, 잘못된 데이터를 수정하는 등 데이터 준비 작업에는 많은 노력이 필요하다. 더구나 이 과정은 자동화가 쉽지 않다. 딥러닝에서 다루는 심층 신경망은 매우 복잡하고 방대한 데이터로부터 학습한다. 최근 발표된 GPT-3 자연어 모델은 1,750억 개의 연결선으로 구성되어 있다. 5,000억 개 단어, 700기가바이트 의 문장이 훈련 데이터로 사용되었다. 이렇게 큰 신경망을 훈련시 키는 데에는 강력한 컴퓨터 능력이 필요하다. 이 훈련을 V100이 라는 GPU 한 개로 훈련시키면 200년이 걸린다는 계산이 나왔다. 지구 온난화를 딥러닝이 촉진하다는 비판이 빈말이 아니다. - 딥러닝이 활성화된 2012년 이후부터 2018년까지 컴퓨터의 계산 요구는 30만 배가 증가했다고 한다. 데이터의 양에 따른 계산량은 기하급수적으로 증가했지만 학습 결과의 정확성은 로그함수로 증가한다. 그러나 가장 큰 이유는 점점 더 큰 심층 신경망을 개발하고 더 많은 데이터로부터 학습하기 때문이다. 엄청난 규모의 데이터와 컴퓨터 능력이 필요하기 때문에 딥러닝 연구와 심층 신경망 개발은 일부 글로벌 대기업에서만 가능하다. 상대적으로 부유 한 미국 대학에서도 우수한 연구원들이 더 나은 연구 환경을 찾아 기업으로 이탈하는 현상이 나타났다. 개발도상국 대학에서는 꿈도 못 꿀 지경이다. 자동차, 공장 등 인공지능을 필요로 하는 현장에서 직접 학습 하고 학습결과를 운용해야 할 필요성이 커지고 있다. 또 노트북이 나 스마트폰에서도 기계 학습을 수행하고, 그 결과를 실시간으로 운용할 수 있다면 인공지능이 빠르게 확산될 것이다. 현장의 기기 에서 학습하고 활용하는 것을 엣지 컴퓨팅이라고 한다. 이를 위해 신경망 계산을 가속화하는 반도체 칩의 개발 경쟁이 치열하다. 학습 효율을 높여서 적은 데이터로 효율적으로 훈련하는 방법에 대한 관심도 높아졌고 적은 컴퓨팅 자원으로 딥러닝을 수행하려는 녹색 인공지능의 연구도 시작되었으나 아직 성과는 미미하다. 많은 데이터와 컴퓨팅이 필요한 현재의 딥러닝 기법은 개선되어야 한다. 고양이 모습을 이해하기 위해 수백만 장의 고양이 사진과 며칠에 걸친 계산이 필요하다는 것은 난센스다. 새로운 돌파구가 필요하다.
- 한국에서 정말 키오스크 도입으로 인건비를 줄이고 있는지는 정확한 데이터를 확인해봐야 알 수 있습니다. 그런데 일단 독일, 호주 등 다른 국가를 보면, 대부분의 매장에서 맥도 날드 직원이 음식을 직접 테이블로 서빙합니다. 심지어 주문을 키오스크로 해도 음식은 직접 가져다주곤 하지요. 이를 보면 키오스크의 설치가 단순히 고용을 줄이기 위해서 하는 게 아니라는 것을 알 수 있습니다. 그렇다면 키오스크 설치의 목적은 무엇일까요? 바로 주문량 증가입니다. 실제로 키오스크를 통해서 주문을 받았더니 사람들이 주문을 더했다는 결과도 있습니다. 다만 국내에서는 키오스크의 확산과 보급이 당시 최저임금제 이슈와 맞물려서 많이 보도되었지만, 맥도날드가 키오스크를 도입하게 된 진짜 이유는 실은 비용 절감 때문이 아니라 주문량을 늘리기 위한 시도였던 것입니다. 또한, 많은 고객을 대상으로 조사해보니 사람들은 키오스크 앞에서 주문할 때 대화하지 않고 화면을 직접 누르니 조금 더 마음이 편하고 일순간이지만 자기가 전지전능해진 듯한 감각을 느꼈다고 합니다. 특히 요즘 화두인 디지털 네이티브 세대의 경우에는 디지털 화면이 더 편하다는 장점도 있습니다. 그들의 입장에서는 사람을 대하는 것이 더 힘들고 때로는 피곤하기까지 합니다. - 이런 현상은 국내에서도 많이 벌어지고 있습니다. 국내에서도 배달 애플리케이션 산업의 활성화 이유가 사람들이 전화 거는 일을 불편하게 느끼기 때문이라는 분석이 있습니다. 다들 전화하는 일을 내심 힘들어합니다. 오히려 비좁은 화면을 손가락으로 꾹꾹 누르는 것이 심리적으로 편합니다. 어쩌면 인류가 그렇게 진화하는 것 같기도 합니다. 이전에는 주문을 받는 직원과 대면해서 거북해하면서 했던 주문을 이제는 손안에서 마음 편하게 하고 싶어 합니다. 또한, 많은 사람이 화면 앞에서는 조금 더 마음 편하게 여러 가지 조합도 해보고 지금까지 하지 않았던 맛의 조합도 실험해보는 등 조금 더 자유롭게 행동합니다. 이처럼 디지털이라는 것이 고객에게 전지전능한 느낌을 줄 수 있고 그 느낌을 우리 기업의 고객에게도 전해줄 수만 있다면 예전에는 미처 생각하지 못했던 기회가 생길 수도 있습니다. - 맥도날드가 이처럼 여러 가지 일을 굉장히 많이 시도한 것은 실질적인 성과와 움직임으로 드러나고 있습니다. 맥도날드는 디지털 트랜스포메이션을 위해 여러 테크 기업들을 인수했습니다. 다이나믹 일드도 그렇게 인수한 기업입니다. 다이나믹 일드는 빅데이터를 활용해서 인공지능으로 추천 알고리즘을 만드는 기업입니다. 또한, 음성 인식을 통해서 드라이브 스루에서 음성으로 주문을 받을 수 있도록 해주는 기업도 인수했습니다. 모바일 애플리케이션 개발 업체도 인수했습니다. 패스트푸드 기업인데도 실제로는 엔지니어의 근거지를 늘린 셈입니다. 그러면서 한편으로는 기술 연구소인 맥도날드 테크랩이라는 기구를 실리콘밸리 한가운데에 뒀습니다. 마치 테크 기업인 것처럼 보이려는 의도가 농후합니다. 또한, 그런 뉘앙스를 풍기는 사업 전략도 공표했습니다. 맥도날 드는 이처럼 디지털 기술을 통해서 익숙하고 오래된 비즈니스를 바꿔보겠다며 디지털 트랜스포메이션의 기치를 내걸었습니다. 맥도날드의 이런 시도들의 공통점은 모두 소프트웨어에 기반을 뒀다는 것입니다. 맥도날드가 그야말로 좌충우돌하면서 다양한 시도들을하는 와중에도 우리는 이 점을 눈여겨봐야 합니다. 그리고 그들이 왜 이렇게 자신감과 확신을 가지고 디지털 트랜스포메이션을 하려고 하는 지 깨달아야 합니다. 우리의 상식으로는 IT와 멀리 떨어져 있다고 여겨지는 이런 기업들조차 왜 디지털 트랜스포메이션을 지속해서 시도할까요? 바로 그들이 IT, 특히 소프트웨어가 가져온 변화와 효율에 대해서 체감했기 때문입니다. 맥도날드와 스타벅스는 구글이나 마이크로소프트 등의 테크 기업 과 함께 코로나19의 타격을 가볍게 뛰어넘은 기업으로 손꼽힙니다. 맥 도날드는 백신 보급이 시작된 2021년 봄에 이미 코로나 이전의 매출을 회복했습니다. 맥도날드나 스타벅스가 그렇게 위기를 극복한 이유를 충 성도가 높은 고객을 소유한 덕이라고 생각할 수도 있습니다. 그러나 코로나19로 인한 경기 위축으로 큰 타격을 받은 기업들을 살펴보면 하나같이 충성도가 높다고 여겨지던 브랜드였습니다. - 예전에는 IT를 당연히 코스트 센터 Cost center(원가 중심점), 경영의 시녀라고 생각했습니다. 그래서 지금까지는 IT라고 하면 대부분 내부에서 만든 기획을 외주 업체에 위탁해서 만든 뒤에 다시 가져오는 방식을 취했습니다. 이런 방식에 익숙해져 굳이 직접 몸을 움직일 필요를 느끼지 못하는 일부 IT 구성원 같은 경우에는 디지털 트랜스포메이션을 시도 할 때 수동적 저항 세력이 되기도 합니다. “우리 기업의 업무는 특이하 니까 특수하게 만들어야 한다”, “전부 다 특별 주문 외주로 만들어와야 한다”, “클라우드로 이행하지도 못한다”, “데이터가 우리 전산실 내에 있는 것이 얼마나 중요한데 그러시느냐?”라며 부정적으로 대응합니다. 그러나 이런 문화도 스마트폰의 영향이 전 세계 소비 시장에 퍼지자 점진적으로 바뀌고 있습니다. 비즈니스는 굳어 있는 밸류 체인 위에서 하는 게 아니라 생태계라는 유연한 발상 안에서 벌어지는 일임을 모두가 목격했고, 이제는 그 일이 각자의 조직 앞에 놓인 현실이 됐기 때문입니다. - 기크가 본인의 소중한 시간에 무언가를 공부해서 앞으로도 그것에 의존하겠다고 한다면 이는 큰 결정입니다. 무언가를 스스로 골라서 기 꺼이 의존하겠다고 하는 것, 이 자체가 기크들한테는 상당히 큰 선택입 니다. 그리고 기업이 기크들에게 공부할 수 있는 아이디어를 제공할 때 이 시너지는 더욱 커집니다. 여기에 주목할 만한 점이 있습니다. 기업이 만든 아이디어를 공부한 기크들은 다시 생산자 역할을 하기 시작합니다. 오픈 소스가 잘되는 이유는 기업들이 단지 자기가 쓰기 위해서 만드는 것을 넘어서 조직 밖의 사람들이 쓰게 해주고, 이 과정에서 안팎의 기크들이 그걸 공부하고 다시 그 지식을 확장해서 새로운 가치의 재료를 만들기 때문입니다. 개방성 그리고 호환성, 파급, 확대 재생산 등 일련의 메커니즘이 이렇게 개방되고 공유된 지식 상품을 둘러싸고 움직입니다. 결국, 개발자들과 같은 기크들은 어떤 기업이 가지고 있는 가치, 서비스, 제품을 둘러싸고 커뮤니티를 키워나가게 됩니다. 한편으로, “저희가 만든 거예요”, “저희가 틈틈이 쉬는 시간에 만든 것들을 공개합니다” 등 사소한 일들이라도 개방형으로 공개하면 이는 다른 누군가를 자극하고 또 다른 혁신에도 쓰이게 됩니다. 선의가 점점 파급력을 가지면서 확대 재생산이 이뤄지는 사이클이 생겨납니다. 물론 이런 것들은 이타심에 의해 돌아가는 것처럼 보입니다만, 실은 오픈 소스야말로 지극히 이기주의적인 활동입니다. 훌륭한 오픈 소스를 만들 수 있다는 것은 개발자의 입장에서는 무엇보다도 강력한 경력이 됩니다. 그래도 오픈 소스라고 하면 '그렇게 공짜로 뿌리는 게 과연 믿을 만할까?', 그것을 우리 업무에 쓰는 게 과연 옳은 일일까?'라고 생각 할 수도 있습니다. 그러나 다음의 요소가 오픈 소스의 신뢰도를 보장해 줍니다. - 닌텐도나 소니에게 는 공통점이 있습니다. 이 기업들의 공통점은 놀이의 마음, 그리고 생산 과 창조하는 일이 지닌 낭만성을 어떻게든 지킨 곳입니다. 그런 곳들만 이 지금까지 살아남아서 활발하게 활동하고 있습니다. 그리고 이를 다 른 말로 표현하면 바로 소프트웨어 기업으로 표현할 수 있습니다. 이들 은 소프트웨어의 가치를 중시하고 소프트웨어가 결국 위기에서 자신을 구원한다는 것을 믿었습니다. 이처럼 쓰러진 전자 업계에서 그나마 유 일하게 생존한 분야는 놀이의 마음을 지니고 있고 새롭게 뭔가를 만드 는 것을 정말 재미있다고 느끼는 이들이 있던 분야였습니다. 바로 기크 들의 기업이었습니다. - 그런 장기적인 여유가 우리에게도 있으면 좋겠다고 생각합니다. 여유란 억지로 만들어내는 것입니다. 리더가 위기감을 있는 그대로 인정하고 그런데도 용기를 잃지 않을 때, 사내의 누군가도 지금까지 존재하 지 않았던 걸 만들어볼 용기를 절박함 속에서도 다시 발휘하게 됩니다. 언젠가는 되겠지요. 안 되면 짐 싸서 다 함께 집에 가는 것입니다. “Go Big, or Go Home." 모 아니면 도, 대박 아니면 쪽박, 이판사판을 나타내는 영어 숙어입니다. 이는 스타트업의 만트라이기도 합니다. 물론 여유의 문화라고 말은 하지만, 리더들의 마음은 잘 움직이지 않습니다. 사람의 마음이란 것이 또 그렇습니다. 그렇다면 이를 제도적으로 만들 수는 없을까요? 쉽지는 않습니다만, 방법은 있습니다. - 디지털 트랜스포메이션 과정을 거친 후에 만들어지는 '디지털 제품은 그 개선 속도가 비약적으로 빠릅니다. 개발자, 소프트웨어 엔지니어 들이 그 업그레이드의 주인공들입니다. 그렇게 개선된 제품들은 완성후 고객에게 전달하는 간격이 극단적으로 줄어들 수 있습니다. 특히 소프트웨어 제품의 경우에는 제품을 개선한 후에 고객이 사용할 수 있게되는 때까지 수분의 시간 만에 제품이 출시될 수도 있습니다. 개선된 업무가 100% 디지털라이제이션이 이뤄져 있다면 중간에 수작업이 걸쳐 있는 경우와 비교해서 제품을 엄청나게 빠른 속도로 고객의 손에 쥐어 줄 수 있게 됩니다. 제품을 내고 고객의 피드백을 받아서 제품을 개선한후 다시 제품을 출시하는 이 과정이 빠르면 빠를수록 제품의 고도화가 빨라지고 그 완성도 또한 높아집니다. 이렇게 되면 고객의 만족도가 높아집니다. 급기야는 열광하는 팬이 생기고, 그렇게 바라던 브랜드 로열티도 생깁니다. 즉, 개선 업무가 선순환을 이루고 양적으로 쌓이면 질적변화가 일어날 수 있는 상황이 다가옵니다. 이제 데이터 플레이의 상위 단계로 넘어갈 차례입니다. 기업의 데이터 분석 역량이 향상되면 예측 분석 Predictive analysis 이나 처방 분석 Prescriptive analysis 을 할 수 있는 역량을 갖게 됩니다. 과거나 현재를 분석 해서 이해하는 것보다 미래를 예측하고 예측 결과에 따라서 어떻게 행동하면 좋을지 판단하게 되면 비즈니스 임팩트의 크기가 거대해집니다. 데이터로 일하는 방법에도 고수가 있습니다. 이런 분석 역량을 자유자재로 다루게 되면 거의 고수의 단계입니다. 이 지점에서 분석 역량을 좌지우지하는 것은 이론이나 알고리즘이 아니라 사용할 데이터를 준비 하는 일입니다. 이론이나 알고리즘을 갖추는 일은 단시간에 압축해서 따라잡을 수 있지만, 데이터를 갖추는 일은 시간이 오래 걸립니다. 또한, 필연적으로 하위 단계의 발전을 직접 겪어야 합니다. - 데이터를 기반으로 고객의 만족도를 높이는 경험을 빠른 속도로 여러 번 반복하게 되면 사업적으로 기존과는 다른 경쟁력이 생깁니다. 속도가 충분히 빨라지면 임직원과 고객은 기업이 기존과는 다른 사업을 할 수 있다는 것을 알게 됩니다. 양질 전환, 즉 양이 쌓이면 질적 변화가 나타납니다. 분석 역량도 성숙해져서 현황을 기술 Descriptive 하거나 진단판단Diagnosis 하는 수준에서 예측이나 처방하는 수준으로 업그레이드됩니다. 분석에 필요한 데이터도 미리 갖추게 됩니다. 그중에서도 가장 중요한 질적 변화는 비즈니스 모델의 플랫폼화입니다. 디지털 트랜스포메이션의 성숙도가 진척된 기업들은 제품과 고객을 양면 시장을 가진 플랫폼으로 발전시키게 됩니다. 강력한 제품과 열광하는 팬을 확보한 상태에서 새로운 제품을 공급하게 되고, 새로운 제품으로 인해 고객의 폭을 넓히게 됩니다. 게다가 강력한 데이터의 비즈니스 임팩트를 목격한 다른 사업 주체들과 연계돼 플랫폼을 조성해 더 큰 시장을 창출하게 됩 니다. 이후로는 다른 사업 주체들이 이 플랫폼에 올라타기 위해서 안간힘을 씁니다. 지금도 디지털 트랜스포메이션을 성공적으로 이뤄낸 기업 들을 보면 플랫폼의 문을 열어주지 않았을 뿐이지, 수많은 업체가 문을 열어주기만 한다면 그 플랫폼에 올라타려고 애씁니다. 이쯤 되면 디지털 트랜스포메이션의 완성이라고 할 수 있습니다. - 이미 글로벌 클라우드에는 데이터를 다루기 위한 전문적인 도구들이 많습니다. ETL Extract Transform Load 뿐만 아니라 딥러닝 모델도 자동으로 만들고 하이퍼 파라메터 Hyper-parameter"를 튜닝해줘서 추론Inference 속도를 높이기 위한 모델을 최적화까지 해주고 합니다. SOTA State Of The Art (최신식의) 기술들도 일용품화돼 있어서 필요한 만큼 즉시 활용할 수 있습니다. 문제는 이런 도구들을 어떻게 엮어서 유기적으로 동작하게 하느냐겠지요. - 데이터가 만들어져서 데이터웨어하우스DW, Data Warehouse 나 데이터레이크 Data Lake에 저장되면 API Application Programming Interface를 통해 필요한 데이터를 가져가는 세일즈포스 같은 플랫폼이나 태블로 같은 분석 · 시각화 솔루션들은 이미 널리 활용되고 있습니다. 게다가 이런 솔루션들은 SaaS Software as a Service (서비스형 소프트웨어)나 PaaS Platform as a Service (서비스형 플랫폼) 형태의 클라우드로 제공되고 있습니다. 버튼 몇 번만 누르면 사용 가능한 상태로 바로 앞에 놓입니다. 이렇게 필요한 기술은 예산사용을 승인받는 즉시 활용할 수 있습니다. 5단계까지 진행되면 업무에 실시간성이 생성됩니다. 업무의 속도가 생각의 속도에 가깝게 빨라집니다. 즉, 좋은 생각이 나면 바로 실행해볼 수 있게 됩니다. - 데이터 플레이 조직을 구성할 때 필요한 직군과 역할 * 데이터 프로덕트 매니저 Data Product Manager 데이터 프로덕트 매니저는 데이터를 가져가서 사용할 조직과 원활한 대 화가 가능해야 합니다. 또한, 개발자나 데이터 사이언티스트와의 소통도 가능해야 합니다. 디지털 조직과 기존 조직은 둘 사이에 통역사가 필요하다는 말이 있을 정도로 두 조직 간의 대화가 쉽지 않습니다. 생각하는 사고방식이나 우선순위를 결정하는 철학뿐만 아니라 용어가 아예 다른 경우도 있습니다. 데이터 프로덕트 매니저는 이런 상황에서 안내가 가능해야 합니다. 즉, 양측에 대한 이해가 있어야 하는 만큼 확보하기 어려운 인적 자원입니다. * 클라우드 엔지니어 Cloud Engineer 클라우드 엔지니어는 필요한 솔루션을 찾아내고 평가해서 가장 적합한 솔루션이 무엇인지 판단할 수 있는 안목이 필요합니다. AWS, GCP, 애저는 모두 각각 장점이 있는 솔루션들을 포함하고 있으므로 다수의 클라우드 서비스를 동시에 이용하는 멀티 클라우드가 대세가 됐습니다. AWS에서는 외부의 클라우드를 이용하는 개발자들을 빌더 Builder라고 부릅니다. 본인들이 제공하는 솔루션을 마치 블록 쌓듯이 쌓아 올리면 그것만으로도 서비스를 구축할 수 있다고 이야기합니다. 그 명칭처럼 클라우드 엔지니어의 주요한 역할은 클라우드에서 제공하는 수많은 Saas, PaaS 중에서 필요한 솔루션을 찾고 그것들을 엮어내는 데 있습니다. * 데이터 사이언티스트 DS, Data Scientist 예측 분석을 진행하거나 복잡한 분석 과제를 진행하다 보면 통계 지식과 소프트웨어 개발 지식이 동시에 필요한 경우가 많습니다. 데이터 사 이언티스트는 무엇보다도 클라우드상의 솔루션을 이용할 때 해당 솔루 션이 결과로 제시하는 용어와 수치를 보고 현상을 이해하고 개선 방안을 제시할 수 있는 전문성이 필요합니다. 데이터를 의미 있게 만들어내기 위해서 해야 할 일과 하지 말아야 할 일을 정할 수 있는 리더십도 중요합니다. * 데이터 엔지니어 DE, Data Engineer 데이터 사이언스 Data Science 과제의 80%는 데이터를 다듬는 일이라고 합니다. 빅데이터 플랫폼BDP, Big Data Platform에 데이터를 얹기 위해서는 ETL 작업을 진행해야 합니다. 데이터 엔지니어는 원천 데이터를 받아서 다듬고 사용하기 쉽도록 변형해서 빅데이터 플랫폼에 올립니다. 유의해야 할 점은 업무 난이도보다는 전체 업무량이 기하급수적으로 늘어날 수 있다는 점입니다. 수작업으로 업무의 완성도를 높였다면 늘어나는 업무를 소화하기 위해서 자동화를 할 수 있어야 합니다. * 데이터 애널리스트 DA, Data Analyst 데이터 애널리스트는 현업 업무 진행에 대한 이해, 즉 도메인 지식Domain knowledge을 가지고 데이터를 분석하는 업무를 진행합니다. 그래서 데이터에 담긴 사업적 의미를 누구보다도 잘 이해하고 있어야 합니 다. 물어보지 않는 질문에 대해서는 어떤 데이터도 대답해주지 않습니다. 데이터를 읽고 그 의미를 파악할 수 있는 데이터 감수성과 데이터 문해력이 매우 필요한 역할입니다. - 데이터 사이언티스트와 데이터 애널리스트는 역할을 묶을 수 있으 나 데이터 사이언티스트의 인건비가 워낙 비싸므로 한 명의 데이터 사이언티스트에 주니어 데이터 애널리스트를 여러 명 두는 방식이 일반적입니다. 클라우드 엔지니어와 데이터 엔지니어도 역할을 묶을 수 있으나 그렇게 하면 각각의 전문성이 살아나지 못할 수도 있으므로 할 수 있다면 분화하는 편이 좋습니다. 클라우드 업계의 변화 속도가 워낙 빨라서 클 라우드 엔지니어는 새로운 기술을 파악하고 습득하기에도 바쁩니다. 반면에 현장에서의 활용 방안이 도출되는 것은 오히려 속도가 느린 편이라 메가존이나 베스핀글로벌 같은 국내의 외부 클라우드 전문 벤더를 고용하기도 합니다. 대기업에서는 데이터 조직을 만들 때 최소 3명 정도는 확보하고 시작해서 5명까지 모은 후 하나의 팀으로 성장시키는 것이 일반적입니다. 이후로 업무 진행이 능숙해지면 다수의 인원이 같은 역할을 수행하도록해서 학습 조직으로 성장할 수 있습니다. - 데이터에는 비즈니스 로직이 담겨 있습니다. 그것을 탐색하는 사람은 우선 데이터에 관심을 가져야 합니다. 데이터를 봐도 마음으로 봐야 보이는 것이 있습니다. 어린 왕자가 말하듯이 마음으로 보아야 잘 보이는 일이니, 신기합니다. 그냥 흘려듣듯이 데이터를 숫자로만 보고 의미를 파악하지 못하면 아무것도 이해되지 않습니다. 마음으로 데이터를 보고 그 의미를 파악하는 능력을 데이터 감수성'이라고 부릅니다. 고급 데이터 사이언티스트가 되려면 이 감수성을 키워야 합니다. 몇 번이나 들여다보고도 의미를 이해할 수 없다면 이제는 비즈니스 로직을 이해할 수 있는 사람을 찾아서 물어야 할 때입니다. 물어볼 때는 내가 이해할 수 있도록 처음부터 모든 것을 다 설명해달라고 하는 대신에 이 데이터 를 이렇게 보고 저렇게도 보았는데 이런 부분이 납득되지 않으니 어떻 게 생각하는지 물어봐야 합니다. 자기 밥그릇인 업무 노하우를 친절하게 거저 가르쳐줄 위인은 큰 조직일수록 쉽게 찾기 힘듭니다. 적어도 그 답변을 요구할 만큼 나도 데이터를 들여다봤다는 것을 내세우고, 실은 당신도 내가 궁금해하는 그것을 의아해하고 있지는 않은지 공감대를 불러일으켜야 좋은 답변을 들을 수 있습니다. 그 정도는 해야 업무 협업이 이뤄지고 다른 사람의 업무 노하우를 나눠 받게 됩니다. - 데이터를 더 많이 보여줘야 합니다. 탐색적 분석과 인사이트 리포트가 도움이 될 수 있으니 충분히 활용하면 좋습니다. 데이터를 쉽게 이해할 수 있도록 시각화 Visualization 하고 사업의 목적과 인사이트 리포트에서 다루는 주제의 합을 맞춰야Align 합니다. 이 단계에서 곧잘 하는 실수가 있습니다. 바로 데이터 사이언티스트들이 알고리즘이나 도구를 강조하는 것입니다. 정작 데이터를 이용해야 하는 이들은 사업의 내용을 잘 알고 있는 분들입니다. 데이터 안에서 비즈니스를 더 잘할 수 있는 단초를 찾아내면 함께 업무 협의를 할 수 있는 커다란 여지가 남아 있습니다. 그런데 그런 데이터 자체에 집중하지 않고 낯선 외래어를 남발하면서 가능성만을 제시하곤 합니다. 알고리즘 이나 도구에 집중해서는 안 됩니다. 중요한 것은 데이터를 활용한 결과가 사업에 가져올 영향력입니다. - 전통적 마케팅에서는 마켓 세분화 Market segmentation 를 중시합니다. 대기업에서 마케팅 캠페인을 집행하려면 에이전시를 이용하기 마련인데, 캠페인이 어느 정도 규모가 돼야 에이전시에 업무를 요청할 수 있습니다. 그러나 이제는 디지털 마케팅으로 전환되면서 온라인을 활용해 개 인화 마케팅 Personalization marketing을 할 수 있게 됐습니다. 데이터가 더 늘어난 만큼 고객을 더 자세히 이해하게 됐으며 여기에 더해 데이터 분석역량이 성숙해지면서 초개인화 마케팅 Hyper Personalization marketing 으로 전환하게 됩니다. 데이터가 충분히 늘어나고 예측 분석의 정확도가 높아지면 이제 기존 구매 고객의 데이터를 기반으로 가장 비슷해 보이는 잠재 고객의 목록을 만들 수 있습니다. 유사 타게팅 Lookalike modeling 이라고 불리는 방식으로 이상적인 잠재 고객을 찾아낸 후에 예측 모델링을 통해서 이들이 얼마나 구매할 것 같은지 예상해서 스코어를 매길 수도 있습니다. 회사가 메시지를 보내야 할 대상을 우선순위에 따라서 줄을 세울 수도 있는 셈입니다. 고객마다 어떤 디지털 채널을 통해서 메시지를 보낼지 선별합니다. 가장 반응이 좋은 디지털 채널을 가려냅니다. 메시지 내용은 어떤 표현을 선호할지도 계산합니다. 더불어서 메시지를 언제 전달하면 좋을지도 추론합니다. 가용할 수 있는 모든 데이터를 활용해서 예측값을 높이면 마케팅 효율성이 좋아지니까요. 데이터 드리븐 디지털 마케팅은 이렇게 이뤄집니다. - 아날로그 감성이 풍성한 오토바이 제조 업체인 할리데이비슨 같은 전통적인 기업도 디지털 채널을 이용하기 위해서 노력 중입니다. 디지털 마케팅 플랫폼 앨버트를 도입해 CRM(고객 관계 관리) 타깃을 대상으로 메시지, 타이틀, 이미지 등을 변경해가면서 가장 반응이 좋은 마케팅 캠 페인을 찾아냈습니다. 그리고 수백만 개의 키워드와 수천 개의 유사 광고를 테스트하면서 고객별로 맞춤형 캠페인을 진행했습니다. 결국, 전체 물량의 40%를 디지털 채널을 통해서 판매하는 결과를 만들어냈습 니다. 한국에서 할리데이비슨의 대상 고객은 구매력이 강한 40대와 50 대입니다. 이들을 공략하기 위해서는 최적의 채널을 선택해야 했습니다. 한국에서 40~50대에게 적합한 채널은 네이버였습니다. 퍼포먼스 마케팅 담당자는 네이버 밴드를 통해서 동호회에 접근한 후 이벤트를 기획하고 최적의 메시지를 만들어서 입소문을 냈습니다. - 프로덕트 오너는 스크럼으로 대변되는 애자일 문화가 종래의 PM과는 다른 업무 수행 방식이 있다는 것을 전파하기 위해 만든 단어입니다. 하지만 여전히 많은 테크 기업에서 PO와 PM을 혼용하고 있습니다. 프로덕트 오너는 우리에게 일반적으로 익숙한 프로젝트 매니저와는 완전히 다른 역량을 보유하고 있습니다. 프로덕트 오너는 프로젝트 매니저(제품 관리자), 제품 기획자와 구분해서 생각해야 합니다. 국내에서 PM 이라고 하면 대개 프로젝트 매니저를 지칭합니다. 제품 기획자는 제품의 기획 문서를 만들고 구현은 제품 관 리자에게 넘깁니다. 제품이 만들어지면 곧바로 종료되는 프로젝트란 거의 없고 이후로는 유지·보수 단계에 들어가게 됩니다. 이때 제품이 기획했던 대로 동작하지 않는다거나 사용자가 기획한 대로 사용하지 않는 경우가 생깁니다. 이처럼 제품의 유지와 보수만으로 해결이 안 되는 문제가 생기면 팀을 다시 꾸려서 문제를 해결해야 합니다. 그러나 다시 프로젝트를 구성해도 원래의 제품 기획자는 이미 다른 프로젝트에 투입된 경우가 많습니다. 고객의 피드백을 받아서 제품을 개선하는 일이 새로운 제품 기획자에게 맡겨지면 제품에 담겨야 할 철학과 고객에게 제공하고자 하는 가치가 바뀝니다. 이런 상황에서는 제품이 일관성을 유지하기가 어렵습니다. 제품 관리자는 본인의 임무를 수행하는 데 필요한 의사 결정을 내리고 세무적인 실행 사항은 사업 책임자에게 넘기는 경우가 많습니다. 의사 결정권자인 만큼 다수의 제품 관련 사항을 조율해야 하기 때문입니다. 제품의 세부사항을 잘 모르는 경우도 많습니다. 그래서 제품 간에 '카니발 이 발생하면 사업 책임자가 이를 전략적으로 조율해야 합니다. 제품 관리자는 본인이 맡은 제품이 잘 성장하도록 제품에 관련된 전략을 세우고 실행하며 점검합니다. 하지만 단독으로 결정할 수 없는 부분이 많으므로 때로는 의사 결정이 정체되기도 합니다. 이런 상황에서 기업의 실행 속도를 더 빠르게 하도록 제품과 관련된 의사 결정권과 책임을 더 강화한 역할을 프로덕트 오너, 즉 제품 소유자라고 부르곤 합니다. 이처럼 프로덕트 오너는 제품에 대한 의사 결정권을 넘겨받은 사람입니다. 더 빠른 의사 결정을 위해서 제품과 관련한 CEO의 권한이 위임돼 있다는 뉘앙스로 미니 CEO라 부르기도 합니다. 그런데도 실제 상황에서는 의사 결정을 못해서 병목 현상이 일어나는 경우도 많습니다. 프로덕트 오너가 프로젝트 매니저와 다른 점은 의사 결정 권한을 위임받았다는 것입니다. 권한 위임이 이뤄지지 않아 권한과 책임이 불균형을 이루고 있다면 무늬만 바뀐 호박이라고 할 수 있겠지만, 제대로 권한을 위임받은 상태라면 제품의 성장은 프로덕트 오너의 역량에 달려 있다고 할 수 있겠습니다. 프로덕트 오너의 중요 역량을 꼽자면 1 고객에 대한 이해, 2 제품에 대한 이해, 3 개발에 대한 이해, 이렇게 크게 세 가지 영역에서의 역량이 필요합니다. - “스마트한 사람을 뽑아서 뭘 하라고 하다니요. 말이 안 됩니다. 우리는 똑똑한 인재를 뽑죠. 우리가 뭘 해야 하는지 알려주게 하려고요 (It doesn't make sense to hire smart people and tell them what to do; we hire smart people so they can tell us what to do).” (스티브잡스)
* CDO Chief Digital Officer 온오프라인(유무선이라고 말하기도 합니다) 디지털 제품과 서비스, 채널 전체를 도맡는 역할은 CDO에게 있는 것으로 여기는 경우가 많습니다. 디 지털 네이티브 기업은 별도의 CDO가 있는 것이 아니라 CEO가 CDO역할을 함께 수행합니다. 반면에 전통 기업은 디지털 제품의 비중이 아 직 작은 경우가 많으므로 CEO 외에 별도로 CDO가 존재하는 것이 무난합니다. 기존 전통 기업은 제품과 서비스에 관한 조직이 사업부로 나뉘어 있거나 이를 통합해서 관장하는 조직장이 있기 마련인데, 해당 조직에 디지털 제품 및 서비스를 함께 맡기는 것은 좋은 선택이 아닙니다. 디지털조직은 AARRR 등 새로운 관점을 가지고 사업을 바라보려고 하지만, 기존 조직은 매출에서 영업 이익 등 전통적인 잣대만을 고수하기 마련이기에 이 시각이 통합되거나 조율되지 못하는 어려운 상황이 자주 생깁니다. 이런 상황은 제품의 성격이 달라서 발생합니다. 무한 복제가 가능하고 원가 구성이 다른 디지털 제품은 제품의 성격상 싸다고 팔리는 것이 아니고 좋은 사용자 경험을 하게 해줘야 팔립니다. 반면에 전통적 아날로그 제품은 대개 가격을 낮추는 할인 행사를 진행하면 더 많이 팔립니다. 또 디지털 직군은 IT 직군이 아니라 사업 조직으로 사업에 이바지하 는 것을 선호하므로 디지털 조직의 입장에서는 고객과의 접점을 가진 것이 매우 중요합니다. CDO가 존재하지 않는 경우에도 디지털 제품과 채널을 맡는 업무는 필요하므로 해당 역할을 사업보다는 기술에 무게를 신는 CTO에게 맡기거나 꼭 CPO라고 부르지는 않더라도 디지털 제품에 대해 같은 역할을 하는 임원에게 맡기는 경우가 많습니다. * CPO Chief Product Officer 제품과 마케팅 채널을 모두 관장하는 업무는 대개 CEO의 업무입니다. 그래서 보통은 CPO라는 역할이 눈에 띄지 않습니다. 전통 기업에서는 기존 제품을 유지하면서 새롭게 디지털 제품을 만들어야 하는데 CEO 는 기존 제품에 익숙하고 디지털 제품에는 익숙하지 않으므로 해당 업 무를 CDO에게 맡기는 경향이 있습니다. CDO가 CIO와 업무를 나누는 경우에는 CPO의 역할이 경계가 모호해져서 CPO라 부르지 않고 별도의 임원에게 맡기는 경우가 있습니다. 역할은 분명하지만, 부르는 이름이 애매해서 조직마다 다른 이름으로 부르곤 합니다. 그러나 반드시존재해야 하는 역할입니다. * CDMO Chief Data Management Officer(7||0|| CC/2THE Chief Data Monetization Officer), 또는 CDO Chief Data Officer 데이터 담당 임원입니다. CDO라고 하면 디지털 임원인 CDO Chief Digital Officer 와 혼동할 수 있으니 CDMO라고 부르기도 합니다. 그렇다.면 CDMO라는 새로운 역할을 수행하는 임원은 누구에게 보고하고 승인받을까요? 이에 따라 CDMO의 역할이 변하기도 하고 조직에서 데이터를 얼마나 잘 활용할 수 있게 되는지 여부도 달려 있습니다. CDMO가 CEO에게 보고하고 권한과 책임을 부여받는다면 가장 강력하게 디지털 트랜스포메이션을 추진할 수 있을 터이지만, 데이터 활용처가 많지 않은 초기부터 이렇게 진행하기는 어렵습니다. CEO에게 보고할 경우 CEO의 데이터 이해의 폭에 따라서 실행 속도가 달라질 것이고, 다른 부서의 견제도 만만치 않을 것입니다. 초기를 지나 확실한 성과를 내기 시작하면서부터 CEO에게 직접 보고하는 형태를 갖추는 것이 좋습니다. 한편으로 CDMO가 CDO, CIO, COO에게 보고하고 권한과 책임 을 부여받는다는 것은 상위 조직의 역할 일부를 나눠 받게 되는 것입니다. 각각 장단점이 있겠지만, 모든 역할을 다 나눠서 수행할 만큼 임원 진을 다양하게 구성하기는 어렵습니다. 디지털 네이티브 기업이 아니라 전통 기업의 경우 가장 효율적인 조직 구성은 CDO-CDMO의 라인업이 되겠지요.
- 매일 수백만 개의 영상이 틱톡에 업로드되지만, 그중 대부분은 일반 적인 조회 수만 받는다. 각 동영상 시청자의 규모는 시스템의 끊임없 이 변화하는 신비로운 알고리즘에 의해 결정되며, 이 시스템을 컨트롤 하는 데 있어 이러한 알고리즘이 어떻게 작동하는지 이해하는 것이 가장 중요하다. 틱톡에 동영상이 업로드되는 순간, 동영상 클립과 설명문은 자동 감 사를 거치기 위해 대기 리스트에 올려진다. 컴퓨터 비전은 클립 내의 요소를 분석하고 식별하는 데 사용되며, 그다음 키워드로 태그가 지 정 및 분류되고 플랫폼의 콘텐츠 지침을 위반한 것으로 의심되는 동영 상은 사람의 검토를 거쳐야 하기에 플래그가 지정된다. 모니터링 요원 은 중복된 콘텐츠가 있는지 대규모 데이터 저장소의 영상을 교차 확인 한다. 이 시스템은 표절을 방지하고, 인기 있는 영상을 다운받아 워터 마크 제거 후 그것들을 새로운 계정으로 다시 올리는 관행을 막기 위해 고안되었으며 이러한 중복으로 식별되는 동영상은 노출도가 크게 저하되기도 한다. 모든 심사 과정을 거친 후, 해당 영상은 수백 명의 활성 사용자들로 구성된 작은 풀에 공개된다. 수직 범주 내에서 영상의 인기도를 측정하기 위해 전체 조회 수, 좋아요 수, 댓글, 평균 재생 길이 및 공유와 같은 측정지표를 분석하며, 인기가 많은 콘텐츠는 다음 단계로 이동하 여 수천 명의 활성 사용자에게 노출된다. 다시 한 번 더 높은 수준의 측정지표를 통해 평가된 후, 그중 제일 높은 평가를 받은 영상만 더 많 은 시청자에게 노출되는 다음 단계로 진행될 것이다. 영상이 상위 계층으로 이동함에 따라 잠재적으로 수백만 명의 사용자에게 노출될 가능성이 있다. - 하지만, 프로세스가 완전히 알고리즘에 의해 실행되는 것만은 아니다. 예를 들어, 100만 뷰에 이르는 영상이 담당자의 리뷰 과정을 통해 갑자기 삭제되는 사례도 존재하는 것처럼, 상위 레벨에서는 콘텐츠 조 정팀 담당자가 일련의 엄격한 지침에 따라 영상을 시청하고 플랫폼의 서비스 약관을 위반하지 않거나 저작권 문제가 없음을 확인하기도 한다. 틱톡과 같이 많은 유저가 활동하는 플랫폼에서는, 시스템의 허점 과 속임수를 찾으려고 애쓰는 나쁜 사람들 또한 늘 존재한다. 그들은 클릭 농장을 이용하여 계정을 면밀히 모니터링하고 새로운 영상의 인기를 판단하는 데 사용하는 측정지표를 인위적으로 과장하여 알고리즘이 유리하게 작용하도록 한다. 비양심적인 마케팅 담당자들은 한 바구니에 계란을 넣고 단 한 개의 계정에 대한 측정 기준을 높이기보다는, 수십 개의 심지어 수백 개의 유사한 계정을 운영함으로써 성공할 확률을 더욱 높이고 있다. 중 복 콘텐츠 모니터링 시스템을 피하기 위해 다양한 필터와 효과를 사용 하거나 긴 영상을 잘라 더 짧은 콘텐츠 섹션으로 편집하며, 플랫폼의 규정이 점점 더 엄격해짐에 따라 이에 대처해 속임수를 쓰기 위한 온갖 방법을 동원하고 있다. 그것은 마치 고양이와 쥐의 끝없는 게임과 같 아 플랫폼이 한 개의 구멍을 간신히 막아 낼 때마다 곧 또 다른 구멍이 발견될 것이다. - 오늘날 바이트댄스는 널리 뻗어 나가는 거대한 기업이다. 다른 IT 대 기업과 마찬가지로 게임, 교육, 기업 생산성, 결제 등으로 구성된 수많은 온라인 서비스로 확장돼 가고 있다. 현재, 2020년 책 집필 당시 토우티아오(今日??ToutiaoToday), 더우인, 틱톡 총 3개의 플랫폼으로 해 당 서비스를 제공하고 있으며, 이 플랫폼들이야말로 바이트댄스가 빠 른 성장을 이루는 데 핵심 동력이라 할 수 있다. 이러한 비즈니스의 부상은 회사가 수억 명의 신규 사용자를 확보할 수 있었던 획기적인 주력 플랫폼에 의해 추진된 총 3단계의 뚜렷한 성 장 단계를 보여 준다. 각 단계에는 자체 개발 및 기존 앱의 기능이 포 함되어 있어 플랫폼 간의 범주를 광범위하게 다양화했으며, 단계마다 이전 단계에서 개발된 제품 및 기술을 기반으로 구축되어 있다. 틱톡의 성공은 중국 자매 앱인 더우인의 기술과 경험, 판촉 극본을 복제하는 데 있었고, 더우인의 성공은 중국 유명 뉴스 집계 앱인 토우티아오 를 통해 개발한 추천 엔진과 운영 전문성, 현금 보유량에 달렸었다. 마지막으로 중요한 것은 토우티아오의 성공이다. 결국, 이 모든 성공은 회사의 설립자인 장이밍(一喝 Zhang Yiming)의 통찰과 결정력으로 거슬 러 올라가야 한다. 2011년, 노련한 사업가 장이밍은 스마트폰이 인간이 정보를 수신하 고 상호작용하는 방법을 크게 변화시키리라는 것을 예견했다. 비록 그 당시에는 아무도 이를 예견할 수 없었지만, 이 생각의 씨앗은 회사의 창립에 심어져 결국 틱톡의 글로벌 성공을 통해 열매를 맺었다. 스티 브 잡스의 말을 인용하자면, “앞을 내다보는 점들은 연결할 수 없지만, 거꾸로 볼 때만 연결할 수 있다”. - “우선 엔터테인먼트를 통해 시장을 개척하기로 결정했습니다.” 앞서 99Fang.com에서 이밍과 함께 일했던 바이트댄스의 초기 모바일 앱 개 발자인 황허(黃河 Huang He)는 “오락은 진정한 수요”라 말했다. 바이트댄스가 공식적인 사업체로 등록하기도 전에, 초기 팀은 “구피 픽쳐 4라는 이름의 첫 번째 앱을 출시했고, 이 앱은 밈과 웃긴 중독성 있는 사진을 끊임없이 만들어 제공했다. “네이한 딴즈"45 라는 두 번째 앱 또한 인터넷 밈에 초점을 맞추어 앞 의 앱과 비슷한 위치에서 빠르게 흐름을 이어 갔다. 네이한 딴즈는 즉 각적인 히트를 쳤고, 몇 달 만에 수백만 명의 사용자를 사로잡았다. 유 사한 두 앱 간의 성공의 차이는 더 나은 이름과 데이터 절약 최적화에 있었다. 전반적으로, 이 신생 기업은 2012년 상반기에 수십 개 이상의 테스트용 앱을 출시하며 다양한 주제와 방향을 실험했다. - 최적화된 이름을 구상하기 위해, 연구팀은 중국의 트위터인 웨이보 (微博 Weibo)의 상위권 계정들을 조사했고, 가장 많이 사용되는 제목은 직설적인 언어로 표현한 중국어 이름이라는 것을 발견했다. 이에 따 라, 초기 테스트용 앱들 또한 “아름다운 사진”, “오늘 저녁 꼭 봐야 할 영상”, “진정한 미녀 - 매일 100명의 아름다운 소녀들”과 같이 특이하 지 않고 오히려 평범하고 간단한 설명 제목으로 앱의 용도를 즉시 이해 할 수 있는 이름을 사용하였다. 앞서 99Fang.com에서 5개의 부동산 앱을 만들어 다양한 포지셔닝을 테스트했던 이밍 사단은 이러한 전략 및 결과를 바이트댄스에서 더 다양한 테스트를 통해 발전시켰다. 새로운 아이디어는 신속하게 앱으로 출시하여 여러 기능을 테스트한 후 시장에서 어떤 것이 더 가치 있는지 를 확인하는 것은 바이트댄스만의 전략이 되었다. - 바이트댄스는 중국 인터넷 산업의 빅3라 불리는 바이두, 알리바바, 텐센트(통칭 BAT라 불린다)의 영향을 받는 운명을 피할 수 있었다. 사실, 중국 인터넷 업계에서는 일정 규모에 도달하게 되면 BAT의 투자를 받거나 거대 기업에 편승한 경쟁사에 의해 무너질 위험을 감수해야 한다는 의견이 대부분이었다. 특히 알리바바와 텐센트는 방대한 양의 트래 픽과 사용자 데이터를 가지고 있으며 강력하고 광범위한 인터넷 서비 스 생태계를 구축하고 있다. 이러한 이유로 대부분의 스타트업들은 빅 3 회사의 포트폴리오를 이용해 기업 투자자의 대리인이 되는 길을 택 한다. 바이트댄스는 중국 인터넷 기업 중 빅3을 제외한 유일하게 덩치 가 큰 회사이다. 텐센트가 바이트댄스에 투자한다는 소문이 돌자 한 직원은 “텐센트 직원이 되기 위해 바이트댄스에 가입한 게 아니다.”고 이밍에게 투덜거렸고 “나도 아니다.”는 이밍의 퉁명스러운 대답을 들 을 수 있었다. 63 바이트댄스가 투자를 받아들인 대기업 중 하나는 투자 시리즈 C라운드에 합류한 웨이보였다. 웨이보는 앞서 말한 이밍의 전 직장인 판푸 를 꺾고 “중국판 트위터” 왕관을 차지했고, 이는 곧 그들이 바이트댄스 에 방대한 양의 데이터를 제공할 수 있다는 것을 의미했다. 웨이보는 다양한 앱이 상호 작용할 수 있는 중개자 역할을 하는 API64를 열어 토 우티아오가 웨이보 사용자의 데이터와 댓글과 같은 활동에 접근할 수 있도록 했다. 만약 사용자가 시나 웨이보 계정으로 토우티아오에 로그인했다면, 바이트댄스는 몇 초 안에 그들의 웨이보 관심사와 에세이 선호도를 분 석하고 그 결과를 사용하여 개인화 추천을 진행할 것이다. 바이트댄스 가 경쟁자라는 사실을 뒤늦게 깨달은 웨이보는 결국 경쟁사의 데이터 접근을 차단하고 바이트댄스 주식을 매각해 버렸다. - 이 글을 읽고 있는 여러분들은 어떻게 중국 인터넷 대기업 중 하나인 웨이보가 바이트댄스가 그들의 경쟁자였다는 사실을 깨닫지 못했을 수 있는지 물어볼지도 모른다. 대답은 벤처 캐피털에서 가장 뛰어난 인재 들 중 누구도 바이트댄스를 진지하게 받아들이지 않았다는 것과 같은 이유이다. 토우티아오는 뉴스 제공 웹사이트로 정의되었다. 이러한 이유로, 대 부분의 IT기업 및 투자자들이 우려하는 “레드오션”으로 분류되는 “모 바일 뉴스 앱” 범주 내에서만 경쟁하는 것으로 좁게 인식되었다. | “파트너들과 논의하며 느낀 점은, 이 분야는 경쟁이 너무 치열하다 는 것이었습니다. 바이트댄스와 같은 스타트업에게 주어지는 기회는 거의 없다고 봐야 합니다.”라고 세쿼이아의 닐이65 설명했다. 이미 알 아주는 대기업과 손을 잡아 충성도 높은 사용자들을 지휘하거나 BAT 중 하나에게 지원을 받는 부당한 이득을 누리는 등, 기술이 아닌 다른 비즈니스 요인이 승자의 관건이 되어 버렸다. 그러나 문제를 제기하는 것은 중국 투자자들만이 아니었다. 이미 기술의 한계에 대해 세계적으 로 광범위한 회의론이 퍼지고 있었다. “뉴스 집계는 사실상 매우 어려운 일입니다, 성공한 기업 조차도 어 떤 뉴스/콘텐츠가 사용자를 이끌지 판단하는 데 있어 인간의 두뇌만큼 훌륭한 알고리즘은 없다는 사실과 씨름해야 합니다.86 미국의 유명 기 술 블로그 테크크런치(TechCrunch)에서 미국 스타트업 프리즘(Prismatic)의 가능성에 대해 매우 부정적인 기사를 쓴 것이 여론의 시작이었다. 당 시 프리즘(Prismatic)은 토우티아오와 비슷한 위치였고, 지금 돌이켜 보면 이러한 관점은 매우 구시대적으로 보인다. - 2011년, 구글이 유튜브에 "Sibyl75이라는 새로운 머신 러닝 시스템을 구현하면서 돌파구가 마련되었고 그 효과는 대단했다. 유튜브 엔지니어들은 새로운 시스템 도입으로 인해 사이트 조회수가 마치 로켓 우주 선 부스터를 단 듯 폭풍 증가했음을 발견했다. 곧 더 많은 사람들이 검 색이나 입소문을 통해 영상을 시청하기보다 “추천 동영상 목록에서 시청할 동영상을 고르고 있었다. 구글은 추천 시스템을 계속 업데이트하며 시스템을 최적화한 후, 스 탠포드대학(Stanford University) 교수 앤드류(Andrew Ng)가 이끄는 유명 문샷 연구소 그룹, 구글 X가 개발한 구글 브레인(Google Brain)으로 전환했 다. 그리고 구글 브레인의 딥 러닝은 획기적이고도 새롭게 발전해 나갔다. “Sibyl”의 영향은 이미 인상적이었지만, 구글 브레인 결과는 놀 라웠다. 2014년부터 2017년까지 3년 동안 유튜브 홈페이지에서 동영상 시청에 소요된 총 시간은 20배나 증가했으며, 이 중 유튜브의 “추천 시 스템”을 통해 소요한 시간이 70%76 이상을 차지했다. 소셜 미디어 전 반에 걸쳐 유튜브의 추천 비디오가 나의 흥미를 끌 만한 영상을 추측하 는 데 있어 섬뜩할 만큼 정확하다는 인식 또한 증가했다. “딥 러닝”으로 알려진 획기적인 돌파구를 포함하여 AI 분야의 급속한 발전은 이러한 콘텐츠 유통 방법이 급속히 발전할 것임을 의미했고, 바이트댄스와 같은 회사 입장에서는 이러한 새 시대의 발전이 보다 더 좋을 수 없었을 것이다. 그들은 알고리즘 추천의 효율성과 정확도가 도약과 경계 사이에서 앞으로 발전해 나갈 새로운 시대의 초입에 서 있었다. 유튜브가 가장 먼저 혜택을 받은 것처럼 보이지만 사실 이러한 발전은 아마존의 제품 추천에서부터 틱톡 동영상에 이르기까지 모든 종류의 온라인을 발전시킬 것이다. - 중국의 많은 업계 베테랑들은 개인화된 추천이 모바일 경험을 향상시킬 수 있는 큰 잠재력을 가지고 있음을 인식했다. 그러나 이밍은 기회를 감지했을 뿐만 아니라 단호하게 행동했기 때문에 그 누구보다 앞설 수 있었다. 결국 바이트댄스의 성공을 이끈 가장 중요한 요인은 그 결정의 타이밍에 올인" 하기로 약속한 이밍의 초기 비전의 명확성이었다. 이에 따라 바이트댄스는 스마트폰의 부상과 AI의 부상이라는 한 시대가 아니라 두 시대를 규정하는 트렌드 섹터로 자리매김할 수 있었다. - 추천은 가장 최근에 완성된 서비스이다. 추천이 완전히 수용된다면 채널을 적극적으로 구독하거나 친구 추가 혹은 '좋아요' 버튼 없이도 놀라운 접근성을 보여 줄 것이다. 좋은 추천은 높은 기술 요건을 동반하는데, 검색창에 입력하는 내용에 따라 명확한 옵션을 제공하는 검색 엔진과 달리 권고에는 명확한 의사 표시가 없다. 오직 사용자의 이전 행동에 따라 사용자의 선호도를 추론해야 하기 때문이다. 온라인 콘텐츠 추천의 초기 개척자는 2001년에 설립된 스템블어펀 (StrumbleUpon)83 으로, 추천을 기반으로 하는 브라우저 툴바 확장 프로그 램이다. 넷플릭스도 2009년 추천 시스템의 정확도를 10% 높인 알고리 즘으로 100만 달러의 상금을 수여하기도 했다. 온라인 추천의 중요성은 “이 제품을 구입한 고객의 다른 제품 목록...”84과 같은 메시지를 통 해 전자 상거래에서도 분명해지기 시작했다. 전반적으로 추천 시스템은 “콘텐츠 기반 필터링”과 “보편적 필터링” 이라는 두 가지 주요 프로세스에 의존한다. 이 두 개념은 비교적 이해 하기도 쉬운 프로세스에 속한다. “콘텐츠 기반 필터링 시스템은 사용 자가 이미 소비하고 싶어 하는 콘텐츠와 유사한 콘텐츠를 사용자에게 추천하는 것인데, 예를 들어 강아지가 나오는 영상을 보는 것을 즐기 고 “강아지 애호가” 라는 태그가 달려 있는 사용자에게 시스템은 더 다양한 강아지 영상을 추천할 것이다. 이에 반해, “보편적 필터링”은 유사한 콘텐츠를 즐기는 사용자 그룹 을 찾는 데 중점을 둔다. 자, 지금 제인과 트레시의 이해관계가 매우 밀접하게 관련되어 있다고 가정해 보자. 만약 제인이 관심 비디오를 끝까지 여러 번 시청한다면, 시스템은 트레시에게도 그 비디오를 추천할 것이다. - 바이트댄스를 시작하기 전부터 이미 이밍은 다양한 콘텐츠 유통 방법에 대해 깊은 실무 경험을 쌓았다. 여행 검색 엔진 쿠쉰(2006~2008)과 트위터와 유사한 소셜 플랫폼 판푸(2008~2009) 그리고 검색엔진과 추천 기능을 모두 응용한 부동산 포털 99Fang까지, 그는 한 인터뷰에서 자신이 가진 깊이 있고 폭넓은 전문지식을 인정했다. “정보의 효율적인 흐름은 제가 사업에서 가장 중요하게 생각하는 주제입니다. 전 정보 전달은 인간 사회의 이익, 협력, 인식에 큰 영 향을 미친다고 생각하며, 특히 다양한 정보에 관심이 많습니다. 검색 엔진의 키워드든, 사람을 통해 전달되는 소셜 네트워크 사이트는, 관심사를 세분화하여 사용하는 추천 엔진이든 그 모두 정보 기반 말입니다.” - 바이트댄스가 설립 직후 사용한 인터넷 정보 배포 프레임 워크 “추천” 기능은 사실 다른 글로벌 기업인 페이스북이 이미 사용하고 있었던 방법이었다. 2013년, 마크 저커버그는 페이스북 뉴스 피드에 중대한 변화를 예고 하며 “세계 모든 사람들에게 세계 최고의 개인 맞춤형 신문을 선물하고 싶다.”89 라고 말한 바 있다. 미국의 IT 대기업은 머신러닝을 사용하는 것이 경쟁력을 유지하는 핵심이라고 생각했다. 페이스북 뉴스 피드는 이미 친구와 가족, 뉴스 미디어, 광고, 브랜드 등의 콘텐츠를 최적화하여 추천하는 정교한 기술을 적용하고 있었으며 인스타그램은 2014년도부터 인기 탭인 “탐색” 탭을 각 사용자에 맞게 정확하게 맞춤화된 콘텐츠를 표시하도록 조정했다. 유튜브 또한 2011 년부터 참여율을 높이기 위한 가장 효과적인 전략으로 추천 동영상을 최적화하는 데 집중하기 시작했다. - 2018년 1월 바이트댄스는 베이징에서 공개회의를 열어 그들의 알고리즘 작동 방식을 공개했다. 95 이번 회의의 목표는 음란물 유포에 대한 국영 언론과 인터넷 감시자들의 구체적인 비판을 잠재우는 데 있었다. 행사에는 회사의 수석 알고리즘 설계자 카오(Cao Huanhuan)가 나와 바이트댄스의 추천 시스템 원칙을 자세히 다루었다. 그의 발표 내용은 아래와 같다. 바이트댄스의 시스템은 콘텐츠 프로필, 사용자 프로필과 환경 프로필, 이 세 가지 프로필을 중심으로 한다. 카오는 리버풀과 맨체스터 유 나이티드의 잉글랜드 프리미어리그 축구 경기에 관한 뉴스 기사를 예로 들어 콘텐츠 프로필을 설명했다. 기사는 자연어 처리를 이용해 키 워드를 추출하며 '리버풀 풋볼 클럽', '맨체스터 유나이티드 풋볼 클럽', 영국 프리미어 리그' 및 게임의 주요 선수 다비드 데 헤아(David de Gea)' 같은 이름도 추출하게 된다. 그런 다음 키워드의 관련성을 계산하게 되는데 “맨체스터 유나이티 드 풋볼 클럽”은 0.9835, “다비드 데 헤아”는 0.9973으로 예상대로 매 우 높았다. 또한 콘텐츠 프로필에는 기사가 게시된 시기도 포함되어 있어, 시스템에서 기사가 작성된 시간을 계산하고 오래된 기사는 추천 을 중지할 수도 있다. 사용자 프로필은 사용자의 인터넷 사용 기록, 검색 기록, 사용 중인 기계 유형, 기계 위치, 연령, 성별 및 행동 특성을 포함한 다양한 소 스로부터 구축된다. 사용자는 소셜 데이터와 사용자 행동 특성에 따라 수만 개의 위도로 나뉘어 서로 다른 프로필을 구축했다. - 플랫폼에서 추천하는 게시물을 읽을 때, 사실 그 플랫폼은 우리가 무 엇을 읽기로 선택하는지, 무엇을 무시할지, 어떤 내용에 얼마나 시간을 투자하는지, 어떤 기사에 댓글을 달지, 어떤 이야기를 공유할지 등 사용자 행동을 추적함으로써 사용자들의 선호도를 학습한다. 마지막으로, 환경 프로필은 다양한 상황에 따라 사람들의 선호도가 다 르기에 사용자의 직장, 가정 또는 출퇴근 중의 지하철 등 위치를 기반으 로 한다. 다른 특성으로는 날씨와 심지어 사용자의 네트워크 연결 안정 성, 사용자의 네트워크 환경(예: Wi-Fi 또는 China Mobile 4G)이 있다. 시스템은 읽은 기사 비율과 그 소요 시간의 백분율을 최적화하는 콘텐츠 프로필, 사용자 프로필 및 환경 프로필 간의 가장 정확한 통계를 계산한다. 콘텐츠 유통 작업 과정에는 품질과 잠재적인 독자층을 바탕으로 새로 게시된 각 스토리에 “추천 가치값”할당 및 계산하는 작업이 포함된다. 값이 높을수록 해당 기사는 더 적합한 사람들에게 전달될 것이며, 사용자가 스토리와 상호작용하며 스토리의 추천값이 변경된다. 좋아요, 댓글, 공유와 같은 긍정적인 상호작용은 추천 가치를 증가시키고, 싫어요. 짧은 가독시간과 같은 부정적인 행동은 그 가치를 낮추는 데, 콘텐츠의 작성 시간에 따라 값도 변경된다. 스포츠나 주가와 같은 빠른 뉴스 주기 카테고리의 경우 하루나 이틀 정도면 가치가 크게 하락하는 방면, 라이프스타일이나 요리와 같은 꾸준한 범주의 경우, 그 과정은 더 느릴 수 있다. - 토우티아오 설립 초기 당시, 바이트댄스는 사전 설치를 통해 수천만 명의 사용자를 확보할 수 있었다. 이로 인해 회사의 핵심 사용자들은 저가의 안드로이드 기기를 사용하는 사람들이었고, 그중 상당수는 이미 토우티아오가 사전에 설치된 스마트폰을 구입했다. 그리고 시간이 지나면서, 이 핵심 그룹의 콘텐츠 선호도는 회사를 향한 대중의 인식 에 큰 영향을 주기 시작했다. 사실, 해당 앱은 사람들에게 무의미하고 교양 없는 쓰레기를 제공한다는 평판을 얻었다. “저흰 사람들의 요구 중 96%는 저속한 것이라는 사실을 직시해야 합니다.” 수석 UI 디자이너이자 바이트댄스의 22번째 직원이었던 가오(高寒 Gao Han)의 설명이다. 하지만 그는 앱의 평판이 예상외로 좋다는 것을 확인하며 이렇게 말했다. “토우티아오는 당연히 쓰레기일 수 있죠. 클릭 한 번이면 모든 종류 의 지저분한 뉴스들이 쏟아져 나오니까요. 맞아요, 인정하겠습니다.” 모든 사람들은 정크 푸드가 몸에 나쁘다는 것을 알지만, 사람들은 여 전히 정크 푸드를 즐겨 먹는 것처럼 바이트댄스는 저속한 내용을 적극 적으로 밀고 나가는 것을 강력히 부인했지만, 105 사람들이 원하는 것을 제공해 주는 사업은 부정할 수 없었다. 마침 그들은 중국 대중들이 매 일 기름진 빅치즈버거와 같은 자극적인 제목의 뉴스, 유명인사의 스캔 들, 예쁜 여성들의 사진 등을 원한다는 것을 알았다. “중국 전체가 사 회 엘리트들로 구성되어 있다고 생각하십니까? 대학 교육률은 4%에 불과합니다.”라고 가오는 덧붙였다. - “초기에 성장을 추구할 때는 브러시가 되는 것이 좋습니다. 구체적인 요구를 뛰어나게 해결할 수 있는 브러시 말이죠. 하지만 나중에는 캔 버스가 되는 것이 좋습니다. 그 어떤 일도 일어날 수 있는, 빈 캔버스 말이죠.” 이것이 알렉스가 뮤지컬리의 발전을 어떻게 구상했는지를 설명할 때 든 비유였다. 뮤지컬리는 립싱크를 통해 인기를 얻었고 초기 프로덕트-마킷 핏(PMF)을 찾을 수 있었다. 이 플랫폼은 모바일 콘텐츠 창작 의 장벽을 낮춰 잠재적으로 모든 사람들이 연예인이 될 수 있도록 했다. 초기 가치 명제는 간단했다. 이 앱은 사람들이 Lip-Sync Battle을 보고 자신만의 짧은 립싱크 동영상을 만들 수 있도록 도와주는 도구였다. 대부분의 사람들은 새로 만든 영상을 인스타그램과 같은 다른 플랫폼에 게시하기를 원했다. 이러한 초기 사용자 보존 전략은 뮤지컬리가 창시한 것은 아니었다. 유튜브는 사람들이 웹 페이지에 무료로 동영상을 넣을 수 있는, 당시 로서는 혁신적인 개념인 동영상 호스팅 도구로 시작했다. 인스타그램 은 초기에 “킬러 기능인 필터를 통해 사람들이 손쉽게 사진을 전문적 으로 보이게 수정할 수 있는 도구를 제공하며 인기를 끌었다. 뮤지컬 리는 유틸리티 도구에서 출발했기 때문에 첫걸음을 성공적으로 내딛을 수 있었고, 이 초기의 인기를 사용해 더 크고 다양한 기능을 가진 앱으로 성장할 기회를 얻을 수 있었다. - 자신들의 도구를 사용해 콘텐츠와 크리에이터들의 수가 임계점을 넘긴다면, 수동적인 엔터테인먼트에 대한 사람들의 욕구를 충족하며 콘텐츠 플랫폼으로 성장할 수 있다. 일종의 모바일용 TV처럼 말이다. 또한 사용자들의 수가 임계점을 넘긴다면, 사용자들 간의 교류를 촉진하여 소셜 플랫폼으로 진화할 수도 있는데, 이를 위해서는 사람들의 인연과 지위에 대한 욕구를 해소해 줄 필요가 있다. 콘텐츠는 사람들 사이의 상호작용의 시작점이자 지위 상승의 시작점이기도 하기 때문에 이 두 가지 욕구는 상호 보완적이다. 반대로, 앱을 통해 만들어진 인간관계는 사용자들을 다시 불러들여 더 많은 콘텐츠를 소비하게끔 한다. 하지만 많은 플랫폼들에서는 이 두 가지 목표를 균등하게 잘 달성하는 것이 어렵다. 예를 들자면, 유 튜브는 지식과 엔터테인먼트의 보고의 역할은 뛰어나게 수행했지만 사 용자들 간에 관계를 형성시키는 기능은 약했다. - 운영팀은 카메라 효과, 실시간 스트리밍 도구, “BFF" (Best Fan Forever)Q&A옵션 등 사용자들과 인플루언서들을 연결해 주는 소셜 기능들을 만들기 위해 많은 노력을 들였고, 이들은 모두 큰 인기를 끌었다. 청소년들은 공유하고, 챌린지에 참여하고, 서로와 상호작용하는 것을 좋아했다. 이로 인해 플랫폼의 창립자들은 플랫폼의 향후 방향이 당시 중국의 대표적인 짧은 동영상 앱인 콰이쇼우와 같은 동영상 기반의 소셜 네트워크라고 믿게 되었다. 하지만 나중에서야 뮤지컬리는 자신들의 제품을 잘못 이해했다는 것을 깨달을 수 있었다. 성장의 비법은 더 많은 기능이나 카메라 효과를 추가하는 것이 아니었다. 가장 변화가 필요했던 것은 바로 백엔드 아 키텍쳐였다. 뮤지컬리 상해 부서의 제품 전략에서 일하는 미국인인 제임스 베랄디(James Veraldi)는 “우리는 사용자 인터뷰와 심층적인 데이터 분석을 통해 뮤지컬리는 소셜 네트워크가 아니라 콘텐츠 플랫폼이라는 것을 발견했다.”고 밝혔다. 뮤지컬리는 수년 동안 스스로를 차세대 인 스타그램이라고 생각했지만, 사실은 차세대 유튜브에 더 가까웠던 것이다. 뮤지컬리는 이미 활발한 얼리어댑터인 청소년층을 넘어 최대 잠재력 까지 성장하기 위해서는 수동적인 엔터테인먼트의 가치에 더욱 기댈 필요가 있었다. 뮤지컬리가 추가적으로 확장하기 위해서는 세 가지 과 제를 넘어야 했다. 바로 포지셔닝, 콘텐츠 다양화, 그리고 기술이다. - 더우인의 성공은 알고리즘의 추천 엔진에 크게 의존했으며 이로 인해 사회적 관계의 필요성이 없어졌다. 그 반대로, 웨이시의 소셜 그래프가 이러한 사항을 개선할 수 있는 가능성을 가지고 있었지만, 한편으로는 가족, 지인, 또는 동료들을 계정에 추가하는 것은 사용자의 자유를 억제할 수 있었기 때문에 부정적인 측면도 함께 가져왔다. 사용자들은 누구를 팔로우하고 무엇을 업로드하는 데 있어 편안함을 느끼 고 싶어 한다. 따라서 어느 정도의 익명성을 보장하고 일상적으로 연락하는 사람들과의 분리가 필요한 상황에서 콘텐츠는 충분히 유기적이고 친화적이어야 한다. 이는 사용자의 소속감과 참여감을 동시에 느끼게 한다. - 이밍은 바이트댄스를 한 단계 발전시키기 위해 간단한 전략을 사용했는데, 그것은 최고의 인재를 고용하여 조직에 전문적인 지식을 주입하는 것이었다. 이밍은 회사 초기 추천 엔진을 개선하기 위해 바이두에서 최고 수준의 전문가들을 끊임없이 고용했고, 이후 본격적으로 수익을 창출하기 위해 전통 미디어 광고의 떠오르는 스타 중 한 명인 장이동을 스카우트했다. 플립그램은 인도의 뉴스 정보 웹사이트인 데 일리헌트(Dailyhunt) 및 인도네시아의 베이브(BABE) 등의 다른 초기 회사 들과 마찬가지로 이밍이 중요한 현지 비즈니스 노하우 및 전문 지식을 이용할 수 있도록 지원했다. 이처럼 바이트댄스는 경험이 풍부한 로컬 창업자들의 조언을 받으며 현지 시장 상황을 빠르게 이해할 수 있었다. - 중국의 로컬 인터넷은 현지 입맛에 맞춘 고유의 특성225이 너무 많아 | 인기 있는 중국 앱조차 별도의 “국제 버전”을 만드는 것이 일반적이다. 더우인도 다르지 않았다. 무엇을 바꿀지 결정할 때, 첫 번째 나온 의견 중 하나는 이름을 바꾸되 독특한 비주얼 아이덴티티와 로고를 유지하 는 것이었다. “틱톡의 똑딱거리는 시계 소리는 영상 플랫폼의 짧은 특성을 암시합니다. 새로운 글로벌 버전 이름의 공식적인 설명이었다. 틱톡은 각국의 주 요 언어로도 발음하기 쉬우며 오디오의 중요성을 암시하고 숏폼비디오 의 특징을 나타내 사용자들의 관심을 끌었다. 뮤지컬리와는 달리, 텍 톡이란 이름은 음악, 립싱크, 춤과는 직접적인 관련이 없었다. 초기 몇 달 동안 틱톡은 tiktok.com 도메인을 구매하기 전에 '어썸. 미를 태그 라인으로 사용하고 에이미의 웹 사이트 amemv.com을 사용했다. 나중에는 매 순간순간을 의미 있게'라는 슬로건도 추가되었다. 이는 서양 시장의 콘텐츠 제작자들을 향한 메시지로, 다시 한 번 숏폼 플랫폼만의 짧은 특성을 강화한 것이었다. 중국의 인터넷 회사들은 글로벌 진출을 고려할 때 가장 먼저 그들의 뒷마당이라 할 수 있는, 전 세계의 인구 절반 이상이 사는 아시아를 타기팅한다. 그 이유로는, 다른 아시아 국가들도 중국처럼 1990년대와 2000년대의 웹 1.0 및 2.0의 데스크톱 인터넷 시대를 건너뛰고 모바일 을 바로 사용하게 된 사용자들이 대부분이라는 유사성을 공유하고 있 기 때문이다. 대체로 아시아 국가들은 소셜 미디어 활용이 활발하고 온라인 엔터테인먼트에 대한 수요가 강했기 때문에 이는 틱톡의 확장을 위한 좋은 징조였다. - 2012년 이밍은 모바일 뉴스 피드를 통해 콘텐츠를 통합할 수 있는 기회를 얻었고 개인 맞춤 설정 기능을 사용했다. 바이트댄스는 한 아파트에서 단 30명의 직원으로 시작한 회사였다. 당시 중국에서 두 번째로 가치 있던 인터넷 회사, 거대 검색업체인 바이두가 바이트댄스의 꿈을 이루기에 훨씬 적합했고 그들은 높은 기술 요건을 갖춘 서비스를 제공했지만 바이두의 리더십은 기회의 중요성을 인식하지 못했다. 마찬가지로 2017년에 텐센트는 바이트댄스와 숏폼비디오로 직접 경 쟁하는 것을 포기했다. 그들은텐센트의 자체 숏폼비디오 서비스 웨이 시를 종료하고 당시 시장 선두였던 콰이쇼우의 소수 지분을 인수하는 것을 선택했다. 더우인의 사용이 폭발적으로 증가하자 텐센트는 경쟁분야에 재진입하기 위해 허둥댔지만, 결국 더우인을 따라잡기엔 너무 늦었음을 깨달았다. 페이스북은 이 패턴을 그대로 따라가고 있었다. 그들의 실수는 텐센 트가 거쳤던 것과 일치했다. 페이스북은 일찍이 뮤지컬리의 가능성을 확인하였고 어느 시점에서는 앱의 인수를 진지하게 고려했었다. 하지 만 아이러니하기도 틱톡을 심각하게 과소평가했다. 순식간에 중국 산업 전체를 깜짝 놀라게 한 더우인의 부상에 텐센트 는 용서받을 수 있었지만, 페이스북에게는 그런 변명이 통하지 않았 다. 페이스북은 이미 중국에서 무슨 일이 일어났는지 정확히 알고 있 었기 때문이다. 바이트댄스는 비정상적으로 큰 비용을 페이스북 광고에 지출함으로써 국제 버전의 사용자를 확보하고, 서양 시장에서의 뮤지컬리의 성공을 훨씬 능가할 수 있었다. 페이스북의 자만심이는 '캠브릿지 애널리티카(Cambridge Analytica, 페이스북의 개인 데이터 수백만 건을 유출한 영국 정치 컨설팅 회사)'의 스캔들 여파든, 그들은 바이트댄스의 움 직임에 반응할 기회가 있었지만 여전히 그 기회를 놓치고 있었다. 페이스북의 틱톡 복제 시도는 텐센트가 중국에서 더우인을 모방하 려는 노력에 비해 소심했다. 텐센트는 재빨리 수억 달러 규모의 보조 금을 수백 명의 영상 크리에이터들에게 지원하며 팀을 동원했고, 기존 가족 제품군 전체에 걸쳐 대규모 프로모션을 진행했다. 그에 비해 페이스북은 보수적으로 몇몇 선택된 개발도상국들만을 상대로 테스트했고 크게 움직이는 것을 자제했다. 중국에서 텐센트는 더우인이 그들의 몇몇 핵심 사업 라인에 끼지는 심각한 위협을 깨닫고 즉각 텐센트 서비스에서의 모든 바이트댄스 광고를 중단하는 조치를 취했다. 대조적으로 페이스북과 구글은 틱톡이 이제 그들의 라이벌임에도 불구하고 중국 회사가 광고하는 것을 계속 허용했다. 그것은 플랫폼 전반에 걸쳐 큰 비용을 들여 사용자를 틱톡으로 데려올 수 있는 역할을 했다. - 틱톡이 낮은 장벽과 전통적인 소셜 플랫폼을 따르지 않은 탓에 많은 사람들은 틱톡의 진정한 “해자”가 무엇인지를 궁금해했다. 도대체 무엇 때문에 부유한 경쟁 자들이 틱톡의 시장 점유율을 침식하는 것을 막고 있었을까? 알고 보니 틱톡과 경쟁하는 미국 기업들은 더우인과 경쟁하던 중국기업이 부딪혔던 장벽에 똑같이 부딪히고 있었다. 기본적인 틱톡 복제품을 구축하여 시장점유율을 얻기는 쉬웠다. 하지만 더 나아가, 좋은 버전의 틱톡을 만들기란 매우 어려웠다. - 가장 큰 인터넷 회사들만이 틱톡이 가지고 있는 자동 영상 분류 시스템과 콘텐츠 추천 시스템을 구현할 수 있는 자원을 가지고 있었다. 이 기술은 롱테일 개념의 콘텐츠를 사용자와 매칭하게 해 기존 콘텐츠의 장점을 더욱 증폭시켰고, 사용자들이 틱톡에서 더 많은 시간을 보 낼수록 회사의 사용자 프로필 관심 그래프는 더 상세해졌다. 간단히 말해, 틱톡을 더 많이 사용할수록 더 개인화되었으며 결국 다른 경쟁 자들이 따라잡을 수 없이 데이터는 풍부해져만 갔고, 경쟁자들은 뒤처졌다. 경쟁사들이 틱톡과 경쟁하기 위해서는 영상의 분류와 태경을 자동화하기 위한 정교한 컴퓨터 비전을 사용해야 했다. 틱톡이 참신하고 창 의적인 증강현실 영상 필터도 지속해서 출시하고 있었기 때문이다. 틱톡이란 브랜드는 이미 음악 위주의 숏폼비디오와 동의어가 돼 있 었다. 이 브랜드의 이미지는 틱톡의 이름만큼이나 강력했다. 틱톡이 란 브랜드가 일반 대중들 사이에서 중요한 지위에 도달하자, 그 이름은 공용어로 쓰이기 시작했다. “우리 틱톡 하자!”라고 말하는 데는 부 연 설명이 필요 없었다. 틱톡의 사용자 수가 증가할수록 틱톡은 더 많은 화제를 불러일으켰다. 사람들은 항상 달라지려고 노력하지만, 대부분의 사람은 대중을 따르게 마련이다.
- 데이비드 래퍼 IBM 아태 중국 사회공헌 총괄은 다음과 같이 말했다. "인공지능과 빅데이터가 모든 것을 지배하는 세상에서 블루칼라와 화이트 칼라의 역할은 갈수록 미미해지고 있다. 뉴칼라 New Collar는 새로운 것을 창조하고 연구·개발하는 능력이 뛰어난 계급인데 이들이 미래 세상을 이끌어 갈 것이다.” “학위가 있는지 없는지는 전혀 중요한 문제가 아니다. 얼마 나 과학, 기술, 엔지니어링, 수학 분야를 친숙하게 느끼며 일하는지, 그리고 세상의 변화에 얼마만큼 적응하는지가 더 중요하다.” - BPR을 가능하게 하는 핵심 정보 기술로써 워크플로우 관리 시스템WFMS, Workflow Management System이나 이 시스템의 확장된 개념인 비즈니스 프로세스관리 시스템BPM, Business Process Management의 도입이 이루어지고 있다. BPM은 기존 워크플로우 관리 시스템이 진화한 것으로 생각할 수 있 는데, 워크플로우 관리 시스템은 프로세스 자동화에 중점을 둔 데 비해 BPM은 글로벌화되는 최근의 경영 환경을 반영하는 어플리케이션 통합이 나 협업 및 프로세스 조정 등에 중점을 두고 있다. 즉, BPM은 기업 경쟁 력 향상을 위해 프로세스의 효율적 실행이 중요시되면서 프로세스의 전 주 기를 관리하는 방향으로 그 범위를 확장하고 있는데, 워크플로우 관리 시 스템에서 상대적으로 소홀히 취급되었던 프로세스 분석이나 진단 기능들 을 추가적으로 지원하는 것이다. BPM이란 사람, 조직, 응용 시스템, 문서 와 기타 정보를 포함하는 운영 프로세스를 설계하고 실행하며, 제어하고 분석하기 위해 필요한 각종 방법이나 기법 및 소프트웨어를 사용하여 기업 프로세스를 지원하는 것이라 할 수 있다. BPM을 위한 정보 시스템인 BPMS는 진단 (재)설계 (재)구축운영의 전체 비즈니스 프로세스 사이클에서 프로세스 운영을 실행, 관리 및 조율 하기 위해 명백한 프로세스 설계에 의해 작동하는 일반적인 소프트웨어 시 스템을 말한다. BPM(S) 개념의 변천과 발전 방향을 관리 시스템과 정보 시스템의 관점 에서 각각 살펴보면, 관리 시스템 관점에서의 BPM(S)는 1910년대 테일러 의 과학적 관리에서 1990년대의 ERP를 거쳐 2000년대에는 BPM(S)로 변화하고 있다. 최근의 BPMS는 워크플로우에 기반한 유연성을 그 특징으로 하고 있으며, 이를 BPM의 제3의 파도라고 부르고 있다. 1세대 BPM(S)는 수작업에 의한 비즈니스 프로세스 관리를 특징으로 하며, 2세대 BPM(S)는 다량의 트랜잭션 처리를 위한 절차적 자동화에 중점을 두고 있다. 3세대에 서는 비즈니스 프로세스의 유연한 자동화에 초점을 맞추고 있다. - 정보 시스템 관점에서 BPM(S)는 1980년대의 의사 교환이나 정보 공유 중심의 이메일이나 그룹웨어 등의 사무 자동화에 쓰이고, 1990년대에는 문서 흐름 자동화 중심의 워크플로우로 발전하여 이 시기에 워크플로우 개념 정립 및 상용 제품이 등장하였다. 워크플로우 관리 시스템WFMS은 '소프트웨어를 이용하여 컴퓨터로 표현된 업무 규칙에 의해 실행 순서가 제어 되는 업무 흐름을 정의하고 관리 및 실행하는 시스템' 이라고 정의한다. 용어 자체에 이미 프로세스 자동화의 개념이 내포되어 있어서 워크플로우 관리 시스템은 BPR 성공을 위한 핵심 정보 기술로서 중요한 역할을 하였다. 2000년대에는 협업 중심의 전략적 정보화라 할 수 있는 BPMS로 발전하고 있으므로 최근의 BPMS는 자동화Automation에서 협업Orchestration 으로 그 중심이 이동해가고 있다. - BPM가끔 '비즈니스 프로세스 자동화와 혼용됨은 특정 소프트웨어가 아닌 비즈니 스 프로세스를 간소화하고 효율성과 가치를 극대화하는 방법이다. 프로세스가 어떻게 작동하고 있는지, 개선 분야는 어디인지 파악하고, 솔루션을 처음부터 끝까지 구축하기 위한 방법을 상세하게 검토한다. BPM은 비즈 니스 프로세스의 인프라가 견고하다는 것을 확인하는 것이다. 반면 RPA는 인간처럼 프로세스를 조작하기 위해 설계되었기 때문에 좀 더 표면적인 레벨 (User Interface 같은)에 존재한다고 할 수 있다. 구현이 더 빠 르고 모든 소프트웨어에서 바로 사용할 수 있으며, 변화하는 세계에 적응 하도록 쉽게 변경하거나 업데이트가 가능하다. RPA와 BPM은 서로 상충되지 않는다. 서로 다른 구현 전략을 가지고 같은 목표를 달성하고자 하는 것이기 때문이다. 이전에 사람이 처리하던 빈도 높은 프로세스를 처리하기 위해 RPA를 사용하고 표면 수준의 수정에 의지하는 것이 아니라 프로세스 자체를 변환해야 하는 경우가 있는데 이럴 때는 BPM을 사용하는 것이 적당하다.
- 삼성SDS는 자체 개발한 인공지능 기능 업무자동화 솔루션 ‘브리티웍스Brity Works' 를 활용해 사내 1만 7,000여 개 업무를 자동화했다. 삼성SDS 관계자는 “지난 6개월간 업무에 자동화 솔루션을 적용한 결과, 20만 시간을 절감할 수 있었다”고 설명했다. 삼성SDS는 물류 사업에 브리티웍스를 적용했다. 이를 통해 수십 명의 인력이 각 지역별 항공사 · 선사의 3만여 개 사이트에 매일 접속해 화물 위 치 정보를 수집해 입력하던 단순 업무를 자동화했다. 또 시스템 관리 담당 자가 명령어 입력 결과 확인 메일 전송' 등 단순 반복하는 서버 점검 프로세스도 브리티웍스를 통해 자동화했다. 이 밖에 연 4,000여 건 이상 발생하는 구매 주문서의 발행 프로세스시스템 접속-계약번호 조회-정보 확인 결재를 자동 화하는 등 전체 임직원 80%가 참여해 회사 전 업무 영역을 혁신하고 있다. - LG CNS는 자체 개발한 RPA를 매출, 비용 정산작업, 송장 입력시스템, 인사 채용, 보험청구서 작성 분야 등에 이용토록 하고 있다. LG그룹의 제 조 관련 계열사 등 9곳과 외부업체 2곳 등에 RPA 솔루션을 공급했다. 이를 통해 단순 비용 정산작업을 할 때 시간을 아낄 수 있게 되었다. 특히 기업 구매 파트에서는 송장인보이스을 보내는 시간을 절약할 수 있었다. | LG CNS는 기존 RPA 태스크포스TF를 RPA 플랫폼팀으로 승격 개설하 고, 클라우드 기반 RPA 포털 서비스도 처음 선보였다. 재경이나 구매, 인사 관련 프로그램을 자신의 PC에 따로 설치할 필요 없이 담당자가 포털에 접 속해 RPA를 실행하고 여러 사람이 작업한 내용을 바로 확인 및 업데이트 할 수 있게 된 것이다. - 포스코 ICT는 2017년부터 자사와 그룹사의 재무·회계·노무 업무에 RPA를 구축해 운영 중이다. 이미 사업부서의 공과금 납부, 영수증 입력 등을 RPA가 처리하면서 관련 업무에 대한 소요 시간이 80% 이상 줄어들었다. 최근에는 자체 RPA 솔루션인 '에이웍스A.WORKS’ 개발을 완료하고 유 통·금융 분야로 진출할 계획을 갖고 있다. 2019년 8월 하나금융 산하 IT전 문 관계사인 하나금융티아이와 공동사업 추진을 위한 업무협약을 체결한 바 있다. - SK C&C는 회사 및 계열사 인사업무 파트와 AIA생명, 부동산 플랫폼 다방 등에 RPA가 가능한 서비스를 공급 중이다. SK C&C가 개발한 '에이브릴 HR 포 리크루트'는 입사 지원자의 자기소개서를 검증하는 솔루션이 다. 현재 SK C&C와 SK하이닉스가 쓰고 있다. 이 솔루션은 30명이 사흘 이상 검토했던 서류작업을 3~4시간 만에 끝낸다. AIA생명은 SK C&C의 도움으로 보험상품 불완전 판매 여부를 검증하는 데 활용하고 있다. - KT는 기업의 경비 처리를 더 쉽고 빠르게 처리할 수 있는 챗봇 기반의 전표를 대신 처리하는 전표 로봇전대리 솔루션을 자체 개발, 사내에 적용했 다. '전대리는 챗봇 기반의 RPA 프로그램으로, 자주 처리하는 전표 이력을 추천하고, 시스템에 접속하지 않아도 메신저 채팅을 통해 몇 번의 클릭만 으로 전표에 필요한 계정, 적요 등을 선택해 모든 전표 처리 업무를 할 수 있도록 만든 솔루션이다. 그동안 경비 처리를 위해서는 전표가 발생할 때 마다 사용자가 시스템에 직접 접속해 처리해야 했다. 또한 시스템 내에서 전표 처리에 필요한 계정, 적요 등을 모두 수작업으로 입력해야만 전표 처 리가 가능해 업무 처리 시간이 오래 걸렸다. KT는 '전대리'를 적용하여 기 존 대비 최대 90% 이상의 업무 효율성을 향상시킬 수 있을 것으로 기대하 고 있다. 또한 현장 근무 등으로 PC 접속이 어려운 영업 직원을 위한 '전대 리' 모바일 버전도 출시 예정이다. KT는 '전대리 외에도 '자료 추출을 대 신하는 자료제공 로봇추대리'을 출시한다. '추대리' 역시 챗봇 기반으로 전사 적 자원 관리ERP 경영 자료를 받아볼 수 있어 쉽고 편리한 업무 처리 환경을 제공할 예정이다.
- 기업들은 보통 일반적으로 로보틱 운영 센터ROC, Robotic Operation Center의 형태로 팀을 구성해 조직에 가장 큰 영향을 미치는 프로세스들을 처리 한다. 이것이 중앙 집중적인 탑다운 접근법이며 네 단계가 있다. 1. 자동화가 가능한 영역을 파악한다. (히트맵', 프로세스 디스커버리 및 플래닝 소프트웨어 기능을 활용한다.) 2. 가장 높은 ROI을 달성할 수 있도록 각 업무를 진행 시간과 빈도에 따라 순위를 매긴다. 3. 이를 통해 자동화해야 하는 핵심 업무를 정하고, 기대하는 결과를 정한다. 4. 자동화를 한 뒤 문제가 해결되었는지 평가한다. 만약 문제가 해결되지 않았다면, 가장 효과적인 사람과 로봇의 업무 조합을 찾아본다. 이 네 단계를 통해 기업의 자동화팀은 주요 업무 프로세스를 살펴보고 어떤 업무가 가장 많이 시간이 걸리고 업무량이 많은지 찾아내야 한다. 산 업 및 도메인별 히트맵, 프로세스 마이닝 기술과 그 외 플래닝 도구를 활 용할 수도 있다. 현재 국내에 가장 활발하게 도입되고 있는 방법이다. 중앙 관리와 대용량처리가 쉬운 반면 구축비용과 구축시간이 많이 드는 단점이 있다. - '바텀업 접근을 선택했다면, 직원들은 자신의 일상적인 프로세스 중 어떤 것이 자동화될 수 있는지 탐색하도록 하는 체제 모형을 마련한다. 해당 작업들이 개개인에게는 비효율적이거나 비용이 많이 드는 것처럼 보이지 않 을지라도, 조직 차원에서 보았을 때에는 반복된 업무에 상당한 시간이 낭비되고 있을 수 있다.
- RPA COE의 구성원은 누구인가? * RPA 후원자: 전반적인 로봇 공학 전략을 책임지는 역할로서, CoE는 기업전체의 환경에 걸맞은 RPA 후원자를 지정해야 한다. * COE 리드: CoE 활동, 성과 보고 및 운영 리드를 담당한다. * RPA 프로젝트 관리자: 로봇 프로젝트가 CoE 전략에 따라 제공되도록 하여 성공적인 구현, 적시에 정해진 예산 내에서 이익을 얻을 수 있도록 한다. * RPA 챔피언: 조직 전체의 자동화 채택 프로세스를 추진한다. * RPA 및 CoE 비즈니스 분석가: 자동화에 사용되는 프로세스 정의 및 맵을 작성하는 주제 전문가로서, 상황을 식별하고 잠재적 이점과 필요한 자원 에 대한 자세한 분석을 제공한다. * RPA 솔루션 설계자: RPA 인프라를 처음부터 끝까지 감독하며 CoE 설정 의 개발 및 구현 단계를 모두 지원한다. 자동화 CoE의 세부 설계 및 라이 선스 요구를 담당한다. * CoE 개발자: CoE 자동화 워크플로우의 기술 설계, 개발 및 테스트를 담당한다. * 인프라 엔지니어: 자동화 CoE의 배포 및 향후 운영에 관련된 팀을 지원한다. 주로 문제 해결 및 서버 설치를 위한 인프라 지원을 제공한다. * Controller & Supervisor: CoE 모니터링, 스케줄링 및 지원을 담당하며 업무가 평소와 같이 진행되도록 한다. - 대부분의 RPA 공급 업체는 도구에 인공지능 및 기계 학습 기능을 내장시킨다. 이러한 딥 러닝 기능에는 컴퓨터 비전 또는 자연어 처리"가 포함된다. 이를 통해 봇은 워크플로우 기록 중 표시되는 단어와 아이콘을 이해하고 프로세스를 정확하게 수행할 수 있다. 비즈니스 응용 프로그램과의 통합에서 회사는 종종 RPA 도구를 구현하여 CRM, ERP 시스템 및 회계 소프트웨어를 비롯한 다른 유형의 비즈니스 응용 프로그램 내에서 작업을 수행한다. 이러한 시스템과 함께 통합하고 작동하는 기능은 RPA 소프트웨어의 중요한 기능이다. - Mavenick 컨설팅사가 제시한 RPA 3단계 성숙모델을 소개한다. 지능형 자동화가 물리적 인프라, 비즈니스 관리 소프트웨어, 운영관리, 분석, 프로세 스 자동화, 인공지능 및 정보 보안 전반에 걸쳐 이루어지는 자동화 중심의 기업을 위한 단계이다. 기업이 마지막 단계에 도달하면, 인지 및 데이터 지 향 모델로 전환하여 RPA의 모든 이점을 누릴 수 있다. 1단계: 임시(Ad-hoc) 단계 : 대부분의 기업은 사례별로 RPA를 채택하기 시작한다. 이 단계에서는 전체적인 자동화 전략이 아직 마련되어 있지 않으며, 모든 도구 평가 및 프 로세스 선택 기준은 개별 팀장이 주도한다. 임시 단계에서 조직은 다음과 같은 측면에 대해 주의를 기울여야 한다. * 간단한 과정부터 시작하는 것이 중요하다. * 복잡한 자동화를 다루기 전에 팀에서 교육해야 할 몇 가지 측면이 있다. (예: 변경 관리, 심층 기술 및 프로세스 엔지니어링 기술, 운영 모델, CoE, 거버넌스, 비즈니스 모델 및 실행 프레임워크)) 임시 단계는 요구 사항 수집을 위한 중요한 시간이다. 기업은 RPA가 어떻게 기존 기술 환경에 가장 적합하게 구축할 수 있는지를 신중하게 평 가하고 장기적인 채택 목표도 제시해야 한다. 2단계: 채택 단계 : 수집된 요구사항과 원하는 장기 RPA 채택 목표에 기초하여 CoE가 설정되며, 전사적으로 자동화를 확장하기 위한 진화 모델을 이용할 수 있는 명확한 자동화 채택 전략이 정의된다. 기업이 RPA 채택 목표를 명확히 제시할수록 채택은 보다 효과적으로 조정될 수 있다. 특정 RPA 플랫폼의 선택은 공식적으로 정의된 평가 기준에 기초해야 하며, 기준 자체는 개별 부서의 필요와 그 이상으로 확장되어야 한다. 이는 무엇보다도 변경 관리, 엔드투엔드 비즈니스 프로세스 관리, 적극적인 목 표 및 진행 과정 추적 등을 감안해야 가능하다. 임시 단계에서 채택 단계로 전환하는 가장 중요한 요소는 전체적 기준 과 디지털화 및 자동화 채택을 위한 잘 정의된 전략을 사용한 CoE 설정이 다. 전략은 변경 관리, 심층적인 기술 및 프로세스 엔지니어링 기술 훈련, 기술 관리 및 인력 배치, 운영 모델, 거버넌스, 비즈니스 모델 및 실행 프레임워크를 포함해야 한다. 3단계: 적응 단계 : 기업이 적응 단계에 진입할 때, 그것은 자동화 중심 기업을 창출하기 위한 3단계 성숙도 모델의 종료 상태에 도달했고, 지속적인 개선과 과정 수정 메커니즘을 구현했다는 것을 의미한다. 이 단계에서 기업은 자동화 전략의 다양한 부분에서 성숙하고, 프로 세스 엔지니어링 기술뿐만 아니라 심층적이고 광범위한 자동화 기술을 구 축했으며, 기술의 광범위한 가용성으로 인해 이제 분산형 실행의 허브와 스포크 모델'을 채택할 수 있으며, 입력 전반에 걸쳐 자동화 기능이 구축되 었다. 기업은 규칙 기반 또는 MLMachine Learning/AI 기반 자동화를 채택하여 모든 비즈니스 기반의 가상 인력의 일관성과 정렬을 보장하는 포괄적인 프레임워크를 가지게 된다. 둘 사이의 기본 관계에 대해서는 약간의 의견 차이가 있다. 머신 러닝이 AI 분야라는 데는 거의 모든 사람들이 동의하지만 RPA와 AI에 대해서는 동일한 합의가 존재하지 않는다. 이에 대한 합의가 이루어지지 않은 이유 중 하나는 RPA 기술과 지금까지의 사용 사례가 “지능형”이 아니기 때문이다. RPA는 사람의 노력이 필요했던 규칙 기반의 작업을 처리하는 데 큰 도움 이 될 수는 있다. 그러나 아직 사람의 심층 신경망처럼 진행되지는 않는다. 인간의 판단과 행동을 강화하고 모방하는 AI 기술은 규칙 기반의 인간 행동을 복제하는 RPA 기술을 보완한다. '화이트칼라' 라는 지식 기반 근로자와 '블루칼라 라는 서비스 기반 근로자가 조직의 생산성을 높이기 위한 엔진으로서 협력하는 것처럼, RPA와 AI 두 기술은 서로를 보완하며 작동 이러한 3단계 성숙도 모델은 연속체로 생각되어야 한다. 단계들은 별개의 것이 아니라 겹치는 것이다. 기업에서 일부 측면은 채택 단계에 있는 반면 다른 측면은 여전히 애드혹Ad-Hoc일 가능성도 있다. 행동 계획을 결정 하기 위해서는 현재 상태와 목표 상태에 대한 평가가 중요하다.이러한 3단계 성숙도 모델은 연속체로 생각되어야 한다. 단계들은 별개의 것이 아니라 겹치는 것이다. 기업에서 일부 측면은 채택 단계에 있는 반면 다른 측면은 여전히 애드혹Ad-Hoc일 가능성도 있다. 행동 계획을 결정 하기 위해서는 현재 상태와 목표 상태에 대한 평가가 중요하다. - RPA는 작업을 자동화한다. 현재 수준의 RPA는 전체 종단 간 프로세 스를 자동화하기는 아직 어려운 것이 사실이다. 사용자의 요구를 충족하기 위한 노력으로 인해 개발되는 두 가지 특정 기술이 있다. 인지적인 기능의 통합에 대한 두 가지 예를 살펴보자. * 인지 캡처Cognitive Capture: 인지 캡처는 옴니 채널(예: 웹 양식, 종이 문서, 이메일)을 통해 데이터를 수집한 다음 기본 AI/인지 알고리즘을 사용하 여 비정형데이터를 정형데이터 형식으로 변환하여 RPA가 작업을 자동 화한다. * 프로세스 오케스트레이션: 프로세스 오케스트레이션은 워크플로우 자동 화에 엄격하고 규율을 추가한다. RPA에 의해 자동화된 작업은 일반적으로 워크플로우의 일부이기 때문에 이 부분이 필요하다. 프로세스 오케스트레이션은 모든 예외를 처리하고 전통적인 동적 사례 관리를 수행하며 RPA 디지털 작업자와 실제 직원 간의 협업 및 업무 전달을 관리함으로써 RPA를 지원한다. 예를 들어, RPA 프로세스를 구축하는 동안 비정형 데이터의 사용에 영향을 줄 수 있는 시나리오를 생각해볼 수 있다. * 필요한 문서에서 컨텍스트에 따라 규정된 비정형 정보를 추출해야 하는 경우 * 특정 고객 분류에 따라 문서를 분류하고 그에 따라 행동해야 하는 경우 * 정보를 추출하기 전에 추론을 적용해야 할 때 * 프로세스에서 사용하기 위해 추출한 데이터에 연결된 관계도 검색해야 하는 경우 위의 모든 시나리오에서 AI와 RPA 간의 협업은 비정형 정보의 사용을 가속화하여 지능형 자동화의 범위를 확장하고 향상시킨다. AI는 모든 관련 데이터를 RPA에서 즉시 유용하고 실행 가능하게 만든다. 다른 많은 기술들과 마찬가지로 RPA도 AI와 손잡고 스마트 운영을 추 진하기 위해 진화할 수 있다. 이 여정은 유인Attened RPA에서 무인Unattened RPA로 그리고 인지 RPA로 시작하여 자율적인 RPA로 진행한다. - 모든 ERP 시스템 응용 프로그램에서 RPA를 사용하여 ERP 프로세스를 자동화하면 비용 절감, 100%의 정확도, 빠른 처리 속도와 함께 향상 된 규정 준수, 제어 및 감사 기능과 같은 명확한 최종 이점을 얻을 수 있다. RPA는 비즈니스 전반에서 ERP 프로세스를 개선할 수 있다. * 인적 자원: 채용에서 온보딩, 경력 개발 등 직원 라이프 사이클 프로세스의 모든 측면을 자동화 * CRM고객 관계 관리: 자동화를 통해 고객 경험CX을 향상시켜 콜센터 효율성을 높이고 고객 만족도를 향상 * 공급망: 인건비를 낮추고 회사의 경쟁력을 향상 * 제조: 재고 관리, 조달 및 주문 처리를 개선하고 제조 생산을 관리 및 최적화하기 위한 데이터를 제공 * 재무 및 회계: 관련 프로세스를 자동화하고 인적 오류 요인을 제거하며, 보고 요구 사항에 대한 RPA 사전 설정 준수를 향상 * 비즈니스 인텔리전스: RPA는 실시간 프로세스 수준의 데이터 분석 기능을 제공하여 민첩성을 향상시키고 중요한 의사 결정을 향상
- 자바 프로그래밍 언어는 제임스 고슬링 James Gosling, 마이크 셰리든Mike Sheridan, 패트릭 노튼 Patrick Naughton에 의해 1990년대에 썬 마이크로시스템즈Sun Microsystems에서 만들어졌다. 자바는 부분적으로는 당시 널리 쓰이던 C 프로그래밍 언어를 본떠 만들어졌다. C에는 메모리 자동관리가 없었고, 메모리 관리 오류는 당시 프로그래머에게 자주 두통을 일으키게 하는 오류였다. 자바는 언어 설계를 통해 이런 종류의 오류(메모리 관리 관련 오류)를 없앴다. 자바는 메모리 관리를 프로그래머가 볼 수 없게 감췄다. 이것이 자바가 초보자에게 좋은 언어가 된 이유 중 하나다. 하지만 좋은 프로그래머와 좋은 프로그램을 탄생시키려면 좋은 프로그래밍 언어 이상의 것이 필요하다. 그리고 자바로 인해, 디버깅하기 더 어려운 새로운 버그 종류가 생겨났음이 드러 났다. 이런 버그 중에는 감춰진 메모리 관리 시스템으로 인해 생긴 형편없는 성능이 포함된다. 여러분도 이 책을 통해 알게 되겠지만, 메모리를 이해하는 것은 프로그래머에게 핵심 기술에 속 한다. 처음 프로그램을 배울 때는 이후에 좀처럼 고치기 어려운 전형적인 습관이 생기기 쉽다. 소위 '안전한' 환경에서 자란 아이들이 그런 환경에서 자라지 않은 아이들보다 나중에 실제 삶 에서 더 큰 부상을 입을 확률이 높다는 연구 결과도 있다. 이는 아마도 이런 아이들이 추락하는 아픔이 뭔지 배우지 않았기 때문일 것이다. 처음 시작하는 프로그래머들에게는 안전한 프로그래밍 환경이 덜 두려울 테지만, 그들 또한 나중에 만나게 될 실제 세계를 미리 대비할 필요도 있다. - 기술과 그 기술을 발명한 사람에 대해 배우기 위해 시간을 내보라. 이 책에서 언급한 사람들은 대부분 흥미로운 문제를 최소한 한 가지 이상 해결한 사람이며, 이들이 세계를 어떻게 인식했고 문제를 해결하기 위해 어떤 접근을 했는지 배워볼 만한 가치가 있다. 닐 스티븐슨Neal Stephenson 의 2008년 소설 『Anathem』에 좋은 대화가 나온다. “우리의 적은 원자폭탄이 가득 들어 있는 외계 우주선이다. 우리한테는 각도기가 있다." "좋아. 집에 가서 자와 끈을 찾아오지.” 이들이 기초적인 것에 얼마나 의지하는지 명심하라. 이들의 대화는 '위키피디아에서 뭘 할지 찾아보자'나 '스택 오버플로 Stack Overflow에 질문을 올려보자', '깃허브GitHub에서 패키지를 찾아보 자'가 아니었다. 어느 누구도 해결하지 못한 문제를 푸는 방법을 배우는 것이 가장 중요한 기술이다. - 덧셈 결과가 우리가 사용할 비트의 개수로 표현할 수 있는 범위를 벗어나면 어떻게 해야 할까? 이런 경우 오버플로가 발생한다. 오버플로란 말은 MSB에서 올림이 발생했다는 뜻이다. 예를 들어, 4비트 덧셈에서 1001 (9)과 1000(8)을 더한 결과는 10001(1710)이다. 하지만 MSB 왼 쪽에 사용할 수 있는 비트가 없기 때문에 결과가 0001(10)이 된다. 나중에 자세히 보겠지만 컴 퓨터에는 조건 코드(또는 상태 코드) 레지스터condition code register라는 것이 있어서 몇 가지 이상한 정보를 담아둔다. 이런 정보 중에는 오버플로 비트가 있고, 이 비트에는 MSB에서 발생한 올림값이 들어간다. 이 비트값을 보면 오버플로가 발생했는지 알 수 있다. 여러분은 한 수를 다른 수에서 빼는 것은 한 수에 다른 수의 음수를 더하는 것과 같다는 사실을 알고 있을 것이다. 다음 절에서는 음수를 표현하는 방법을 살펴본다. MSB 위쪽에서 1을 빌려오는 경우를 언더플로 underflow라고 부른다. 이에 해당하는 조건 코드도 컴퓨터에 들어 있다. - 프로시저, 서브루틴, 함수 엔지니어들은 게으름에서 비롯된 이상한 습성을 가진 경우가 있다. 정말 하기 싫은 일이 있으 면 엔지니어들은 자신을 대신해 이 일을 해줄 무언가를 만든다. 심지어 이런 것을 만드는 데 걸 리는 노력이 원래 하기 싫은 일을 하는 데 드는 노력보다 훨씬 많이 들어도 굳이 이런 짓을 하고 는 한다. 프로그래머들이 피하고 싶어 하는 일 중 하나는 똑같은 코드를 두 번 이상 작성하는 것 이다. 이렇게 코드 반복을 피하는 데는 게으름 외에도 여러 가지 충분한 이유가 있다. 예를 들어 중복된 코드를 줄이면 코드가 메모리를 덜 차지하고, 코드에 버그가 있는 경우 여러 군데를 반 복해 고치지 않고 한 군데만 고치면 된다는 장점이 있다. 함수function(또는 프로시저procedure, 서브루틴subroutine)는 코드를 재사용reuse하는 주요 수단이다. - 여러 프로그램을 동시에 실행하려면 어떻게 해야 할까? 우선, 각 프로그램을 서로 전환시켜 줄 수 있는 일종의 관리자 프로그램이 필요하다. 이런 프로그램을 운영체제 또는 운영체제 커널kernel('중심' 이라는 뜻)이라고 부른다. 우리는 OS와 OS가 관리하는 프로그램을 구분하기 위 해 OS를 시스템 프로그램이라고 부르고 다른 모든 프로그램을 사용자user 프로그램이나 프로세스 process라고 부른다. - 프로그램의 각 명령어에 대한 비트 조합을 하나하나 알아내려면 아주 고통스럽다. 초기 컴퓨터 프로그래머들은 이런 작업에 신물이 나서 프로그램을 작성하는 더 나은 방법을 고안해냈다. 이 방법이 바로 어셈블리 언어assembly language다. 어셈블리 언어는 다음과 같은 놀라운 일을 해준다. 어셈블리 언어를 쓰면 프로그래머가 모는 비 트 조합을 외우지 않고 이해하기 쉬운 니모닉mnemonics을 통해 명령어를 쓸 수 있다. 어셈블리 언어에서는 주소에 이름, 즉 레이블을 붙일 수 있다. 그리고 코드에 주석comment을 달아서 다른 사람들이 프로그램을 더 쉽게 읽고 이해하도록 도와줄 수 있다. 어셈블리 언어로 작성된 코드를 읽어서 동등한 기계어 코드machine code를 생성해주는 프로그램을 어셈블러assembler라고 부른다. 이런 변환 과정에서 어셈블러는 레이블이나 심볼symbol의 값을 결정해 채워 넣어준다. 코드에서 명령어 위치가 바뀌면 생길 수 있는 바보 같은 오류를 예방해주기 때문에 심볼의 값을 결정해 넣어주는 기능은 아주 유용하다. - 초창기 프로그래머들은 불가능한 일을 해야만 했다. 맨 처음 컴퓨터가 만들어졌을 때는 어셈블러도 없었다. 그래서 개발자들은 어려운 방식, 즉 직접 손으로 모든 비트를 알아내는 방법으로 최초의 어셈블러를 작성해야 했다. 첫 번째 어셈블러는 아주 원시적이었지만 제대로 작동하는 어셈블러가 생겼기 때문에 이 어셈블러에서 작동하는 어셈블리 언어를 사용해 더 나은(더 많은 의사명령어와 기능을 제공하는) 어셈블러를 어셈블리 언어로 작성할 수 있었고, 개선된 의사명령 어와 기능을 활용하는 어셈블리 언어로 다시 더 많은 기능을 제공하는 어셈블러를 만들 수 있었으며, 이런 식의 개선을 계속할 수 있었다 - 부트스트랩bootstrap 이라는 말이 있다. 종종 이 말을 부트boot라고 줄여서 부르기도 한다. 컴퓨터를 부팅하는 과정은 롬 등에 들어 있는 작은 프로그램을 메모리로 읽어오는 것부터 시작한다. 이 프로그램은 필요한 초기화를 진행한 후 더 큰 프로그램을 (보통은 하드 디스크, USB 등 대용량 저장장치에서) 읽어오고, 이 프로그램은 더 큰 운영체제 등을 불러올 수 있다. 초기 컴 퓨터에서는 사람이 직접 전면 패널의 스위치를 사용해 최초 부트스트랩 프로그램을 입력해야만 했다. - 어셈블리 언어는 큰 도움이 됐지만 여러분도 알 수 있듯이 간단한 일을 할 때도 많은 작업이 필요하다. 좀 더 복잡한 작업을 묘사하기 위해 더 적은 단어를 사용할 수 있으면 정말 좋을 것 이다. 프레드 브룩스Fred Brooks는 1975년 애디슨 웨슬리Addison-Wesley에서 펴낸 『The MythicalMan-Month: Essays on Software Engineering』이라는 책(『맨먼스 미신』, 인사이트, 2015)에서 평균적으로 하루에 3~10줄의 문서화되고 디버깅이 이뤄진 코드를 작성한다고 주장했다. 따라서 코드 한 줄로 더 많은 일을 할 수 있다면 훨씬 더 많은 일을 완수할 수 있다. 고수준 언어high-level language 로 들어가자. 고수준 언어는 어셈블리 언어보다 더 높은 추상화 단계에서 작동한다. 고수준 언어의 소스 코드는 컴파일러 compiler라는 프로그램에 의해 실행된다. 컴 파일러는 소스 코드를 기계어로 번역, 즉 컴파일compile 해준다. 기계어 코드를 다른 말로 목적 코드 object code라고도 한다. 수천 가지 고수준 언어가 만들어졌다. 일부는 아주 일반적인 언어이고, 일부는 아주 구체적인 작업을 위한 언어다. 처음 생긴 고수준 언어 중에는 포트란FORTRAN이라는 언어가 있다. 포트란 이라는 이름은 '식변환기formula translator'를 줄인 말이다. 포트란을 사용하면 일차방정식 같은 수식을 계산할 수 있는 프로그램을 쉽게 작성할 수 있다. - 포트란이나 베이직 언어는 비구조적unstructured 언어라고 불린다. GOTO와 레이블을 조합할 때 아 무런 구조를 강요하지 않기 때문이다. 구조적structured 프로그래밍은 이런 잘못된 GOTO 사용으로 인해 발생할 수 있는 스파게티 코드 spaghetti code 문제를 해결하기 위해 개발됐다. 몇몇 언어는 구조적 프로그래밍 개념을 극단까지 수용했다. 예를 들어 파스칼은 GOTO를 완전히 없했고, 이로 인해 기초적인 구조적 프로그래밍을 가르칠 때만 유용한 프로그래밍 언어가 됐다. 공정하게 말하자면 어차피 파스칼은 교육용으로 설계된 언어였으므로 자신의 목적에 맞는 역할을 한 것이다. C는 켄 톰슨Ken Thompson 이 만든 B 언어를 계승한 언어인데, 원래 벨 전화 연구소의 데니스 리치Dennis Ritchie에 의해 만들어졌다. C 는 아주 실용적인 언어이며 가장 널리 쓰이는 프로그래밍 언어 중 하나가 됐다. 나중에 나온 언 어 중 상당수가 C의 요소를 그대로 가져다 썼으며, 그와 유사한 언어로는 C++, 자바, PHP, 파이 썬, 자바스크립트 등이 있다.